 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNASTaR: NovaSAR Automated Ship Target Recognition Dataset
Dec 20, 2025Synthetic Aperture Radar (SAR) offers a unique capability for all-weather, space-based maritime activity monitoring by capturing and imaging strong reflections from ships at sea. A well-defined challenge in this domain is ship type classification. Due to the high diversity and complexity of ship types, accurate recognition is difficult and typically requires specialized deep learning models. These models, however, depend on large, high-quality ground-truth datasets to achieve robust performance and generalization. Furthermore, the growing variety of SAR satellites operating at different frequencies and spatial resolutions has amplified the need for more annotated datasets to enhance model accuracy. To address this, we present the NovaSAR Automated Ship Target Recognition (NASTaR) dataset. This dataset comprises of 3415 ship patches extracted from NovaSAR S-band imagery, with labels matched to AIS data. It includes distinctive features such as 23 unique classes, inshore/offshore separation, and an auxiliary wake dataset for patches where ship wakes are visible. We validated the dataset applicability across prominent ship-type classification scenarios using benchmark deep learning models. Results demonstrate over 60% accuracy for classifying four major ship types, over 70% for a three-class scenario, more than 75% for distinguishing cargo from tanker ships, and over 87% for identifying fishing vessels. The NASTaR dataset is available at https://10.5523/bris, while relevant codes for benchmarking and analysis are available at https://github.com/benyaminhosseiny/nastar.
Physics-Informed Diffusion Models for SAR Ship Wake Generation from Text Prompts
Apr 28, 2025Detecting ship presence via wake signatures in SAR imagery is attracting considerable research interest, but limited annotated data availability poses significant challenges for supervised learning. Physics-based simulations are commonly used to address this data scarcity, although they are slow and constrain end-to-end learning. In this work, we explore a new direction for more efficient and end-to-end SAR ship wake simulation using a diffusion model trained on data generated by a physics-based simulator. The training dataset is built by pairing images produced by the simulator with text prompts derived from simulation parameters. Experimental result show that the model generates realistic Kelvin wake patterns and achieves significantly faster inference than the physics-based simulator. These results highlight the potential of diffusion models for fast and controllable wake image generation, opening new possibilities for end-to-end downstream tasks in maritime SAR analysis.
R-Sparse R-CNN: SAR Ship Detection Based on Background-Aware Sparse Learnable Proposals
Apr 26, 2025We introduce R-Sparse R-CNN, a novel pipeline for oriented ship detection in Synthetic Aperture Radar (SAR) images that leverages sparse learnable proposals enriched with background contextual information, termed background-aware proposals (BAPs). The adoption of sparse proposals streamlines the pipeline by eliminating the need for proposal generators and post-processing for overlapping predictions. The proposed BAPs enrich object representation by integrating ship and background features, allowing the model to learn their contextual relationships for more accurate distinction of ships in complex environments. To complement BAPs, we propose Dual-Context Pooling (DCP), a novel strategy that jointly extracts ship and background features in a single unified operation. This unified design improves efficiency by eliminating redundant computation inherent in separate pooling. Moreover, by ensuring that ship and background features are pooled from the same feature map level, DCP provides aligned features that improve contextual relationship learning. Finally, as a core component of contextual relationship learning in R-Sparse R-CNN, we design a dedicated transformer-based Interaction Module. This module interacts pooled ship and background features with corresponding proposal features and models their relationships. Experimental results show that R-Sparse R-CNN delivers outstanding accuracy, surpassing state-of-the-art models by margins of up to 12.8% and 11.9% on SSDD and RSDD-SAR inshore datasets, respectively. These results demonstrate the effectiveness and competitiveness of R-Sparse R-CNN as a robust framework for oriented ship detection in SAR imagery. The code is available at: www.github.com/ka-mirul/R-Sparse-R-CNN.
Diffusion Probabilistic Models for Compressive SAR Imaging
Apr 23, 2025Compressed sensing Synthetic Aperture Radar (SAR) image formation, formulated as an inverse problem and solved with traditional iterative optimization methods can be very computationally expensive. We investigate the use of denoising diffusion probabilistic models for compressive SAR image reconstruction, where the diffusion model is guided by a poor initial reconstruction from sub-sampled data obtained via standard imaging methods. We present results on real SAR data and compare our compressively sampled diffusion model reconstruction with standard image reconstruction methods utilizing the full data set, demonstrating the potential performance gains in imaging quality.
Improved Patch Denoising Diffusion Probabilistic Models for Magnetic Resonance Fingerprinting
Oct 29, 2024


Magnetic Resonance Fingerprinting (MRF) is a time-efficient approach to quantitative MRI, enabling the mapping of multiple tissue properties from a single, accelerated scan. However, achieving accurate reconstructions remains challenging, particularly in highly accelerated and undersampled acquisitions, which are crucial for reducing scan times. While deep learning techniques have advanced image reconstruction, the recent introduction of diffusion models offers new possibilities for imaging tasks, though their application in the medical field is still emerging. Notably, diffusion models have not yet been explored for the MRF problem. In this work, we propose for the first time a conditional diffusion probabilistic model for MRF image reconstruction. Qualitative and quantitative comparisons on in-vivo brain scan data demonstrate that the proposed approach can outperform established deep learning and compressed sensing algorithms for MRF reconstruction. Extensive ablation studies also explore strategies to improve computational efficiency of our approach.
A Multimodal Approach for Fluid Overload Prediction: Integrating Lung Ultrasound and Clinical Data
Sep 13, 2024

Managing fluid balance in dialysis patients is crucial, as improper management can lead to severe complications. In this paper, we propose a multimodal approach that integrates visual features from lung ultrasound images with clinical data to enhance the prediction of excess body fluid. Our framework employs independent encoders to extract features for each modality and combines them through a cross-domain attention mechanism to capture complementary information. By framing the prediction as a classification task, the model achieves significantly better performance than regression. The results demonstrate that multimodal models consistently outperform single-modality models, particularly when attention mechanisms prioritize tabular data. Pseudo-sample generation further contributes to mitigating the imbalanced classification problem, achieving the highest accuracy of 88.31%. This study underscores the effectiveness of multimodal learning for fluid overload management in dialysis patients, offering valuable insights for improved clinical outcomes.
Sparse R-CNN OBB: Ship Target Detection in SAR Images Based on Oriented Sparse Proposals
Sep 12, 2024We present Sparse R-CNN OBB, a novel framework for the detection of oriented objects in SAR images leveraging sparse learnable proposals. The Sparse R-CNN OBB has streamlined architecture and ease of training as it utilizes a sparse set of 300 proposals instead of training a proposals generator on hundreds of thousands of anchors. To the best of our knowledge, Sparse R-CNN OBB is the first to adopt the concept of sparse learnable proposals for the detection of oriented objects, as well as for the detection of ships in Synthetic Aperture Radar (SAR) images. The detection head of the baseline model, Sparse R-CNN, is re-designed to enable the model to capture object orientation. We also fine-tune the model on RSDD-SAR dataset and provide a performance comparison to state-of-the-art models. Experimental results shows that Sparse R-CNN OBB achieves outstanding performance, surpassing other models on both inshore and offshore scenarios. The code is available at: www.github.com/ka-mirul/Sparse-R-CNN-OBB.
The Quest for Early Detection of Retinal Disease: 3D CycleGAN-based Translation of Optical Coherence Tomography into Confocal Microscopy
Aug 07, 2024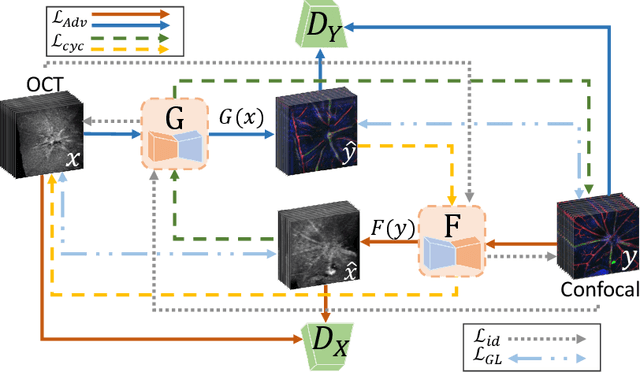



Optical coherence tomography (OCT) and confocal microscopy are pivotal in retinal imaging, offering distinct advantages and limitations. In vivo OCT offers rapid, non-invasive imaging but can suffer from clarity issues and motion artifacts, while ex vivo confocal microscopy, providing high-resolution, cellular-detailed color images, is invasive and raises ethical concerns. To bridge the benefits of both modalities, we propose a novel framework based on unsupervised 3D CycleGAN for translating unpaired in vivo OCT to ex vivo confocal microscopy images. This marks the first attempt to exploit the inherent 3D information of OCT and translate it into the rich, detailed color domain of confocal microscopy. We also introduce a unique dataset, OCT2Confocal, comprising mouse OCT and confocal retinal images, facilitating the development of and establishing a benchmark for cross-modal image translation research. Our model has been evaluated both quantitatively and qualitatively, achieving Fr\'echet Inception Distance (FID) scores of 0.766 and Kernel Inception Distance (KID) scores as low as 0.153, and leading subjective Mean Opinion Scores (MOS). Our model demonstrated superior image fidelity and quality with limited data over existing methods. Our approach effectively synthesizes color information from 3D confocal images, closely approximating target outcomes and suggesting enhanced potential for diagnostic and monitoring applications in ophthalmology.
TaGAT: Topology-Aware Graph Attention Network For Multi-modal Retinal Image Fusion
Jul 19, 2024
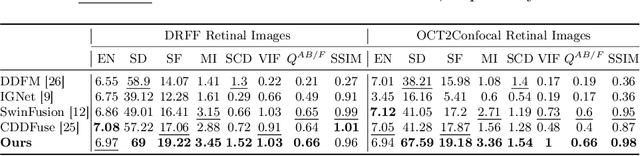


In the realm of medical image fusion, integrating information from various modalities is crucial for improving diagnostics and treatment planning, especially in retinal health, where the important features exhibit differently in different imaging modalities. Existing deep learning-based approaches insufficiently focus on retinal image fusion, and thus fail to preserve enough anatomical structure and fine vessel details in retinal image fusion. To address this, we propose the Topology-Aware Graph Attention Network (TaGAT) for multi-modal retinal image fusion, leveraging a novel Topology-Aware Encoder (TAE) with Graph Attention Networks (GAT) to effectively enhance spatial features with retinal vasculature's graph topology across modalities. The TAE encodes the base and detail features, extracted via a Long-short Range (LSR) encoder from retinal images, into the graph extracted from the retinal vessel. Within the TAE, the GAT-based Graph Information Update (GIU) block dynamically refines and aggregates the node features to generate topology-aware graph features. The updated graph features with base and detail features are combined and decoded as a fused image. Our model outperforms state-of-the-art methods in Fluorescein Fundus Angiography (FFA) with Color Fundus (CF) and Optical Coherence Tomography (OCT) with confocal microscopy retinal image fusion. The source code can be accessed via https://github.com/xintian-99/TaGAT.
DUCPS: Deep Unfolding the Cauchy Proximal Splitting Algorithm for B-Lines Quantification in Lung Ultrasound Images
Jul 16, 2024The identification of artefacts, particularly B-lines, in lung ultrasound (LUS), is crucial for assisting clinical diagnosis, prompting the development of innovative methodologies. While the Cauchy proximal splitting (CPS) algorithm has demonstrated effective performance in B-line detection, the process is slow and has limited generalization. This paper addresses these issues with a novel unsupervised deep unfolding network structure (DUCPS). The framework utilizes deep unfolding procedures to merge traditional model-based techniques with deep learning approaches. By unfolding the CPS algorithm into a deep network, DUCPS enables the parameters in the optimization algorithm to be learnable, thus enhancing generalization performance and facilitating rapid convergence. We conducted entirely unsupervised training using the Neighbor2Neighbor (N2N) and the Structural Similarity Index Measure (SSIM) losses. When combined with an improved line identification method proposed in this paper, state-of-the-art performance is achieved, with the recall and F2 score reaching 0.70 and 0.64, respectively. Notably, DUCPS significantly improves computational efficiency eliminating the need for extensive data labeling, representing a notable advancement over both traditional algorithms and existing deep learning approaches.