 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuroCLIP: A Multimodal Contrastive Learning Method for rTMS-treated Methamphetamine Addiction Analysis
Jul 27, 2025Methamphetamine dependence poses a significant global health challenge, yet its assessment and the evaluation of treatments like repetitive transcranial magnetic stimulation (rTMS) frequently depend on subjective self-reports, which may introduce uncertainties. While objective neuroimaging modalities such as electroencephalography (EEG) and functional near-infrared spectroscopy (fNIRS) offer alternatives, their individual limitations and the reliance on conventional, often hand-crafted, feature extraction can compromise the reliability of derived biomarkers. To overcome these limitations, we propose NeuroCLIP, a novel deep learning framework integrating simultaneously recorded EEG and fNIRS data through a progressive learning strategy. This approach offers a robust and trustworthy biomarker for methamphetamine addiction. Validation experiments show that NeuroCLIP significantly improves discriminative capabilities among the methamphetamine-dependent individuals and healthy controls compared to models using either EEG or only fNIRS alone. Furthermore, the proposed framework facilitates objective, brain-based evaluation of rTMS treatment efficacy, demonstrating measurable shifts in neural patterns towards healthy control profiles after treatment. Critically, we establish the trustworthiness of the multimodal data-driven biomarker by showing its strong correlation with psychometrically validated craving scores. These findings suggest that biomarker derived from EEG-fNIRS data via NeuroCLIP offers enhanced robustness and reliability over single-modality approaches, providing a valuable tool for addiction neuroscience research and potentially improving clinical assessments.
STS MICCAI 2023 Challenge: Grand challenge on 2D and 3D semi-supervised tooth segmentation
Jul 18, 2024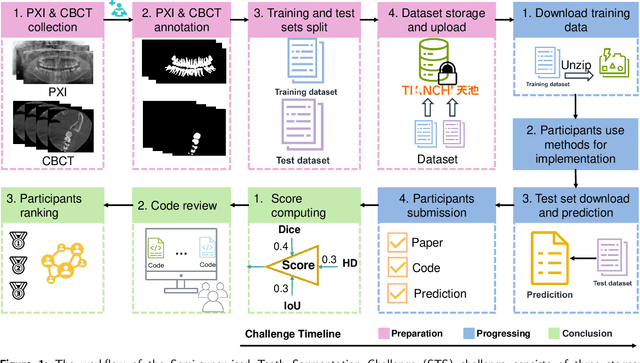
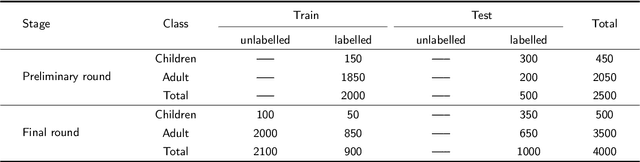

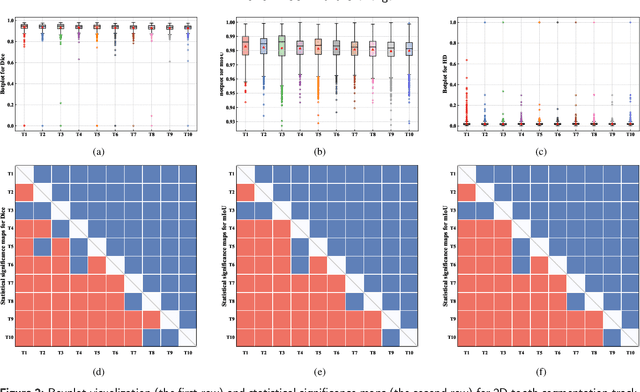
Computer-aided design (CAD) tools are increasingly popular in modern dental practice, particularly for treatment planning or comprehensive prognosis evaluation. In particular, the 2D panoramic X-ray image efficiently detects invisible caries, impacted teeth and supernumerary teeth in children, while the 3D dental cone beam computed tomography (CBCT) is widely used in orthodontics and endodontics due to its low radiation dose. However, there is no open-access 2D public dataset for children's teeth and no open 3D dental CBCT dataset, which limits the development of automatic algorithms for segmenting teeth and analyzing diseases. The Semi-supervised Teeth Segmentation (STS) Challenge, a pioneering event in tooth segmentation, was held as a part of the MICCAI 2023 ToothFairy Workshop on the Alibaba Tianchi platform. This challenge aims to investigate effective semi-supervised tooth segmentation algorithms to advance the field of dentistry. In this challenge, we provide two modalities including the 2D panoramic X-ray images and the 3D CBCT tooth volumes. In Task 1, the goal was to segment tooth regions in panoramic X-ray images of both adult and pediatric teeth. Task 2 involved segmenting tooth sections using CBCT volumes. Limited labelled images with mostly unlabelled ones were provided in this challenge prompt using semi-supervised algorithms for training. In the preliminary round, the challenge received registration and result submission by 434 teams, with 64 advancing to the final round. This paper summarizes the diverse methods employed by the top-ranking teams in the STS MICCAI 2023 Challenge.
MMFusion: Multi-modality Diffusion Model for Lymph Node Metastasis Diagnosis in Esophageal Cancer
May 16, 2024Esophageal cancer is one of the most common types of cancer worldwide and ranks sixth in cancer-related mortality. Accurate computer-assisted diagnosis of cancer progression can help physicians effectively customize personalized treatment plans. Currently, CT-based cancer diagnosis methods have received much attention for their comprehensive ability to examine patients' conditions. However, multi-modal based methods may likely introduce information redundancy, leading to underperformance. In addition, efficient and effective interactions between multi-modal representations need to be further explored, lacking insightful exploration of prognostic correlation in multi-modality features. In this work, we introduce a multi-modal heterogeneous graph-based conditional feature-guided diffusion model for lymph node metastasis diagnosis based on CT images as well as clinical measurements and radiomics data. To explore the intricate relationships between multi-modal features, we construct a heterogeneous graph. Following this, a conditional feature-guided diffusion approach is applied to eliminate information redundancy. Moreover, we propose a masked relational representation learning strategy, aiming to uncover the latent prognostic correlations and priorities of primary tumor and lymph node image representations. Various experimental results validate the effectiveness of our proposed method. The code is available at https://github.com/wuchengyu123/MMFusion.
ZS-SRT: An Efficient Zero-Shot Super-Resolution Training Method for Neural Radiance Fields
Dec 19, 2023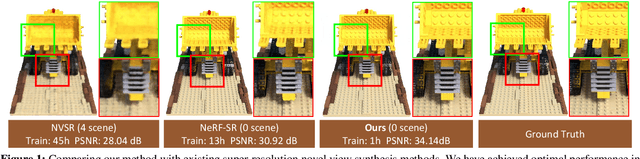
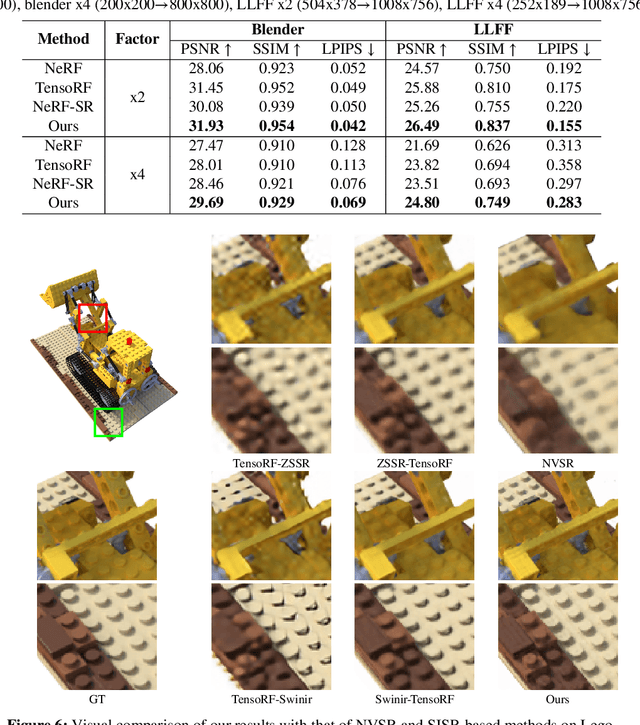
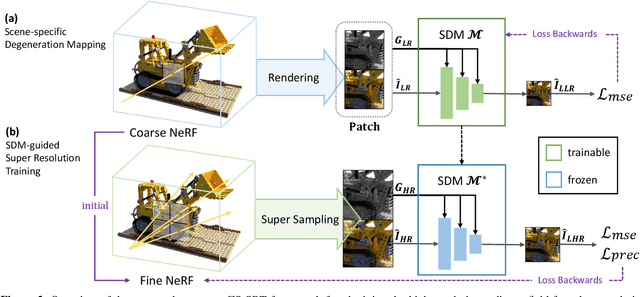
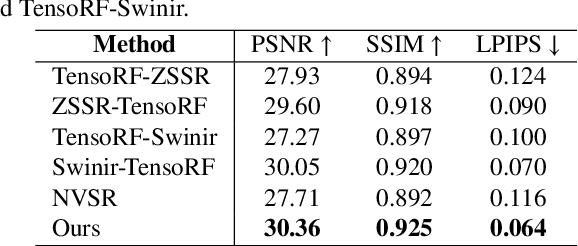
Neural Radiance Fields (NeRF) have achieved great success in the task of synthesizing novel views that preserve the same resolution as the training views. However, it is challenging for NeRF to synthesize high-quality high-resolution novel views with low-resolution training data. To solve this problem, we propose a zero-shot super-resolution training framework for NeRF. This framework aims to guide the NeRF model to synthesize high-resolution novel views via single-scene internal learning rather than requiring any external high-resolution training data. Our approach consists of two stages. First, we learn a scene-specific degradation mapping by performing internal learning on a pretrained low-resolution coarse NeRF. Second, we optimize a super-resolution fine NeRF by conducting inverse rendering with our mapping function so as to backpropagate the gradients from low-resolution 2D space into the super-resolution 3D sampling space. Then, we further introduce a temporal ensemble strategy in the inference phase to compensate for the scene estimation errors. Our method is featured on two points: (1) it does not consume high-resolution views or additional scene data to train super-resolution NeRF; (2) it can speed up the training process by adopting a coarse-to-fine strategy. By conducting extensive experiments on public datasets, we have qualitatively and quantitatively demonstrated the effectiveness of our method.
FDNet: Feature Decoupled Segmentation Network for Tooth CBCT Image
Nov 11, 2023Precise Tooth Cone Beam Computed Tomography (CBCT) image segmentation is crucial for orthodontic treatment planning. In this paper, we propose FDNet, a Feature Decoupled Segmentation Network, to excel in the face of the variable dental conditions encountered in CBCT scans, such as complex artifacts and indistinct tooth boundaries. The Low-Frequency Wavelet Transform (LF-Wavelet) is employed to enrich the semantic content by emphasizing the global structural integrity of the teeth, while the SAM encoder is leveraged to refine the boundary delineation, thus improving the contrast between adjacent dental structures. By integrating these dual aspects, FDNet adeptly addresses the semantic gap, providing a detailed and accurate segmentation. The framework's effectiveness is validated through rigorous benchmarks, achieving the top Dice and IoU scores of 85.28% and 75.23%, respectively. This innovative decoupling of semantic and boundary features capitalizes on the unique strengths of each element to significantly elevate the quality of segmentation performance.