 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-modal Intermediate Feature Interaction AutoEncoder for Overall Survival Prediction of Esophageal Squamous Cell Cancer
Aug 23, 2024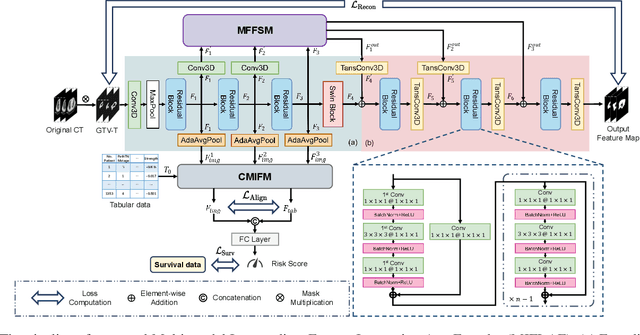
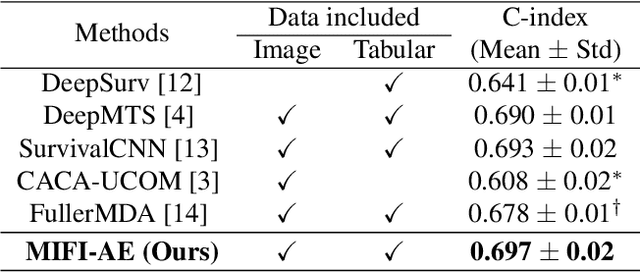
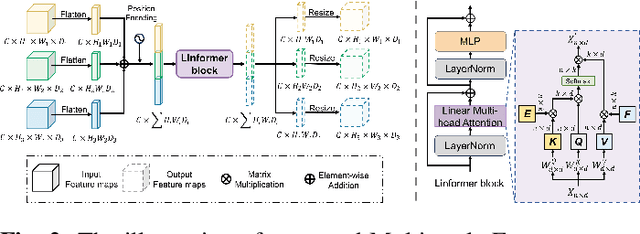
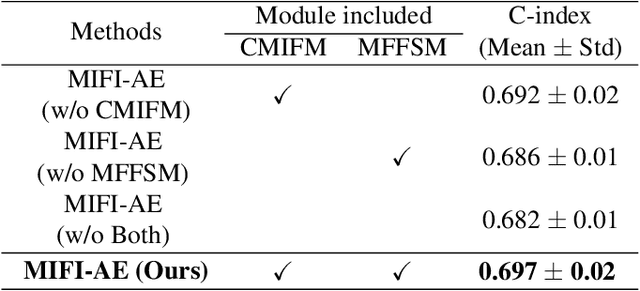
Survival prediction for esophageal squamous cell cancer (ESCC) is crucial for doctors to assess a patient's condition and tailor treatment plans. The application and development of multi-modal deep learning in this field have attracted attention in recent years. However, the prognostically relevant features between cross-modalities have not been further explored in previous studies, which could hinder the performance of the model. Furthermore, the inherent semantic gap between different modal feature representations is also ignored. In this work, we propose a novel autoencoder-based deep learning model to predict the overall survival of the ESCC. Two novel modules were designed for multi-modal prognosis-related feature reinforcement and modeling ability enhancement. In addition, a novel joint loss was proposed to make the multi-modal feature representations more aligned. Comparison and ablation experiments demonstrated that our model can achieve satisfactory results in terms of discriminative ability, risk stratification, and the effectiveness of the proposed modules.
Context-aware knowledge graph framework for traffic speed forecasting using graph neural network
Jul 25, 2024Human mobility is intricately influenced by urban contexts spatially and temporally, constituting essential domain knowledge in understanding traffic systems. While existing traffic forecasting models primarily rely on raw traffic data and advanced deep learning techniques, incorporating contextual information remains underexplored due to the lack of effective integration frameworks and the complexity of urban contexts. This study proposes a novel context-aware knowledge graph (CKG) framework to enhance traffic speed forecasting by effectively modeling spatial and temporal contexts. Employing a relation-dependent integration strategy, the framework generates context-aware representations from the spatial and temporal units of CKG to capture spatio-temporal dependencies of urban contexts. A CKG-GNN model, combining the CKG, dual-view multi-head self-attention (MHSA), and graph neural network (GNN), is then designed to predict traffic speed using these context-aware representations. Our experiments demonstrate that CKG's configuration significantly influences embedding performance, with ComplEx and KG2E emerging as optimal for embedding spatial and temporal units, respectively. The CKG-GNN model surpasses benchmark models, achieving an average MAE of $3.46\pm0.01$ and a MAPE of $14.76\pm0.09\%$ for traffic speed predictions from 10 to 120 minutes. The dual-view MHSA analysis reveals the crucial role of relation-dependent features from the context-based view and the model's ability to prioritize recent time slots in prediction from the sequence-based view. The CKG framework's model-agnostic nature suggests its potential applicability in various applications of intelligent transportation systems. Overall, this study underscores the importance of incorporating domain-specific contexts into traffic forecasting and merging context-aware knowledge graphs with neural networks to enhance accuracy.
MMFusion: Multi-modality Diffusion Model for Lymph Node Metastasis Diagnosis in Esophageal Cancer
May 16, 2024Esophageal cancer is one of the most common types of cancer worldwide and ranks sixth in cancer-related mortality. Accurate computer-assisted diagnosis of cancer progression can help physicians effectively customize personalized treatment plans. Currently, CT-based cancer diagnosis methods have received much attention for their comprehensive ability to examine patients' conditions. However, multi-modal based methods may likely introduce information redundancy, leading to underperformance. In addition, efficient and effective interactions between multi-modal representations need to be further explored, lacking insightful exploration of prognostic correlation in multi-modality features. In this work, we introduce a multi-modal heterogeneous graph-based conditional feature-guided diffusion model for lymph node metastasis diagnosis based on CT images as well as clinical measurements and radiomics data. To explore the intricate relationships between multi-modal features, we construct a heterogeneous graph. Following this, a conditional feature-guided diffusion approach is applied to eliminate information redundancy. Moreover, we propose a masked relational representation learning strategy, aiming to uncover the latent prognostic correlations and priorities of primary tumor and lymph node image representations. Various experimental results validate the effectiveness of our proposed method. The code is available at https://github.com/wuchengyu123/MMFusion.
Counterfactual Explanations for Deep Learning-Based Traffic Forecasting
May 01, 2024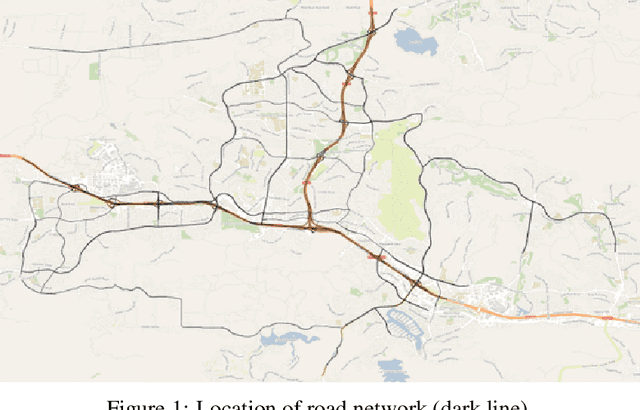

Deep learning models are widely used in traffic forecasting and have achieved state-of-the-art prediction accuracy. However, the black-box nature of those models makes the results difficult to interpret by users. This study aims to leverage an Explainable AI approach, counterfactual explanations, to enhance the explainability and usability of deep learning-based traffic forecasting models. Specifically, the goal is to elucidate relationships between various input contextual features and their corresponding predictions. We present a comprehensive framework that generates counterfactual explanations for traffic forecasting and provides usable insights through the proposed scenario-driven counterfactual explanations. The study first implements a deep learning model to predict traffic speed based on historical traffic data and contextual variables. Counterfactual explanations are then used to illuminate how alterations in these input variables affect predicted outcomes, thereby enhancing the transparency of the deep learning model. We investigated the impact of contextual features on traffic speed prediction under varying spatial and temporal conditions. The scenario-driven counterfactual explanations integrate two types of user-defined constraints, directional and weighting constraints, to tailor the search for counterfactual explanations to specific use cases. These tailored explanations benefit machine learning practitioners who aim to understand the model's learning mechanisms and domain experts who seek insights for real-world applications. The results showcase the effectiveness of counterfactual explanations in revealing traffic patterns learned by deep learning models, showing its potential for interpreting black-box deep learning models used for spatiotemporal predictions in general.
Context-aware multi-head self-attentional neural network model for next location prediction
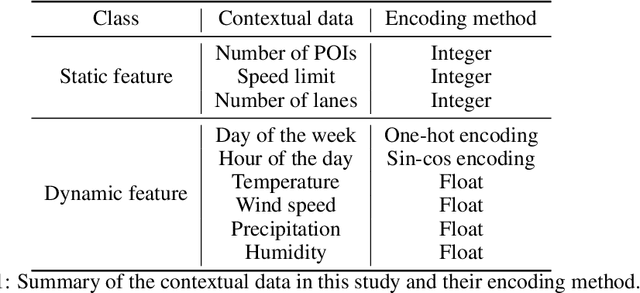
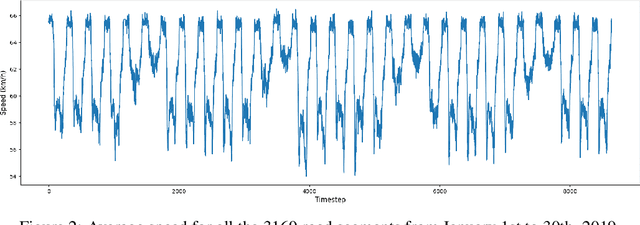
Dec 04, 2022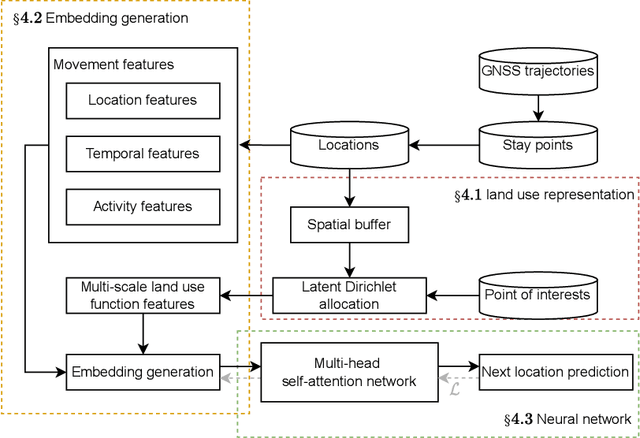
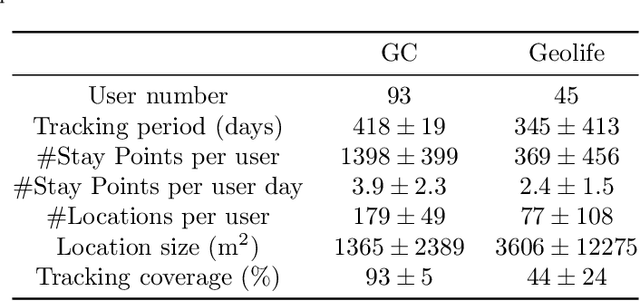
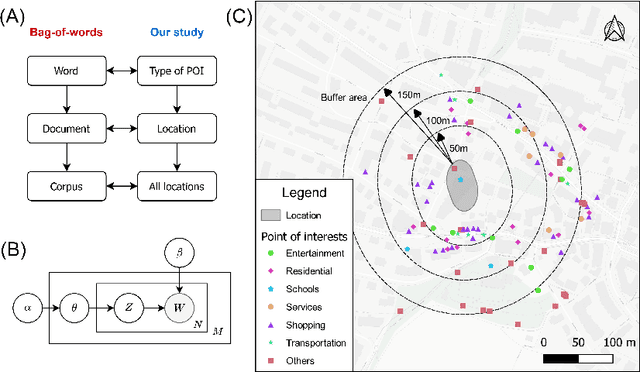
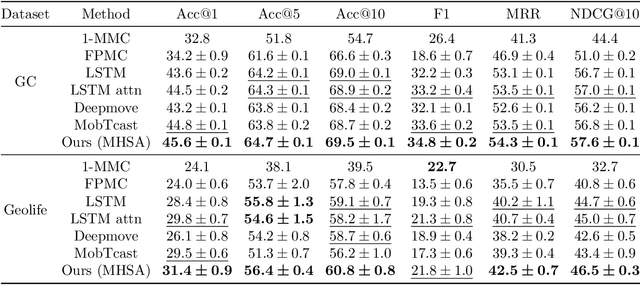
Accurate activity location prediction is a crucial component of many mobility applications and is particularly required to develop personalized, sustainable transportation systems. Despite the widespread adoption of deep learning models, next location prediction models lack a comprehensive discussion and integration of mobility-related spatio-temporal contexts. Here, we utilize a multi-head self-attentional (MHSA) neural network that learns location transition patterns from historical location visits, their visit time and activity duration, as well as their surrounding land use functions, to infer an individual's next location. Specifically, we adopt point-of-interest data and latent Dirichlet allocation for representing locations' land use contexts at multiple spatial scales, generate embedding vectors of the spatio-temporal features, and learn to predict the next location with an MHSA network. Through experiments on two large-scale GNSS tracking datasets, we demonstrate that the proposed model outperforms other state-of-the-art prediction models, and reveal the contribution of various spatio-temporal contexts to the model's performance. Moreover, we find that the model trained on population data achieves higher prediction performance with fewer parameters than individual-level models due to learning from collective movement patterns. We also reveal mobility conducted in the recent past and one week before has the largest influence on the current prediction, showing that learning from a subset of the historical mobility is sufficient to obtain an accurate location prediction result. We believe that the proposed model is vital for context-aware mobility prediction. The gained insights will help to understand location prediction models and promote their implementation for mobility applications.
Improved Heatmap-based Landmark Detection
Oct 12, 2021
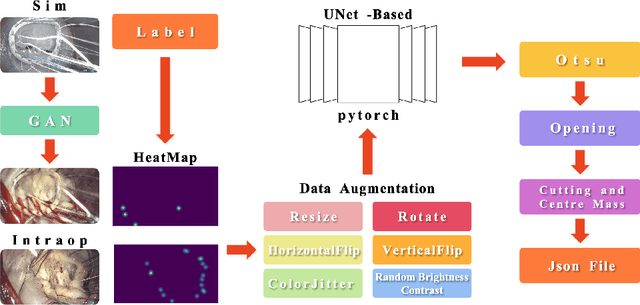
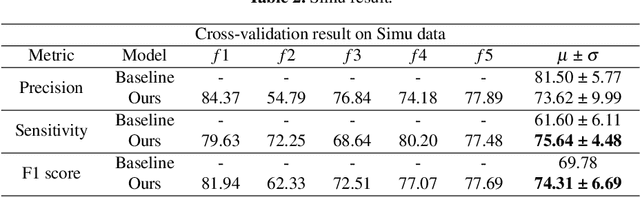
Mitral valve repair is a very difficult operation, often requiring experienced surgeons. The doctor will insert a prosthetic ring to aid in the restoration of heart function. The location of the prosthesis' sutures is critical. Obtaining and studying them during the procedure is a valuable learning experience for new surgeons. This paper proposes a landmark detection network for detecting sutures in endoscopic pictures, which solves the problem of a variable number of suture points in the images. Because there are two datasets, one from the simulated domain and the other from real intraoperative data, this work uses cycleGAN to interconvert the images from the two domains to obtain a larger dataset and a better score on real intraoperative data. This paper performed the tests using a simulated dataset of 2708 photos and a real dataset of 2376 images. The mean sensitivity on the simulated dataset is about 75.64% and the precision is about 73.62%. The mean sensitivity on the real dataset is about 50.23% and the precision is about 62.76%. The data is from the AdaptOR MICCAI Challenge 2021, which can be found at https://zenodo.org/record/4646979\#.YO1zLUxCQ2x.
Extracting urban impervious surface from GF-1 imagery using one-class classifiers
May 13, 2017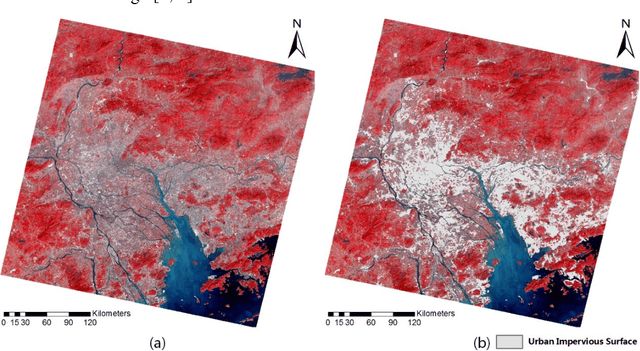
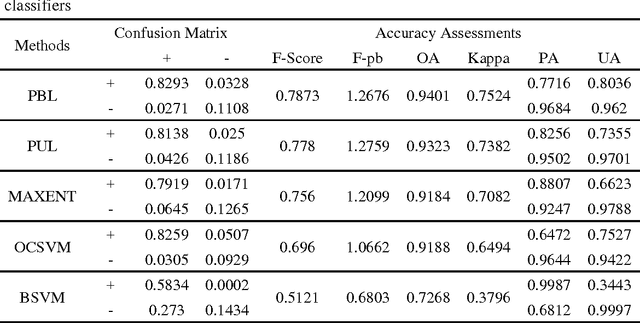
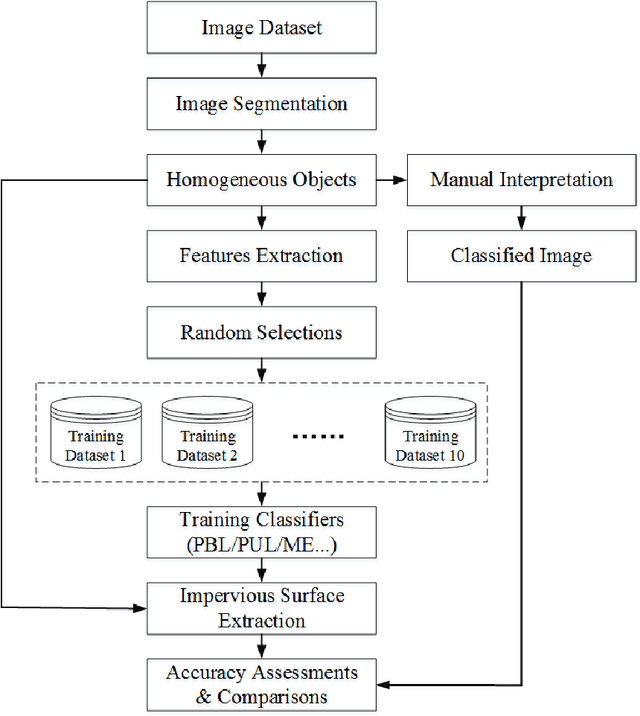
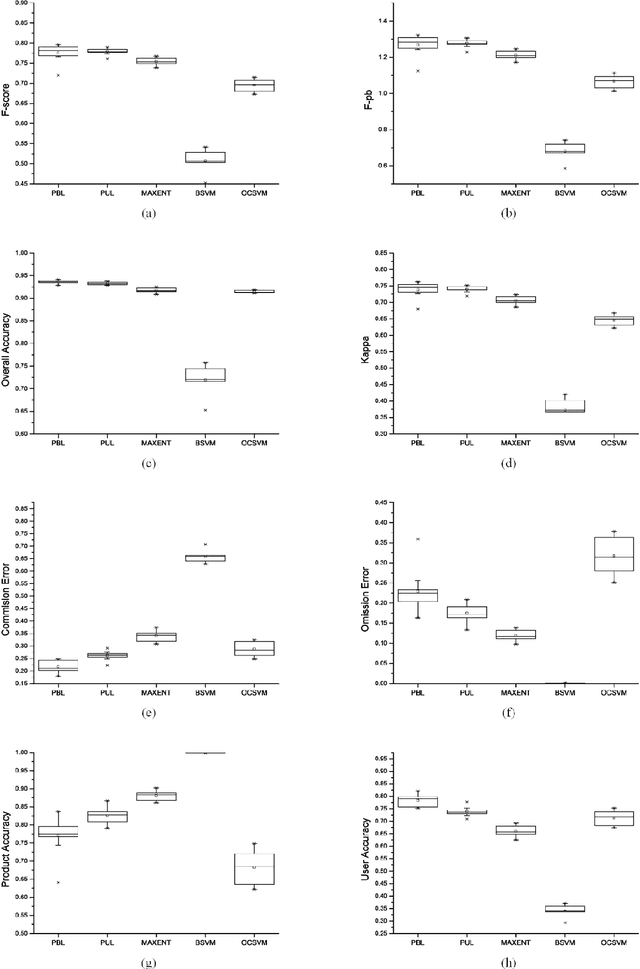
Impervious surface area is a direct consequence of the urbanization, which also plays an important role in urban planning and environmental management. With the rapidly technical development of remote sensing, monitoring urban impervious surface via high spatial resolution (HSR) images has attracted unprecedented attention recently. Traditional multi-classes models are inefficient for impervious surface extraction because it requires labeling all needed and unneeded classes that occur in the image exhaustively. Therefore, we need to find a reliable one-class model to classify one specific land cover type without labeling other classes. In this study, we investigate several one-class classifiers, such as Presence and Background Learning (PBL), Positive Unlabeled Learning (PUL), OCSVM, BSVM and MAXENT, to extract urban impervious surface area using high spatial resolution imagery of GF-1, China's new generation of high spatial remote sensing satellite, and evaluate the classification accuracy based on artificial interpretation results. Compared to traditional multi-classes classifiers (ANN and SVM), the experimental results indicate that PBL and PUL provide higher classification accuracy, which is similar to the accuracy provided by ANN model. Meanwhile, PBL and PUL outperforms OCSVM, BSVM, MAXENT and SVM models. Hence, the one-class classifiers only need a small set of specific samples to train models without losing predictive accuracy, which is supposed to gain more attention on urban impervious surface extraction or other one specific land cover type.