 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Latent Space: Foundation, Evolution, Mechanism, Ability, and Outlook
Apr 02, 2026Latent space is rapidly emerging as a native substrate for language-based models. While modern systems are still commonly understood through explicit token-level generation, an increasing body of work shows that many critical internal processes are more naturally carried out in continuous latent space than in human-readable verbal traces. This shift is driven by the structural limitations of explicit-space computation, including linguistic redundancy, discretization bottlenecks, sequential inefficiency, and semantic loss. This survey aims to provide a unified and up-to-date landscape of latent space in language-based models. We organize the survey into five sequential perspectives: Foundation, Evolution, Mechanism, Ability, and Outlook. We begin by delineating the scope of latent space, distinguishing it from explicit or verbal space and from the latent spaces commonly studied in generative visual models. We then trace the field's evolution from early exploratory efforts to the current large-scale expansion. To organize the technical landscape, we examine existing work through the complementary lenses of mechanism and ability. From the perspective of Mechanism, we identify four major lines of development: Architecture, Representation, Computation, and Optimization. From the perspective of Ability, we show how latent space supports a broad capability spectrum spanning Reasoning, Planning, Modeling, Perception, Memory, Collaboration, and Embodiment. Beyond consolidation, we discuss the key open challenges, and outline promising directions for future research. We hope this survey serves not only as a reference for existing work, but also as a foundation for understanding latent space as a general computational and systems paradigm for next-generation intelligence.
Decoupling Stability and Plasticity for Multi-Modal Test-Time Adaptation
Feb 28, 2026Adapting pretrained multi-modal models to evolving test-time distributions, known as multi-modal test-time adaptation, presents a significant challenge. Existing methods frequently encounter negative transfer in the unbiased modality and catastrophic forgetting in the biased modality. To address these challenges, we propose Decoupling Adaptation for Stability and Plasticity (DASP), a novel diagnose-then-mitigate framework. Our analysis reveals a critical discrepancy within the unified latent space: the biased modality exhibits substantially higher interdimensional redundancy (i.e., strong correlations across feature dimensions) compared to the unbiased modality. Leveraging this insight, DASP identifies the biased modality and implements an asymmetric adaptation strategy. This strategy employs a decoupled architecture where each modality-specific adapter is divided into stable and plastic components. The asymmetric mechanism works as follows: for the biased modality, which requires plasticity, the plastic component is activated and updated to capture domain-specific information, while the stable component remains fixed. Conversely, for the unbiased modality, which requires stability, the plastic component is bypassed, and the stable component is updated using KL regularization to prevent negative transfer. This asymmetric design enables the model to adapt flexibly to new domains while preserving generalizable knowledge. Comprehensive evaluations on diverse multi-modal benchmarks demonstrate that DASP significantly outperforms state-of-the-art methods.
Dual Latent Memory for Visual Multi-agent System
Jan 31, 2026While Visual Multi-Agent Systems (VMAS) promise to enhance comprehensive abilities through inter-agent collaboration, empirical evidence reveals a counter-intuitive "scaling wall": increasing agent turns often degrades performance while exponentially inflating token costs. We attribute this failure to the information bottleneck inherent in text-centric communication, where converting perceptual and thinking trajectories into discrete natural language inevitably induces semantic loss. To this end, we propose L$^{2}$-VMAS, a novel model-agnostic framework that enables inter-agent collaboration with dual latent memories. Furthermore, we decouple the perception and thinking while dynamically synthesizing dual latent memories. Additionally, we introduce an entropy-driven proactive triggering that replaces passive information transmission with efficient, on-demand memory access. Extensive experiments among backbones, sizes, and multi-agent structures demonstrate that our method effectively breaks the "scaling wall" with superb scalability, improving average accuracy by 2.7-5.4% while reducing token usage by 21.3-44.8%. Codes: https://github.com/YU-deep/L2-VMAS.
VisMem: Latent Vision Memory Unlocks Potential of Vision-Language Models
Nov 14, 2025Despite the remarkable success of Vision-Language Models (VLMs), their performance on a range of complex visual tasks is often hindered by a "visual processing bottleneck": a propensity to lose grounding in visual evidence and exhibit a deficit in contextualized visual experience during prolonged generation. Drawing inspiration from human cognitive memory theory, which distinguishes short-term visually-dominant memory and long-term semantically-dominant memory, we propose VisMem, a cognitively-aligned framework that equips VLMs with dynamic latent vision memories, a short-term module for fine-grained perceptual retention and a long-term module for abstract semantic consolidation. These memories are seamlessly invoked during inference, allowing VLMs to maintain both perceptual fidelity and semantic consistency across thinking and generation. Extensive experiments across diverse visual benchmarks for understanding, reasoning, and generation reveal that VisMem delivers a significant average performance boost of 11.8% relative to the vanilla model and outperforms all counterparts, establishing a new paradigm for latent-space memory enhancement. The code will be available: https://github.com/YU-deep/VisMem.git.
SRGS: Super-Resolution 3D Gaussian Splatting
Apr 16, 2024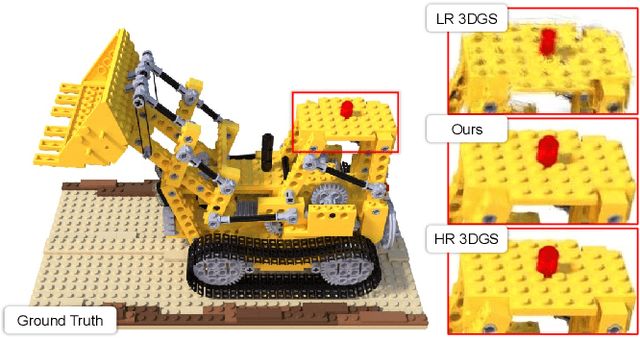
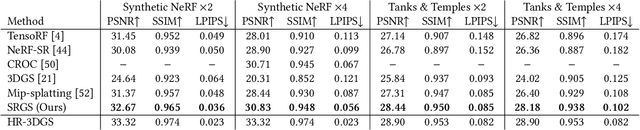
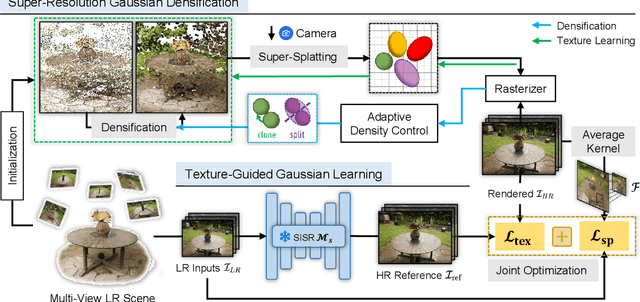
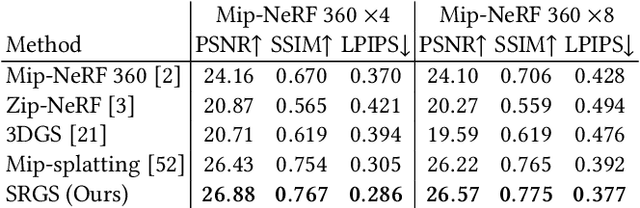
Recently, 3D Gaussian Splatting (3DGS) has gained popularity as a novel explicit 3D representation. This approach relies on the representation power of Gaussian primitives to provide a high-quality rendering. However, primitives optimized at low resolution inevitably exhibit sparsity and texture deficiency, posing a challenge for achieving high-resolution novel view synthesis (HRNVS). To address this problem, we propose Super-Resolution 3D Gaussian Splatting (SRGS) to perform the optimization in a high-resolution (HR) space. The sub-pixel constraint is introduced for the increased viewpoints in HR space, exploiting the sub-pixel cross-view information of the multiple low-resolution (LR) views. The gradient accumulated from more viewpoints will facilitate the densification of primitives. Furthermore, a pre-trained 2D super-resolution model is integrated with the sub-pixel constraint, enabling these dense primitives to learn faithful texture features. In general, our method focuses on densification and texture learning to effectively enhance the representation ability of primitives. Experimentally, our method achieves high rendering quality on HRNVS only with LR inputs, outperforming state-of-the-art methods on challenging datasets such as Mip-NeRF 360 and Tanks & Temples. Related codes will be released upon acceptance.
ZS-SRT: An Efficient Zero-Shot Super-Resolution Training Method for Neural Radiance Fields
Dec 19, 2023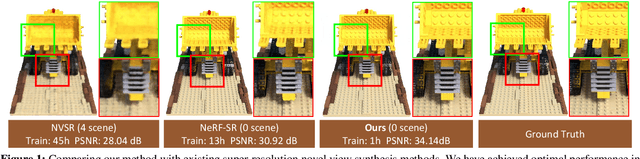
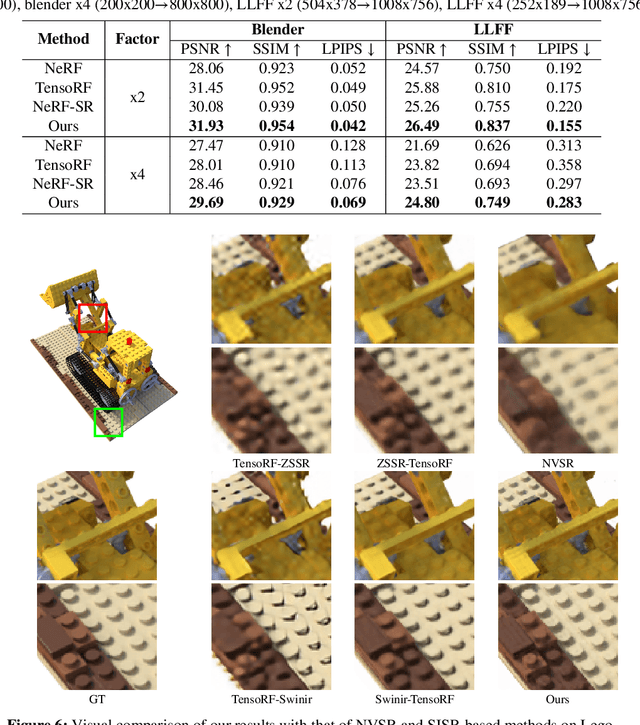
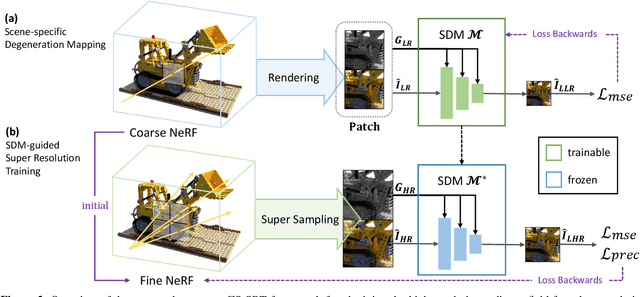
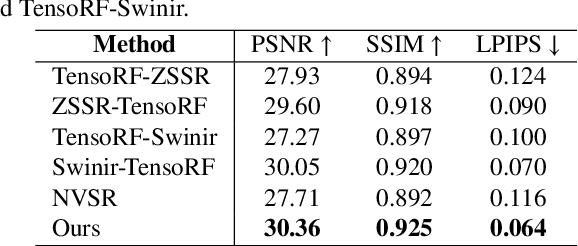
Neural Radiance Fields (NeRF) have achieved great success in the task of synthesizing novel views that preserve the same resolution as the training views. However, it is challenging for NeRF to synthesize high-quality high-resolution novel views with low-resolution training data. To solve this problem, we propose a zero-shot super-resolution training framework for NeRF. This framework aims to guide the NeRF model to synthesize high-resolution novel views via single-scene internal learning rather than requiring any external high-resolution training data. Our approach consists of two stages. First, we learn a scene-specific degradation mapping by performing internal learning on a pretrained low-resolution coarse NeRF. Second, we optimize a super-resolution fine NeRF by conducting inverse rendering with our mapping function so as to backpropagate the gradients from low-resolution 2D space into the super-resolution 3D sampling space. Then, we further introduce a temporal ensemble strategy in the inference phase to compensate for the scene estimation errors. Our method is featured on two points: (1) it does not consume high-resolution views or additional scene data to train super-resolution NeRF; (2) it can speed up the training process by adopting a coarse-to-fine strategy. By conducting extensive experiments on public datasets, we have qualitatively and quantitatively demonstrated the effectiveness of our method.
FDNet: Feature Decoupled Segmentation Network for Tooth CBCT Image
Nov 11, 2023Precise Tooth Cone Beam Computed Tomography (CBCT) image segmentation is crucial for orthodontic treatment planning. In this paper, we propose FDNet, a Feature Decoupled Segmentation Network, to excel in the face of the variable dental conditions encountered in CBCT scans, such as complex artifacts and indistinct tooth boundaries. The Low-Frequency Wavelet Transform (LF-Wavelet) is employed to enrich the semantic content by emphasizing the global structural integrity of the teeth, while the SAM encoder is leveraged to refine the boundary delineation, thus improving the contrast between adjacent dental structures. By integrating these dual aspects, FDNet adeptly addresses the semantic gap, providing a detailed and accurate segmentation. The framework's effectiveness is validated through rigorous benchmarks, achieving the top Dice and IoU scores of 85.28% and 75.23%, respectively. This innovative decoupling of semantic and boundary features capitalizes on the unique strengths of each element to significantly elevate the quality of segmentation performance.