 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkinFlow: Efficient Information Transmission for Open Dermatological Diagnosis via Dynamic Visual Encoding and Staged RL
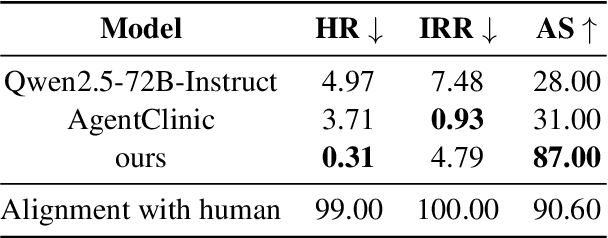
Jan 14, 2026General-purpose Large Vision-Language Models (LVLMs), despite their massive scale, often falter in dermatology due to "diffuse attention" - the inability to disentangle subtle pathological lesions from background noise. In this paper, we challenge the assumption that parameter scaling is the only path to medical precision. We introduce SkinFlow, a framework that treats diagnosis as an optimization of visual information transmission efficiency. Our approach utilizes a Virtual-Width Dynamic Vision Encoder (DVE) to "unfold" complex pathological manifolds without physical parameter expansion, coupled with a two-stage Reinforcement Learning strategy. This strategy sequentially aligns explicit medical descriptions (Stage I) and reconstructs implicit diagnostic textures (Stage II) within a constrained semantic space. Furthermore, we propose a clinically grounded evaluation protocol that prioritizes diagnostic safety and hierarchical relevance over rigid label matching. Empirical results are compelling: our 7B model establishes a new state-of-the-art on the Fitzpatrick17k benchmark, achieving a +12.06% gain in Top-1 accuracy and a +28.57% boost in Top-6 accuracy over the massive general-purpose models (e.g., Qwen3VL-235B and GPT-5.2). These findings demonstrate that optimizing geometric capacity and information flow yields superior diagnostic reasoning compared to raw parameter scaling.
HierSearch: A Hierarchical Enterprise Deep Search Framework Integrating Local and Web Searches
Aug 11, 2025Recently, large reasoning models have demonstrated strong mathematical and coding abilities, and deep search leverages their reasoning capabilities in challenging information retrieval tasks. Existing deep search works are generally limited to a single knowledge source, either local or the Web. However, enterprises often require private deep search systems that can leverage search tools over both local and the Web corpus. Simply training an agent equipped with multiple search tools using flat reinforcement learning (RL) is a straightforward idea, but it has problems such as low training data efficiency and poor mastery of complex tools. To address the above issue, we propose a hierarchical agentic deep search framework, HierSearch, trained with hierarchical RL. At the low level, a local deep search agent and a Web deep search agent are trained to retrieve evidence from their corresponding domains. At the high level, a planner agent coordinates low-level agents and provides the final answer. Moreover, to prevent direct answer copying and error propagation, we design a knowledge refiner that filters out hallucinations and irrelevant evidence returned by low-level agents. Experiments show that HierSearch achieves better performance compared to flat RL, and outperforms various deep search and multi-source retrieval-augmented generation baselines in six benchmarks across general, finance, and medical domains.
Efficient Medical VIE via Reinforcement Learning
Jun 16, 2025Visual Information Extraction (VIE) converts unstructured document images into structured formats like JSON, critical for medical applications such as report analysis and online consultations. Traditional methods rely on OCR and language models, while end-to-end multimodal models offer direct JSON generation. However, domain-specific schemas and high annotation costs limit their effectiveness in medical VIE. We base our approach on the Reinforcement Learning with Verifiable Rewards (RLVR) framework to address these challenges using only 100 annotated samples. Our approach ensures dataset diversity, a balanced precision-recall reward mechanism to reduce hallucinations and improve field coverage, and innovative sampling strategies to enhance reasoning capabilities. Fine-tuning Qwen2.5-VL-7B with our RLVR method, we achieve state-of-the-art performance on medical VIE tasks, significantly improving F1, precision, and recall. While our models excel on tasks similar to medical datasets, performance drops on dissimilar tasks, highlighting the need for domain-specific optimization. Case studies further demonstrate the value of reasoning during training and inference for VIE.
Exploring the Inquiry-Diagnosis Relationship with Advanced Patient Simulators
Jan 16, 2025


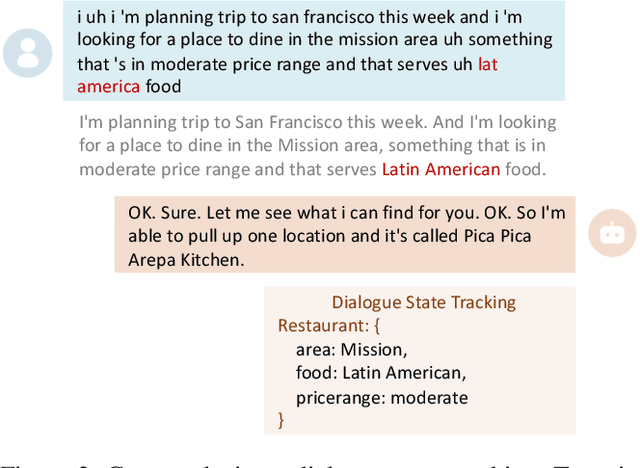
Online medical consultation (OMC) restricts doctors to gathering patient information solely through inquiries, making the already complex sequential decision-making process of diagnosis even more challenging. Recently, the rapid advancement of large language models has demonstrated a significant potential to transform OMC. However, most studies have primarily focused on improving diagnostic accuracy under conditions of relatively sufficient information, while paying limited attention to the "inquiry" phase of the consultation process. This lack of focus has left the relationship between "inquiry" and "diagnosis" insufficiently explored. In this paper, we first extract real patient interaction strategies from authentic doctor-patient conversations and use these strategies to guide the training of a patient simulator that closely mirrors real-world behavior. By inputting medical records into our patient simulator to simulate patient responses, we conduct extensive experiments to explore the relationship between "inquiry" and "diagnosis" in the consultation process. Experimental results demonstrate that inquiry and diagnosis adhere to the Liebig's law: poor inquiry quality limits the effectiveness of diagnosis, regardless of diagnostic capability, and vice versa. Furthermore, the experiments reveal significant differences in the inquiry performance of various models. To investigate this phenomenon, we categorize the inquiry process into four types: (1) chief complaint inquiry; (2) specification of known symptoms; (3) inquiry about accompanying symptoms; and (4) gathering family or medical history. We analyze the distribution of inquiries across the four types for different models to explore the reasons behind their significant performance differences. We plan to open-source the weights and related code of our patient simulator at https://github.com/LIO-H-ZEN/PatientSimulator.
Baichuan4-Finance Technical Report
Dec 17, 2024



Large language models (LLMs) have demonstrated strong capabilities in language understanding, generation, and reasoning, yet their potential in finance remains underexplored due to the complexity and specialization of financial knowledge. In this work, we report the development of the Baichuan4-Finance series, including a comprehensive suite of foundational Baichuan4-Finance-Base and an aligned language model Baichuan4-Finance, which are built upon Baichuan4-Turbo base model and tailored for finance domain. Firstly, we have dedicated significant effort to building a detailed pipeline for improving data quality. Moreover, in the continual pre-training phase, we propose a novel domain self-constraint training strategy, which enables Baichuan4-Finance-Base to acquire financial knowledge without losing general capabilities. After Supervised Fine-tuning and Reinforcement Learning from Human Feedback and AI Feedback, the chat model Baichuan4-Finance is able to tackle various financial certification questions and real-world scenario applications. We evaluate Baichuan4-Finance on many widely used general datasets and two holistic financial benchmarks. The evaluation results show that Baichuan4-Finance-Base surpasses almost all competitive baselines on financial tasks by significant margins without sacrificing performance on general LLM benchmarks. At the same time, Baichuan4-Finance demonstrates even more impressive performance on financial application scenarios, showcasing its potential to foster community innovation in the financial LLM field.
Dialogue State Distillation Network with Inter-Slot Contrastive Learning for Dialogue State Tracking
Feb 16, 2023



In task-oriented dialogue systems, Dialogue State Tracking (DST) aims to extract users' intentions from the dialogue history. Currently, most existing approaches suffer from error propagation and are unable to dynamically select relevant information when utilizing previous dialogue states. Moreover, the relations between the updates of different slots provide vital clues for DST. However, the existing approaches rely only on predefined graphs to indirectly capture the relations. In this paper, we propose a Dialogue State Distillation Network (DSDN) to utilize relevant information of previous dialogue states and migrate the gap of utilization between training and testing. Thus, it can dynamically exploit previous dialogue states and avoid introducing error propagation simultaneously. Further, we propose an inter-slot contrastive learning loss to effectively capture the slot co-update relations from dialogue context. Experiments are conducted on the widely used MultiWOZ 2.0 and MultiWOZ 2.1 datasets. The experimental results show that our proposed model achieves the state-of-the-art performance for DST.
TOD-DA: Towards Boosting the Robustness of Task-oriented Dialogue Modeling on Spoken Conversations
Dec 23, 2021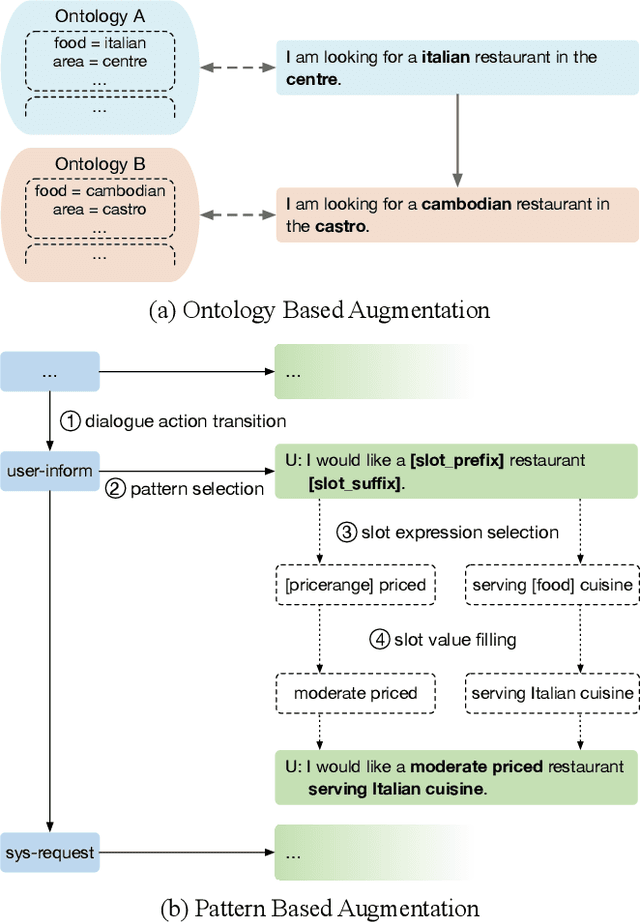
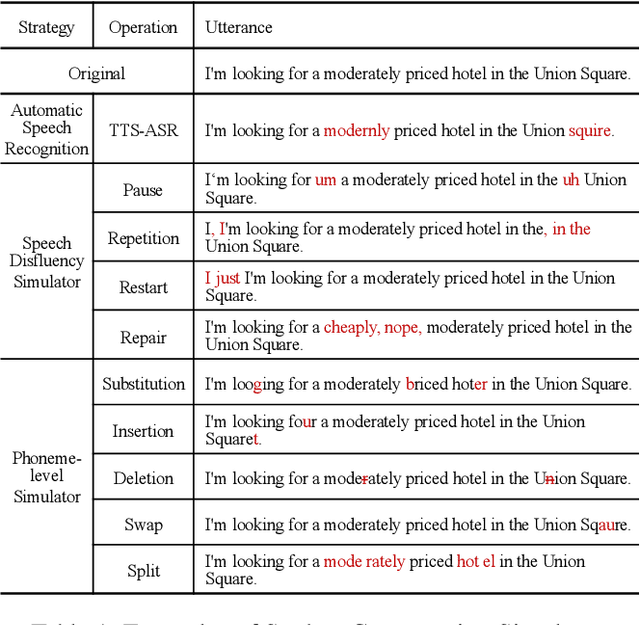

Task-oriented dialogue systems have been plagued by the difficulties of obtaining large-scale and high-quality annotated conversations. Furthermore, most of the publicly available datasets only include written conversations, which are insufficient to reflect actual human behaviors in practical spoken dialogue systems. In this paper, we propose Task-oriented Dialogue Data Augmentation (TOD-DA), a novel model-agnostic data augmentation paradigm to boost the robustness of task-oriented dialogue modeling on spoken conversations. The TOD-DA consists of two modules: 1) Dialogue Enrichment to expand training data on task-oriented conversations for easing data sparsity and 2) Spoken Conversation Simulator to imitate oral style expressions and speech recognition errors in diverse granularities for bridging the gap between written and spoken conversations. With such designs, our approach ranked first in both tasks of DSTC10 Track2, a benchmark for task-oriented dialogue modeling on spoken conversations, demonstrating the superiority and effectiveness of our proposed TOD-DA.