 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
X-Driver: Explainable Autonomous Driving with Vision-Language Models
May 08, 2025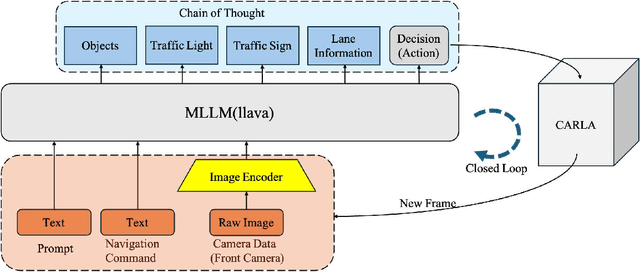
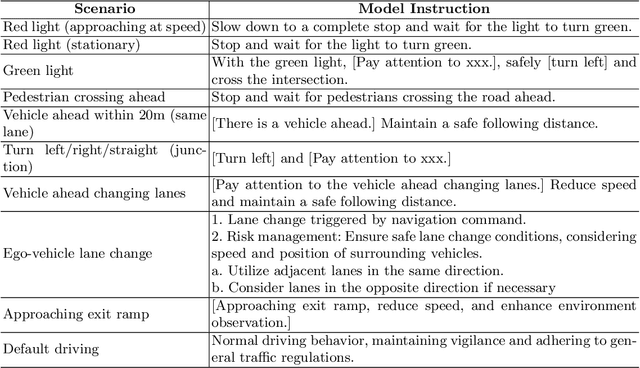
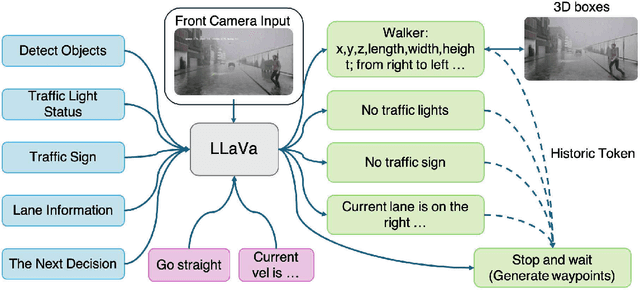

End-to-end autonomous driving has advanced significantly, offering benefits such as system simplicity and stronger driving performance in both open-loop and closed-loop settings than conventional pipelines. However, existing frameworks still suffer from low success rates in closed-loop evaluations, highlighting their limitations in real-world deployment. In this paper, we introduce X-Driver, a unified multi-modal large language models(MLLMs) framework designed for closed-loop autonomous driving, leveraging Chain-of-Thought(CoT) and autoregressive modeling to enhance perception and decision-making. We validate X-Driver across multiple autonomous driving tasks using public benchmarks in CARLA simulation environment, including Bench2Drive[6]. Our experimental results demonstrate superior closed-loop performance, surpassing the current state-of-the-art(SOTA) while improving the interpretability of driving decisions. These findings underscore the importance of structured reasoning in end-to-end driving and establish X-Driver as a strong baseline for future research in closed-loop autonomous driving.
Q-TOD: A Query-driven Task-oriented Dialogue System
Oct 14, 2022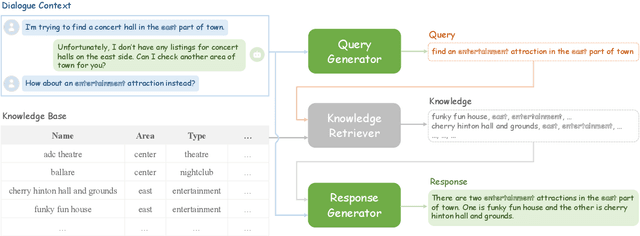
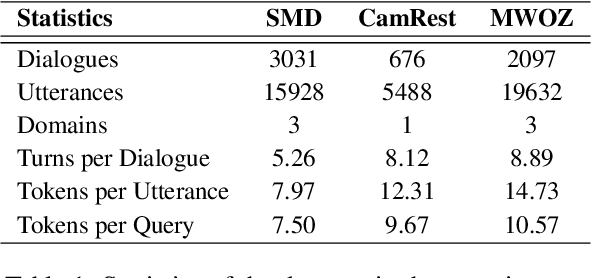
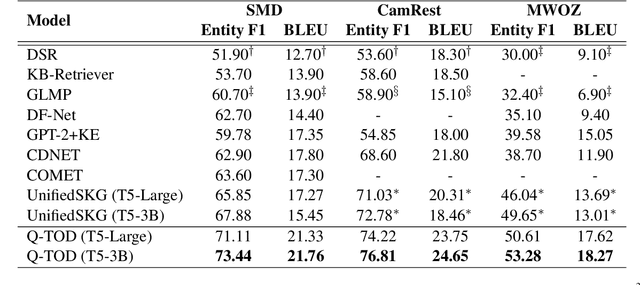
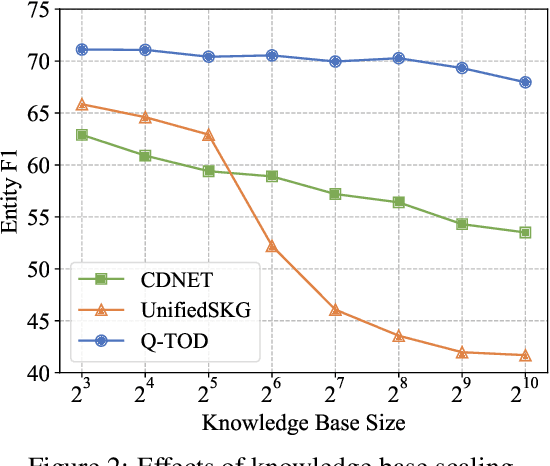
Existing pipelined task-oriented dialogue systems usually have difficulties adapting to unseen domains, whereas end-to-end systems are plagued by large-scale knowledge bases in practice. In this paper, we introduce a novel query-driven task-oriented dialogue system, namely Q-TOD. The essential information from the dialogue context is extracted into a query, which is further employed to retrieve relevant knowledge records for response generation. Firstly, as the query is in the form of natural language and not confined to the schema of the knowledge base, the issue of domain adaption is alleviated remarkably in Q-TOD. Secondly, as the query enables the decoupling of knowledge retrieval from the generation, Q-TOD gets rid of the issue of knowledge base scalability. To evaluate the effectiveness of the proposed Q-TOD, we collect query annotations for three publicly available task-oriented dialogue datasets. Comprehensive experiments verify that Q-TOD outperforms strong baselines and establishes a new state-of-the-art performance on these datasets.
TOD-DA: Towards Boosting the Robustness of Task-oriented Dialogue Modeling on Spoken Conversations
Dec 23, 2021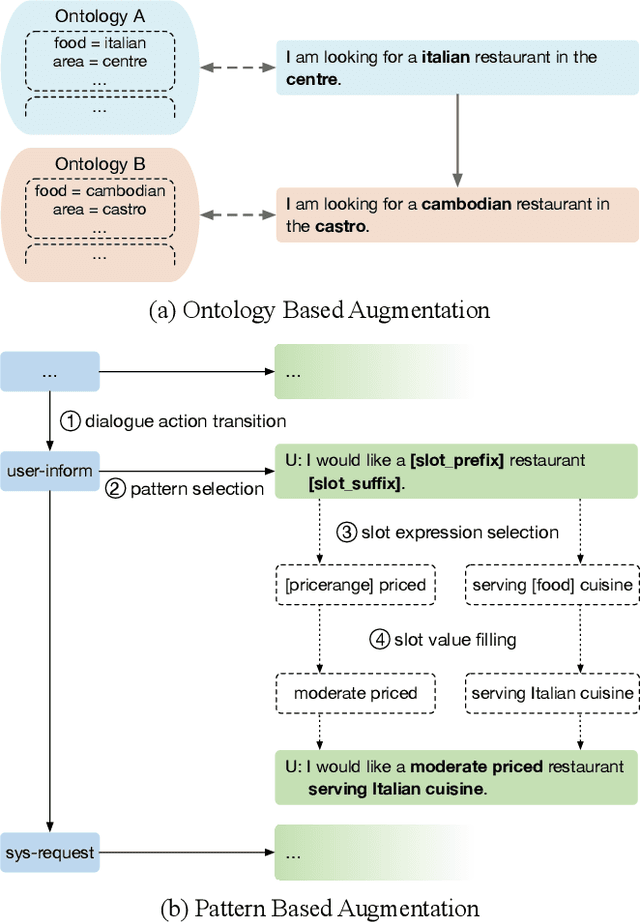
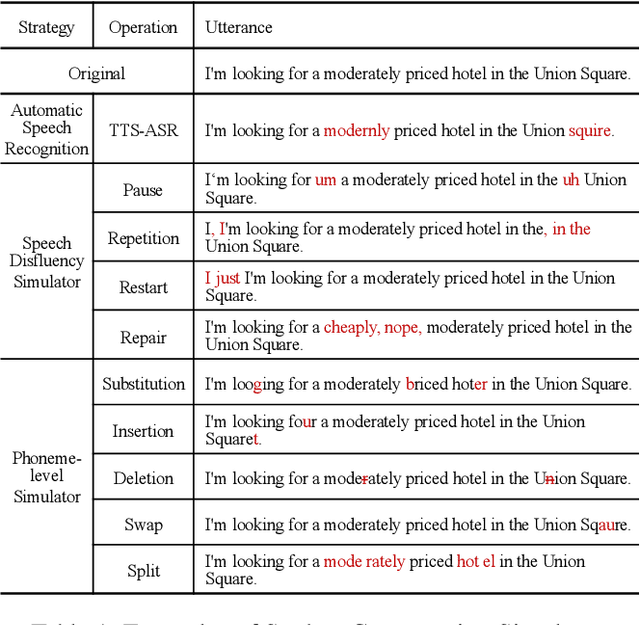

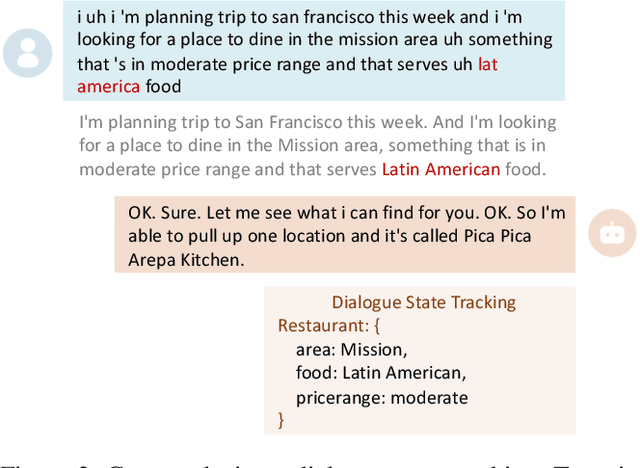
Task-oriented dialogue systems have been plagued by the difficulties of obtaining large-scale and high-quality annotated conversations. Furthermore, most of the publicly available datasets only include written conversations, which are insufficient to reflect actual human behaviors in practical spoken dialogue systems. In this paper, we propose Task-oriented Dialogue Data Augmentation (TOD-DA), a novel model-agnostic data augmentation paradigm to boost the robustness of task-oriented dialogue modeling on spoken conversations. The TOD-DA consists of two modules: 1) Dialogue Enrichment to expand training data on task-oriented conversations for easing data sparsity and 2) Spoken Conversation Simulator to imitate oral style expressions and speech recognition errors in diverse granularities for bridging the gap between written and spoken conversations. With such designs, our approach ranked first in both tasks of DSTC10 Track2, a benchmark for task-oriented dialogue modeling on spoken conversations, demonstrating the superiority and effectiveness of our proposed TOD-DA.
Amendable Generation for Dialogue State Tracking
Oct 29, 2021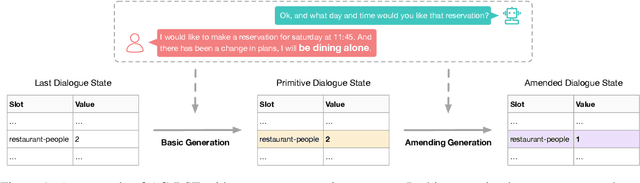
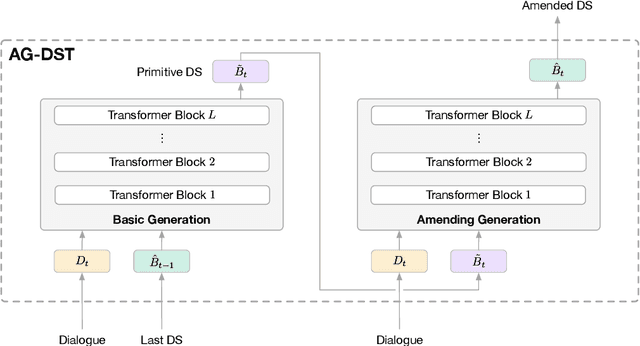
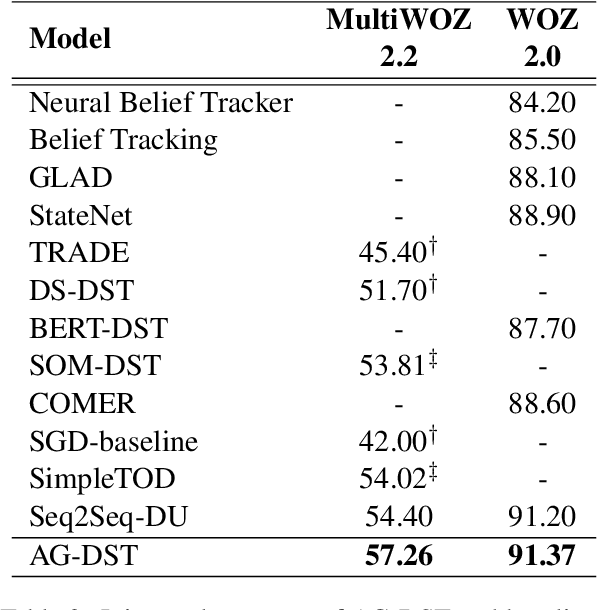
In task-oriented dialogue systems, recent dialogue state tracking methods tend to perform one-pass generation of the dialogue state based on the previous dialogue state. The mistakes of these models made at the current turn are prone to be carried over to the next turn, causing error propagation. In this paper, we propose a novel Amendable Generation for Dialogue State Tracking (AG-DST), which contains a two-pass generation process: (1) generating a primitive dialogue state based on the dialogue of the current turn and the previous dialogue state, and (2) amending the primitive dialogue state from the first pass. With the additional amending generation pass, our model is tasked to learn more robust dialogue state tracking by amending the errors that still exist in the primitive dialogue state, which plays the role of reviser in the double-checking process and alleviates unnecessary error propagation. Experimental results show that AG-DST significantly outperforms previous works in two active DST datasets (MultiWOZ 2.2 and WOZ 2.0), achieving new state-of-the-art performances.
PLATO-XL: Exploring the Large-scale Pre-training of Dialogue Generation
Sep 20, 2021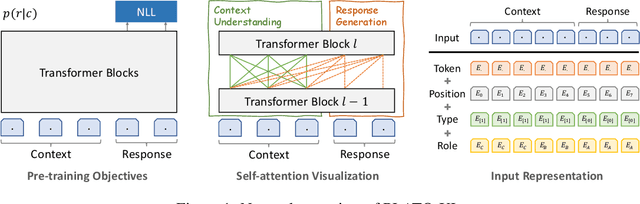
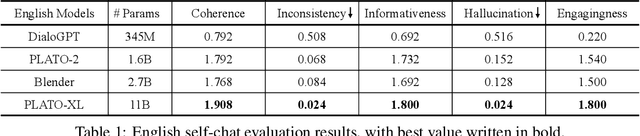

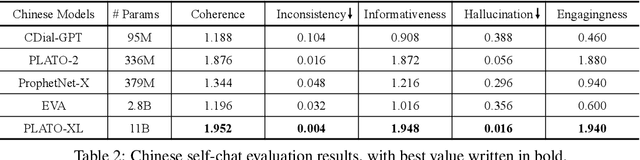
To explore the limit of dialogue generation pre-training, we present the models of PLATO-XL with up to 11 billion parameters, trained on both Chinese and English social media conversations. To train such large models, we adopt the architecture of unified transformer with high computation and parameter efficiency. In addition, we carry out multi-party aware pre-training to better distinguish the characteristic information in social media conversations. With such designs, PLATO-XL successfully achieves superior performances as compared to other approaches in both Chinese and English chitchat. We further explore the capacity of PLATO-XL on other conversational tasks, such as knowledge grounded dialogue and task-oriented conversation. The experimental results indicate that PLATO-XL obtains state-of-the-art results across multiple conversational tasks, verifying its potential as a foundation model of conversational AI.
A Unified Pre-training Framework for Conversational AI
May 27, 2021

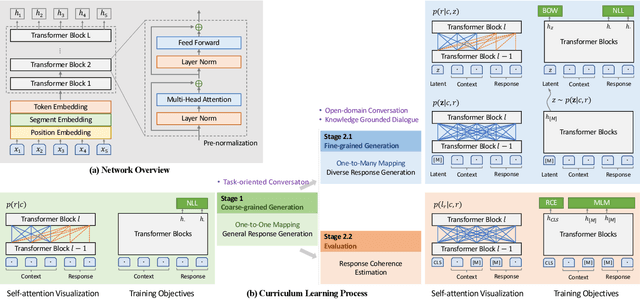

In this work, we explore the application of PLATO-2 on various dialogue systems, including open-domain conversation, knowledge grounded dialogue, and task-oriented conversation. PLATO-2 is initially designed as an open-domain chatbot, trained via two-stage curriculum learning. In the first stage, a coarse-grained response generation model is learned to fit the simplified one-to-one mapping relationship. This model is applied to the task-oriented conversation, given that the semantic mappings tend to be deterministic in task completion. In the second stage, another fine-grained generation model and an evaluation model are further learned for diverse response generation and coherence estimation, respectively. With superior capability on capturing one-to-many mapping, such models are suitable for the open-domain conversation and knowledge grounded dialogue. For the comprehensive evaluation of PLATO-2, we have participated in multiple tasks of DSTC9, including interactive evaluation of open-domain conversation (Track3-task2), static evaluation of knowledge grounded dialogue (Track3-task1), and end-to-end task-oriented conversation (Track2-task1). PLATO-2 has obtained the 1st place in all three tasks, verifying its effectiveness as a unified framework for various dialogue systems.