 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkinFlow: Efficient Information Transmission for Open Dermatological Diagnosis via Dynamic Visual Encoding and Staged RL
Jan 14, 2026General-purpose Large Vision-Language Models (LVLMs), despite their massive scale, often falter in dermatology due to "diffuse attention" - the inability to disentangle subtle pathological lesions from background noise. In this paper, we challenge the assumption that parameter scaling is the only path to medical precision. We introduce SkinFlow, a framework that treats diagnosis as an optimization of visual information transmission efficiency. Our approach utilizes a Virtual-Width Dynamic Vision Encoder (DVE) to "unfold" complex pathological manifolds without physical parameter expansion, coupled with a two-stage Reinforcement Learning strategy. This strategy sequentially aligns explicit medical descriptions (Stage I) and reconstructs implicit diagnostic textures (Stage II) within a constrained semantic space. Furthermore, we propose a clinically grounded evaluation protocol that prioritizes diagnostic safety and hierarchical relevance over rigid label matching. Empirical results are compelling: our 7B model establishes a new state-of-the-art on the Fitzpatrick17k benchmark, achieving a +12.06% gain in Top-1 accuracy and a +28.57% boost in Top-6 accuracy over the massive general-purpose models (e.g., Qwen3VL-235B and GPT-5.2). These findings demonstrate that optimizing geometric capacity and information flow yields superior diagnostic reasoning compared to raw parameter scaling.
Exploring the Inquiry-Diagnosis Relationship with Advanced Patient Simulators
Jan 16, 2025
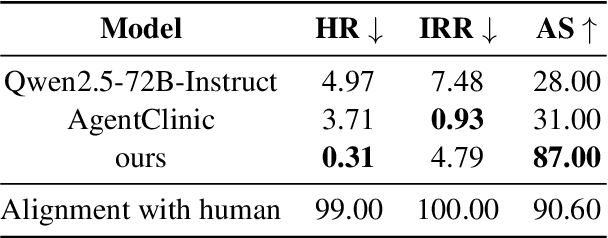


Online medical consultation (OMC) restricts doctors to gathering patient information solely through inquiries, making the already complex sequential decision-making process of diagnosis even more challenging. Recently, the rapid advancement of large language models has demonstrated a significant potential to transform OMC. However, most studies have primarily focused on improving diagnostic accuracy under conditions of relatively sufficient information, while paying limited attention to the "inquiry" phase of the consultation process. This lack of focus has left the relationship between "inquiry" and "diagnosis" insufficiently explored. In this paper, we first extract real patient interaction strategies from authentic doctor-patient conversations and use these strategies to guide the training of a patient simulator that closely mirrors real-world behavior. By inputting medical records into our patient simulator to simulate patient responses, we conduct extensive experiments to explore the relationship between "inquiry" and "diagnosis" in the consultation process. Experimental results demonstrate that inquiry and diagnosis adhere to the Liebig's law: poor inquiry quality limits the effectiveness of diagnosis, regardless of diagnostic capability, and vice versa. Furthermore, the experiments reveal significant differences in the inquiry performance of various models. To investigate this phenomenon, we categorize the inquiry process into four types: (1) chief complaint inquiry; (2) specification of known symptoms; (3) inquiry about accompanying symptoms; and (4) gathering family or medical history. We analyze the distribution of inquiries across the four types for different models to explore the reasons behind their significant performance differences. We plan to open-source the weights and related code of our patient simulator at https://github.com/LIO-H-ZEN/PatientSimulator.