 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaGAT: Topology-Aware Graph Attention Network For Multi-modal Retinal Image Fusion
Paper and Code

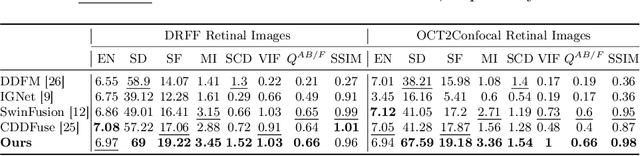


In the realm of medical image fusion, integrating information from various modalities is crucial for improving diagnostics and treatment planning, especially in retinal health, where the important features exhibit differently in different imaging modalities. Existing deep learning-based approaches insufficiently focus on retinal image fusion, and thus fail to preserve enough anatomical structure and fine vessel details in retinal image fusion. To address this, we propose the Topology-Aware Graph Attention Network (TaGAT) for multi-modal retinal image fusion, leveraging a novel Topology-Aware Encoder (TAE) with Graph Attention Networks (GAT) to effectively enhance spatial features with retinal vasculature's graph topology across modalities. The TAE encodes the base and detail features, extracted via a Long-short Range (LSR) encoder from retinal images, into the graph extracted from the retinal vessel. Within the TAE, the GAT-based Graph Information Update (GIU) block dynamically refines and aggregates the node features to generate topology-aware graph features. The updated graph features with base and detail features are combined and decoded as a fused image. Our model outperforms state-of-the-art methods in Fluorescein Fundus Angiography (FFA) with Color Fundus (CF) and Optical Coherence Tomography (OCT) with confocal microscopy retinal image fusion. The source code can be accessed via https://github.com/xintian-99/TaGAT.