 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToolWeaver: Weaving Collaborative Semantics for Scalable Tool Use in Large Language Models
Jan 29, 2026Prevalent retrieval-based tool-use pipelines struggle with a dual semantic challenge: their retrievers often employ encoders that fail to capture complex semantics, while the Large Language Model (LLM) itself lacks intrinsic tool knowledge from its natural language pretraining. Generative methods offer a powerful alternative by unifying selection and execution, tasking the LLM to directly learn and generate tool identifiers. However, the common practice of mapping each tool to a unique new token introduces substantial limitations: it creates a scalability and generalization crisis, as the vocabulary size explodes and each tool is assigned a semantically isolated token. This approach also creates a semantic bottleneck that hinders the learning of collaborative tool relationships, as the model must infer them from sparse co-occurrences of monolithic tool IDs within a vast library. To address these limitations, we propose ToolWeaver, a novel generative tool learning framework that encodes tools into hierarchical sequences. This approach makes vocabulary expansion logarithmic to the number of tools. Crucially, it enables the model to learn collaborative patterns from the dense co-occurrence of shared codes, rather than the sparse co-occurrence of monolithic tool IDs. We generate these structured codes through a novel tokenization process designed to weave together a tool's intrinsic semantics with its extrinsic co-usage patterns. These structured codes are then integrated into the LLM through a generative alignment stage, where the model is fine-tuned to produce the hierarchical code sequences. Evaluation results with nearly 47,000 tools show that ToolWeaver significantly outperforms state-of-the-art methods, establishing a more scalable, generalizable, and semantically-aware foundation for advanced tool-augmented agents.
UniBYD: A Unified Framework for Learning Robotic Manipulation Across Embodiments Beyond Imitation of Human Demonstrations
Dec 12, 2025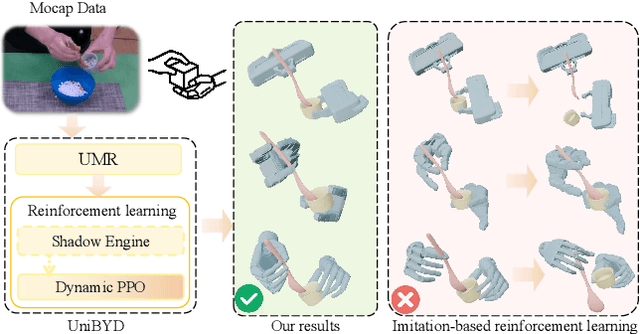
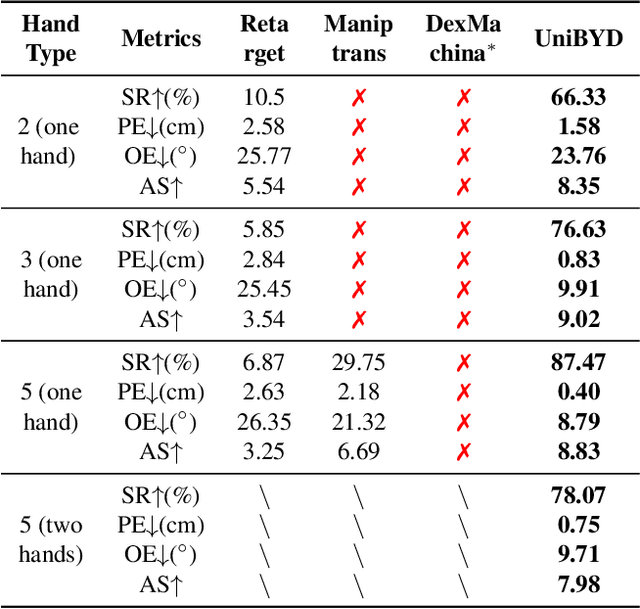
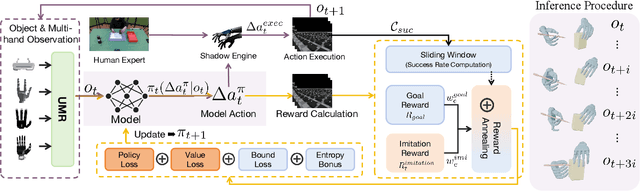
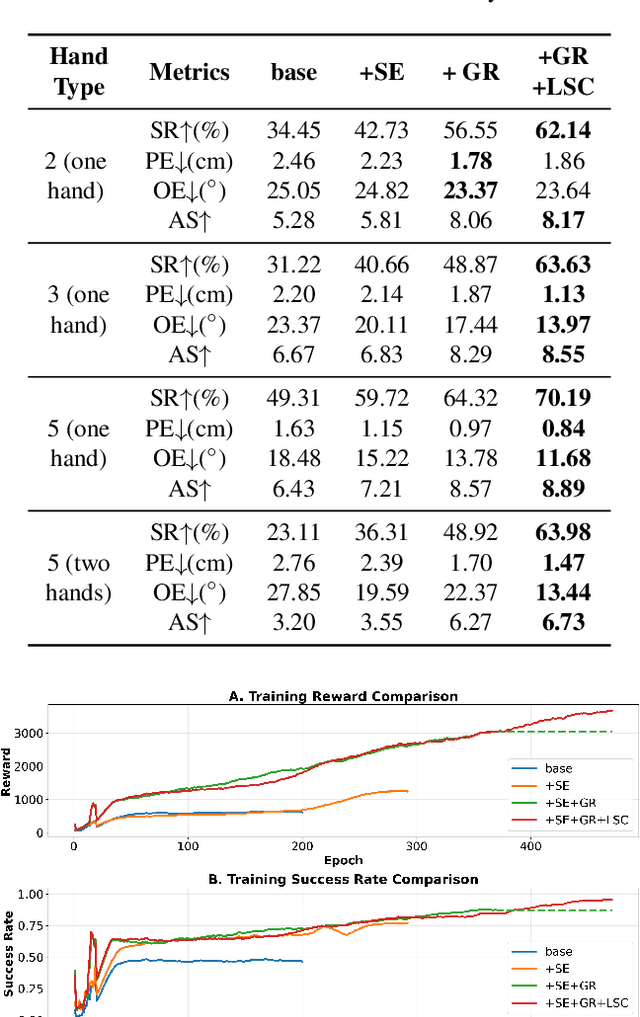
In embodied intelligence, the embodiment gap between robotic and human hands brings significant challenges for learning from human demonstrations. Although some studies have attempted to bridge this gap using reinforcement learning, they remain confined to merely reproducing human manipulation, resulting in limited task performance. In this paper, we propose UniBYD, a unified framework that uses a dynamic reinforcement learning algorithm to discover manipulation policies aligned with the robot's physical characteristics. To enable consistent modeling across diverse robotic hand morphologies, UniBYD incorporates a unified morphological representation (UMR). Building on UMR, we design a dynamic PPO with an annealed reward schedule, enabling reinforcement learning to transition from imitation of human demonstrations to explore policies adapted to diverse robotic morphologies better, thereby going beyond mere imitation of human hands. To address the frequent failures of learning human priors in the early training stage, we design a hybrid Markov-based shadow engine that enables reinforcement learning to imitate human manipulations in a fine-grained manner. To evaluate UniBYD comprehensively, we propose UniManip, the first benchmark encompassing robotic manipulation tasks spanning multiple hand morphologies. Experiments demonstrate a 67.90% improvement in success rate over the current state-of-the-art. Upon acceptance of the paper, we will release our code and benchmark at https://github.com/zhanheng-creator/UniBYD.
GenPilot: A Multi-Agent System for Test-Time Prompt Optimization in Image Generation
Oct 08, 2025Text-to-image synthesis has made remarkable progress, yet accurately interpreting complex and lengthy prompts remains challenging, often resulting in semantic inconsistencies and missing details. Existing solutions, such as fine-tuning, are model-specific and require training, while prior automatic prompt optimization (APO) approaches typically lack systematic error analysis and refinement strategies, resulting in limited reliability and effectiveness. Meanwhile, test-time scaling methods operate on fixed prompts and on noise or sample numbers, limiting their interpretability and adaptability. To solve these, we introduce a flexible and efficient test-time prompt optimization strategy that operates directly on the input text. We propose a plug-and-play multi-agent system called GenPilot, integrating error analysis, clustering-based adaptive exploration, fine-grained verification, and a memory module for iterative optimization. Our approach is model-agnostic, interpretable, and well-suited for handling long and complex prompts. Simultaneously, we summarize the common patterns of errors and the refinement strategy, offering more experience and encouraging further exploration. Experiments on DPG-bench and Geneval with improvements of up to 16.9% and 5.7% demonstrate the strong capability of our methods in enhancing the text and image consistency and structural coherence of generated images, revealing the effectiveness of our test-time prompt optimization strategy. The code is available at https://github.com/27yw/GenPilot.
Exploring the Inquiry-Diagnosis Relationship with Advanced Patient Simulators
Jan 16, 2025
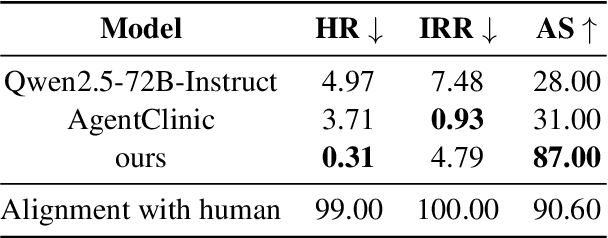


Online medical consultation (OMC) restricts doctors to gathering patient information solely through inquiries, making the already complex sequential decision-making process of diagnosis even more challenging. Recently, the rapid advancement of large language models has demonstrated a significant potential to transform OMC. However, most studies have primarily focused on improving diagnostic accuracy under conditions of relatively sufficient information, while paying limited attention to the "inquiry" phase of the consultation process. This lack of focus has left the relationship between "inquiry" and "diagnosis" insufficiently explored. In this paper, we first extract real patient interaction strategies from authentic doctor-patient conversations and use these strategies to guide the training of a patient simulator that closely mirrors real-world behavior. By inputting medical records into our patient simulator to simulate patient responses, we conduct extensive experiments to explore the relationship between "inquiry" and "diagnosis" in the consultation process. Experimental results demonstrate that inquiry and diagnosis adhere to the Liebig's law: poor inquiry quality limits the effectiveness of diagnosis, regardless of diagnostic capability, and vice versa. Furthermore, the experiments reveal significant differences in the inquiry performance of various models. To investigate this phenomenon, we categorize the inquiry process into four types: (1) chief complaint inquiry; (2) specification of known symptoms; (3) inquiry about accompanying symptoms; and (4) gathering family or medical history. We analyze the distribution of inquiries across the four types for different models to explore the reasons behind their significant performance differences. We plan to open-source the weights and related code of our patient simulator at https://github.com/LIO-H-ZEN/PatientSimulator.
GeoAI-Enhanced Community Detection on Spatial Networks with Graph Deep Learning
Nov 23, 2024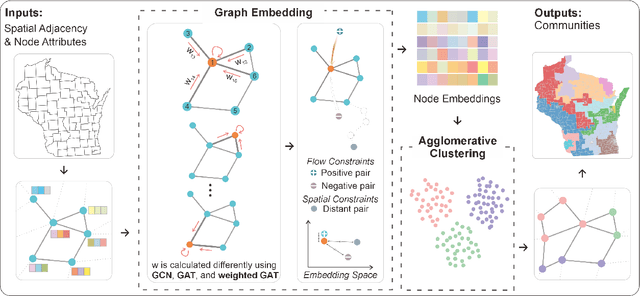
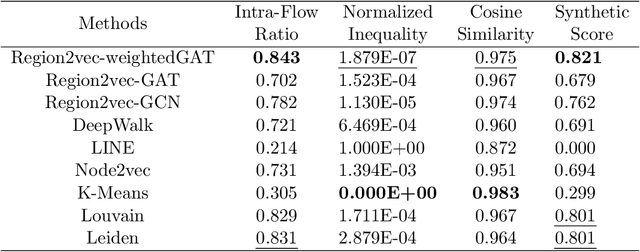
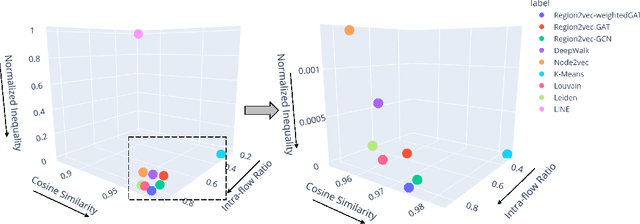
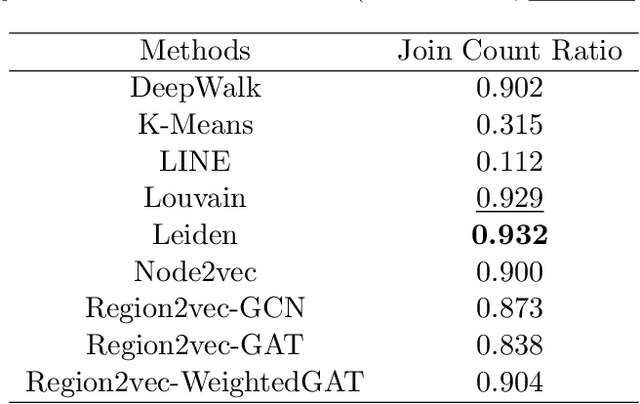
Spatial networks are useful for modeling geographic phenomena where spatial interaction plays an important role. To analyze the spatial networks and their internal structures, graph-based methods such as community detection have been widely used. Community detection aims to extract strongly connected components from the network and reveal the hidden relationships between nodes, but they usually do not involve the attribute information. To consider edge-based interactions and node attributes together, this study proposed a family of GeoAI-enhanced unsupervised community detection methods called region2vec based on Graph Attention Networks (GAT) and Graph Convolutional Networks (GCN). The region2vec methods generate node neural embeddings based on attribute similarity, geographic adjacency and spatial interactions, and then extract network communities based on node embeddings using agglomerative clustering. The proposed GeoAI-based methods are compared with multiple baselines and perform the best when one wants to maximize node attribute similarity and spatial interaction intensity simultaneously within the spatial network communities. It is further applied in the shortage area delineation problem in public health and demonstrates its promise in regionalization problems.
* 25 pages, 5 figures
Beyond Forecasting: Compositional Time Series Reasoning for End-to-End Task Execution
Oct 08, 2024



In recent decades, there has been substantial advances in time series models and benchmarks across various individual tasks, such as time series forecasting, classification, and anomaly detection. Meanwhile, compositional reasoning in time series is prevalent in real-world applications (e.g., decision-making and compositional question answering) and is in great demand. Unlike simple tasks that primarily focus on predictive accuracy, compositional reasoning emphasizes the synthesis of diverse information from both time series data and various domain knowledge, making it distinct and extremely more challenging. In this paper, we introduce Compositional Time Series Reasoning, a new task of handling intricate multistep reasoning tasks from time series data. Specifically, this new task focuses on various question instances requiring structural and compositional reasoning abilities on time series data, such as decision-making and compositional question answering. As an initial attempt to tackle this novel task, we developed TS-Reasoner, a program-aided approach that utilizes large language model (LLM) to decompose a complex task into steps of programs that leverage existing time series models and numerical subroutines. Unlike existing reasoning work which only calls off-the-shelf modules, TS-Reasoner allows for the creation of custom modules and provides greater flexibility to incorporate domain knowledge as well as user-specified constraints. We demonstrate the effectiveness of our method through a comprehensive set of experiments. These promising results indicate potential opportunities in the new task of time series reasoning and highlight the need for further research.
TimeDiT: General-purpose Diffusion Transformers for Time Series Foundation Model
Sep 03, 2024



With recent advances in building foundation models for texts and video data, there is a surge of interest in foundation models for time series. A family of models have been developed, utilizing a temporal auto-regressive generative Transformer architecture, whose effectiveness has been proven in Large Language Models. While the empirical results are promising, almost all existing time series foundation models have only been tested on well-curated ``benchmark'' datasets very similar to texts. However, real-world time series exhibit unique challenges, such as variable channel sizes across domains, missing values, and varying signal sampling intervals due to the multi-resolution nature of real-world data. Additionally, the uni-directional nature of temporally auto-regressive decoding limits the incorporation of domain knowledge, such as physical laws expressed as partial differential equations (PDEs). To address these challenges, we introduce the Time Diffusion Transformer (TimeDiT), a general foundation model for time series that employs a denoising diffusion paradigm instead of temporal auto-regressive generation. TimeDiT leverages the Transformer architecture to capture temporal dependencies and employs diffusion processes to generate high-quality candidate samples without imposing stringent assumptions on the target distribution via novel masking schemes and a channel alignment strategy. Furthermore, we propose a finetuning-free model editing strategy that allows the seamless integration of external knowledge during the sampling process without updating any model parameters. Extensive experiments conducted on a varity of tasks such as forecasting, imputation, and anomaly detection, demonstrate the effectiveness of TimeDiT.
TEMPO: Prompt-based Generative Pre-trained Transformer for Time Series Forecasting
Oct 12, 2023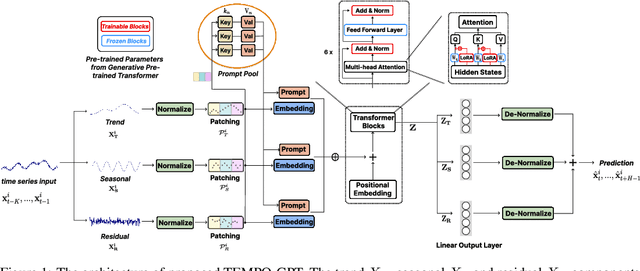
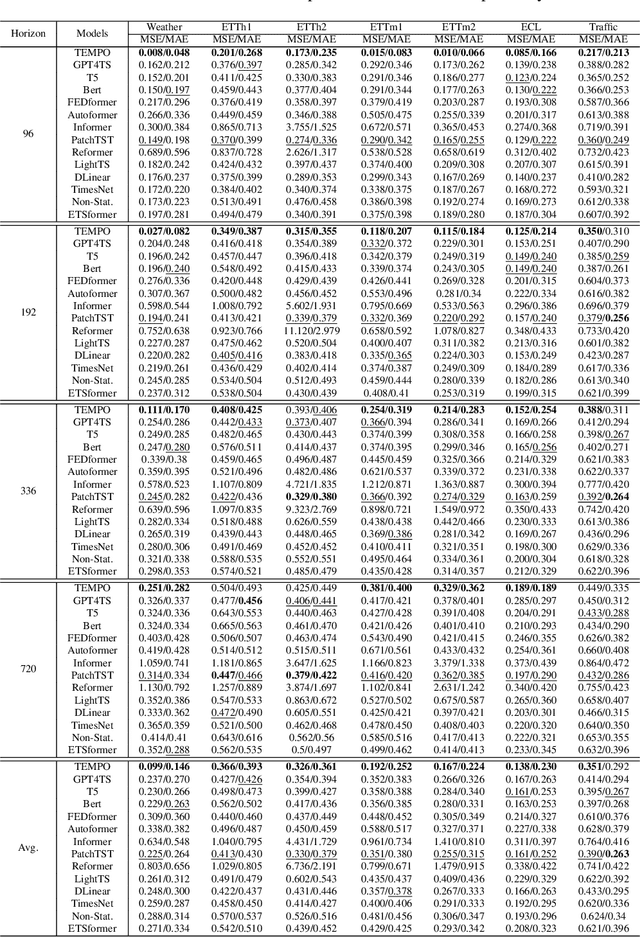


The past decade has witnessed significant advances in time series modeling with deep learning. While achieving state-of-the-art results, the best-performing architectures vary highly across applications and domains. Meanwhile, for natural language processing, the Generative Pre-trained Transformer (GPT) has demonstrated impressive performance via training one general-purpose model across various textual datasets. It is intriguing to explore whether GPT-type architectures can be effective for time series, capturing the intrinsic dynamic attributes and leading to significant accuracy improvements. In this paper, we propose a novel framework, TEMPO, that can effectively learn time series representations. We focus on utilizing two essential inductive biases of the time series task for pre-trained models: (i) decomposition of the complex interaction between trend, seasonal and residual components; and (ii) introducing the selection-based prompts to facilitate distribution adaptation in non-stationary time series. TEMPO expands the capability for dynamically modeling real-world temporal phenomena from data within diverse domains. Our experiments demonstrate the superior performance of TEMPO over state-of-the-art methods on a number of time series benchmark datasets. This performance gain is observed not only in standard supervised learning settings but also in scenarios involving previously unseen datasets as well as in scenarios with multi-modal inputs. This compelling finding highlights TEMPO's potential to constitute a foundational model-building framework.