 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSFormer: SNR-guided Transformer for Underwater Image Enhancement from the Frequency Domain
Aug 26, 2025


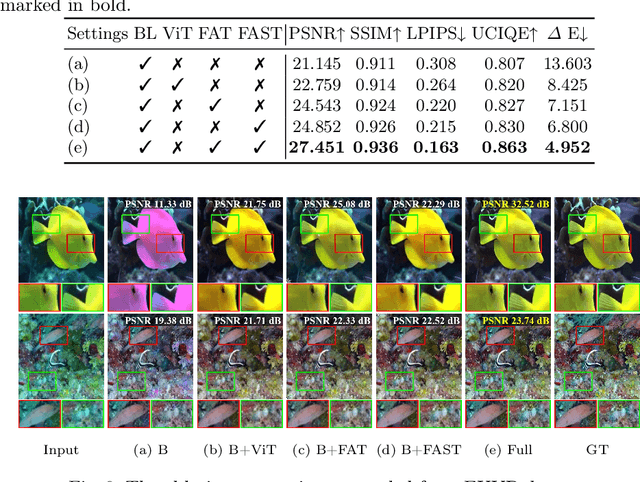
Recent learning-based underwater image enhancement (UIE) methods have advanced by incorporating physical priors into deep neural networks, particularly using the signal-to-noise ratio (SNR) prior to reduce wavelength-dependent attenuation. However, spatial domain SNR priors have two limitations: (i) they cannot effectively separate cross-channel interference, and (ii) they provide limited help in amplifying informative structures while suppressing noise. To overcome these, we propose using the SNR prior in the frequency domain, decomposing features into amplitude and phase spectra for better channel modulation. We introduce the Fourier Attention SNR-prior Transformer (FAST), combining spectral interactions with SNR cues to highlight key spectral components. Additionally, the Frequency Adaptive Transformer (FAT) bottleneck merges low- and high-frequency branches using a gated attention mechanism to enhance perceptual quality. Embedded in a unified U-shaped architecture, these modules integrate a conventional RGB stream with an SNR-guided branch, forming SFormer. Trained on 4,800 paired images from UIEB, EUVP, and LSUI, SFormer surpasses recent methods with a 3.1 dB gain in PSNR and 0.08 in SSIM, successfully restoring colors, textures, and contrast in underwater scenes.
Gaussian Primitive Optimized Deformable Retinal Image Registration
Aug 23, 2025



Deformable retinal image registration is notoriously difficult due to large homogeneous regions and sparse but critical vascular features, which cause limited gradient signals in standard learning-based frameworks. In this paper, we introduce Gaussian Primitive Optimization (GPO), a novel iterative framework that performs structured message passing to overcome these challenges. After an initial coarse alignment, we extract keypoints at salient anatomical structures (e.g., major vessels) to serve as a minimal set of descriptor-based control nodes (DCN). Each node is modelled as a Gaussian primitive with trainable position, displacement, and radius, thus adapting its spatial influence to local deformation scales. A K-Nearest Neighbors (KNN) Gaussian interpolation then blends and propagates displacement signals from these information-rich nodes to construct a globally coherent displacement field; focusing interpolation on the top (K) neighbors reduces computational overhead while preserving local detail. By strategically anchoring nodes in high-gradient regions, GPO ensures robust gradient flow, mitigating vanishing gradient signal in textureless areas. The framework is optimized end-to-end via a multi-term loss that enforces both keypoint consistency and intensity alignment. Experiments on the FIRE dataset show that GPO reduces the target registration error from 6.2\,px to ~2.4\,px and increases the AUC at 25\,px from 0.770 to 0.938, substantially outperforming existing methods. The source code can be accessed via https://github.com/xintian-99/GPOreg.
From Rankings to Insights: Evaluation Should Shift Focus from Leaderboard to Feedback
May 10, 2025Automatic evaluation benchmarks such as MT-Bench, Arena-Hard, and Auto-Arena are seeing growing adoption for the evaluation of Large Language Models (LLMs). Existing research has primarily focused on approximating human-based model rankings using limited data and LLM-as-a-Judge. However, the fundamental premise of these studies, which attempts to replicate human rankings, is flawed. Specifically, these benchmarks typically offer only overall scores, limiting their utility to leaderboard rankings, rather than providing feedback that can guide model optimization and support model profiling. Therefore, we advocate for an evaluation paradigm shift from approximating human-based model rankings to providing feedback with analytical value. To this end, we introduce Feedbacker, an evaluation framework that provides comprehensive and fine-grained results, thereby enabling thorough identification of a model's specific strengths and weaknesses. Such feedback not only supports the targeted optimization of the model but also enhances the understanding of its behavior. Feedbacker comprises three key components: an extensible tree-based query taxonomy builder, an automated query synthesis scheme, and a suite of visualization and analysis tools. Furthermore, we propose a novel LLM-as-a-Judge method: PC2 (Pre-Comparison-derived Criteria) pointwise evaluation. This method derives evaluation criteria by pre-comparing the differences between several auxiliary responses, achieving the accuracy of pairwise evaluation while maintaining the time complexity of pointwise evaluation. Finally, leveraging the evaluation results of 17 mainstream LLMs, we demonstrate the usage of Feedbacker and highlight its effectiveness and potential. Our homepage project is available at https://liudan193.github.io/Feedbacker.
Mamba-Based Ensemble learning for White Blood Cell Classification
Apr 15, 2025White blood cell (WBC) classification assists in assessing immune health and diagnosing various diseases, yet manual classification is labor-intensive and prone to inconsistencies. Recent advancements in deep learning have shown promise over traditional methods; however, challenges such as data imbalance and the computational demands of modern technologies, such as Transformer-based models which do not scale well with input size, limit their practical application. This paper introduces a novel framework that leverages Mamba models integrated with ensemble learning to improve WBC classification. Mamba models, known for their linear complexity, provide a scalable alternative to Transformer-based approaches, making them suitable for deployment in resource-constrained environments. Additionally, we introduce a new WBC dataset, Chula-WBC-8, for benchmarking. Our approach not only validates the effectiveness of Mamba models in this domain but also demonstrates their potential to significantly enhance classification efficiency without compromising accuracy. The source code can be found at https://github.com/LewisClifton/Mamba-WBC-Classification.
Multimodal Image Matching based on Frequency-domain Information of Local Energy Response
Mar 26, 2025Complicated nonlinear intensity differences, nonlinear local geometric distortions, noises and rotation transformation are main challenges in multimodal image matching. In order to solve these problems, we propose a method based on Frequency-domain Information of Local Energy Response called FILER. The core of FILER is the local energy response model based on frequency-domain information, which can overcome the effect of nonlinear intensity differences. To improve the robustness to local nonlinear geometric distortions and noises, we design a new edge structure enhanced feature detector and convolutional feature weighted descriptor, respectively. In addition, FILER overcomes the sensitivity of the frequency-domain information to the rotation angle and achieves rotation invariance. Extensive experiments multimodal image pairs show that FILER outperforms other state-of-the-art algorithms and has good robustness and universality.
SpatialMe: Stereo Video Conversion Using Depth-Warping and Blend-Inpainting
Dec 16, 2024Stereo video conversion aims to transform monocular videos into immersive stereo format. Despite the advancements in novel view synthesis, it still remains two major challenges: i) difficulty of achieving high-fidelity and stable results, and ii) insufficiency of high-quality stereo video data. In this paper, we introduce SpatialMe, a novel stereo video conversion framework based on depth-warping and blend-inpainting. Specifically, we propose a mask-based hierarchy feature update (MHFU) refiner, which integrate and refine the outputs from designed multi-branch inpainting module, using feature update unit (FUU) and mask mechanism. We also propose a disparity expansion strategy to address the problem of foreground bleeding. Furthermore, we conduct a high-quality real-world stereo video dataset -- StereoV1K, to alleviate the data shortage. It contains 1000 stereo videos captured in real-world at a resolution of 1180 x 1180, covering various indoor and outdoor scenes. Extensive experiments demonstrate the superiority of our approach in generating stereo videos over state-of-the-art methods.
Enhancing Text-to-SQL Capabilities of Large Language Models via Domain Database Knowledge Injection
Sep 24, 2024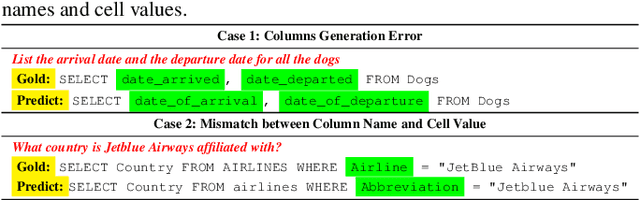

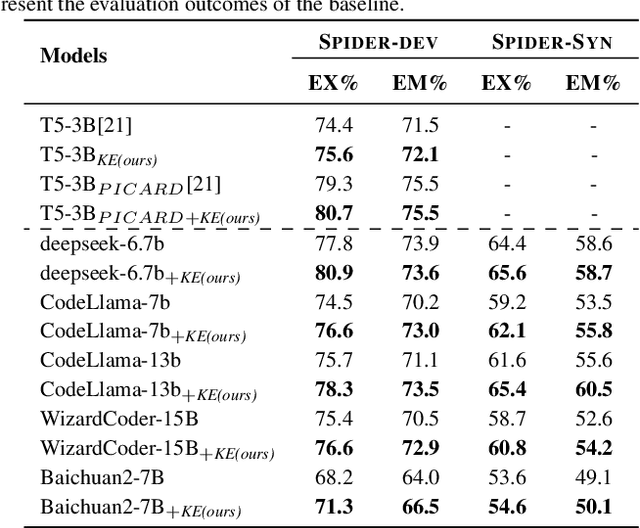
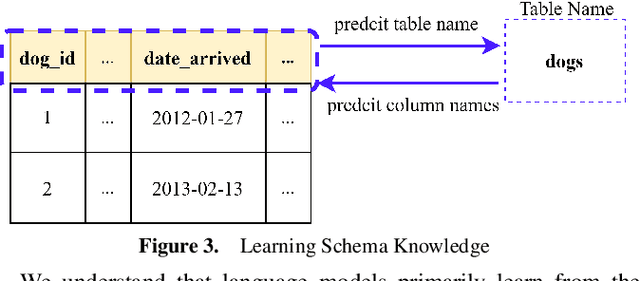
Text-to-SQL is a subtask in semantic parsing that has seen rapid progress with the evolution of Large Language Models (LLMs). However, LLMs face challenges due to hallucination issues and a lack of domain-specific database knowledge(such as table schema and cell values). As a result, they can make errors in generating table names, columns, and matching values to the correct columns in SQL statements. This paper introduces a method of knowledge injection to enhance LLMs' ability to understand schema contents by incorporating prior knowledge. This approach improves their performance in Text-to-SQL tasks. Experimental results show that pre-training LLMs on domain-specific database knowledge and fine-tuning them on downstream Text-to-SQL tasks significantly improves the Execution Match (EX) and Exact Match (EM) metrics across various models. This effectively reduces errors in generating column names and matching values to the columns. Furthermore, the knowledge-injected models can be applied to many downstream Text-to-SQL tasks, demonstrating the generalizability of the approach presented in this paper.
The Quest for Early Detection of Retinal Disease: 3D CycleGAN-based Translation of Optical Coherence Tomography into Confocal Microscopy
Aug 07, 2024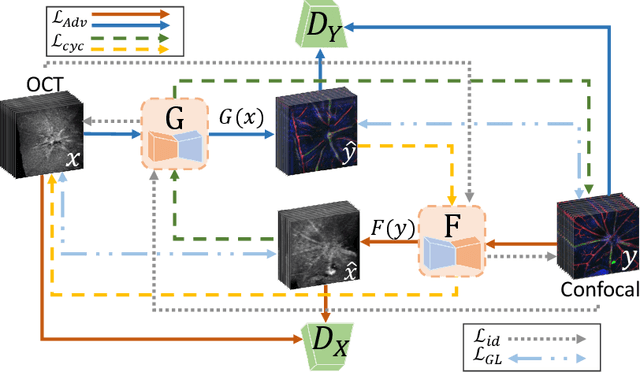



Optical coherence tomography (OCT) and confocal microscopy are pivotal in retinal imaging, offering distinct advantages and limitations. In vivo OCT offers rapid, non-invasive imaging but can suffer from clarity issues and motion artifacts, while ex vivo confocal microscopy, providing high-resolution, cellular-detailed color images, is invasive and raises ethical concerns. To bridge the benefits of both modalities, we propose a novel framework based on unsupervised 3D CycleGAN for translating unpaired in vivo OCT to ex vivo confocal microscopy images. This marks the first attempt to exploit the inherent 3D information of OCT and translate it into the rich, detailed color domain of confocal microscopy. We also introduce a unique dataset, OCT2Confocal, comprising mouse OCT and confocal retinal images, facilitating the development of and establishing a benchmark for cross-modal image translation research. Our model has been evaluated both quantitatively and qualitatively, achieving Fr\'echet Inception Distance (FID) scores of 0.766 and Kernel Inception Distance (KID) scores as low as 0.153, and leading subjective Mean Opinion Scores (MOS). Our model demonstrated superior image fidelity and quality with limited data over existing methods. Our approach effectively synthesizes color information from 3D confocal images, closely approximating target outcomes and suggesting enhanced potential for diagnostic and monitoring applications in ophthalmology.
TaGAT: Topology-Aware Graph Attention Network For Multi-modal Retinal Image Fusion
Jul 19, 2024
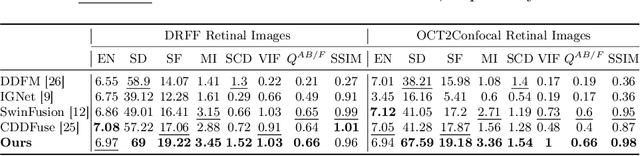


In the realm of medical image fusion, integrating information from various modalities is crucial for improving diagnostics and treatment planning, especially in retinal health, where the important features exhibit differently in different imaging modalities. Existing deep learning-based approaches insufficiently focus on retinal image fusion, and thus fail to preserve enough anatomical structure and fine vessel details in retinal image fusion. To address this, we propose the Topology-Aware Graph Attention Network (TaGAT) for multi-modal retinal image fusion, leveraging a novel Topology-Aware Encoder (TAE) with Graph Attention Networks (GAT) to effectively enhance spatial features with retinal vasculature's graph topology across modalities. The TAE encodes the base and detail features, extracted via a Long-short Range (LSR) encoder from retinal images, into the graph extracted from the retinal vessel. Within the TAE, the GAT-based Graph Information Update (GIU) block dynamically refines and aggregates the node features to generate topology-aware graph features. The updated graph features with base and detail features are combined and decoded as a fused image. Our model outperforms state-of-the-art methods in Fluorescein Fundus Angiography (FFA) with Color Fundus (CF) and Optical Coherence Tomography (OCT) with confocal microscopy retinal image fusion. The source code can be accessed via https://github.com/xintian-99/TaGAT.
Hybrid Spatial-spectral Neural Network for Hyperspectral Image Denoising
Jun 13, 2024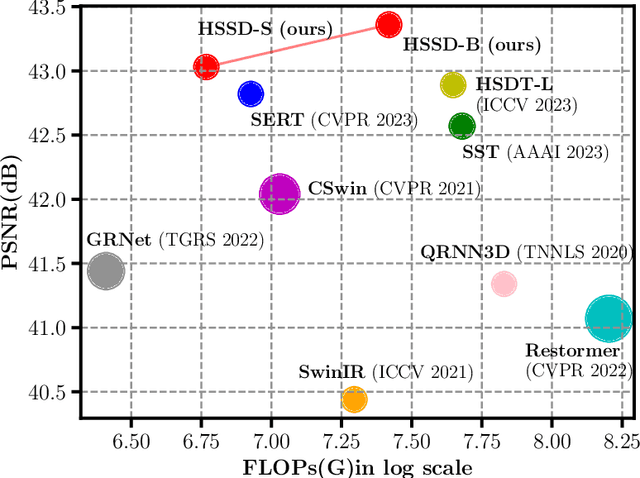
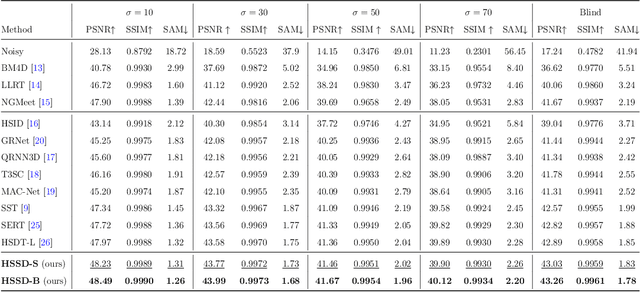
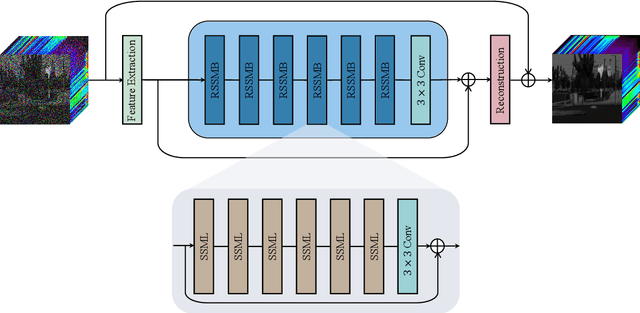
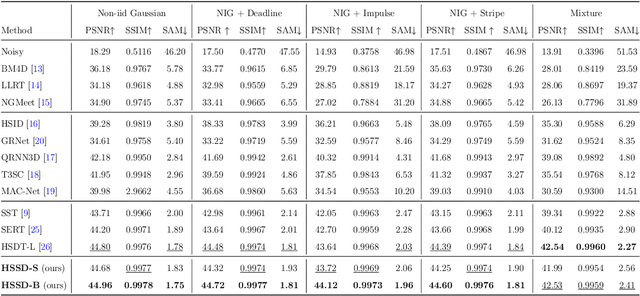
Hyperspectral image (HSI) denoising is an essential procedure for HSI applications. Unfortunately, the existing Transformer-based methods mainly focus on non-local modeling, neglecting the importance of locality in image denoising. Moreover, deep learning methods employ complex spectral learning mechanisms, thus introducing large computation costs. To address these problems, we propose a hybrid spatial-spectral denoising network (HSSD), in which we design a novel hybrid dual-path network inspired by CNN and Transformer characteristics, leading to capturing both local and non-local spatial details while suppressing noise efficiently. Furthermore, to reduce computational complexity, we adopt a simple but effective decoupling strategy that disentangles the learning of space and spectral channels, where multilayer perception with few parameters is utilized to learn the global correlations among spectra. The synthetic and real experiments demonstrate that our proposed method outperforms state-of-the-art methods on spatial and spectral reconstruction. The code and details are available on https://github.com/HLImg/HSSD.