 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to reason about rare diseases through retrieval-augmented agents
Nov 06, 2025Rare diseases represent the long tail of medical imaging, where AI models often fail due to the scarcity of representative training data. In clinical workflows, radiologists frequently consult case reports and literature when confronted with unfamiliar findings. Following this line of reasoning, we introduce RADAR, Retrieval Augmented Diagnostic Reasoning Agents, an agentic system for rare disease detection in brain MRI. Our approach uses AI agents with access to external medical knowledge by embedding both case reports and literature using sentence transformers and indexing them with FAISS to enable efficient similarity search. The agent retrieves clinically relevant evidence to guide diagnostic decision making on unseen diseases, without the need of additional training. Designed as a model-agnostic reasoning module, RADAR can be seamlessly integrated with diverse large language models, consistently improving their rare pathology recognition and interpretability. On the NOVA dataset comprising 280 distinct rare diseases, RADAR achieves up to a 10.2% performance gain, with the strongest improvements observed for open source models such as DeepSeek. Beyond accuracy, the retrieved examples provide interpretable, literature grounded explanations, highlighting retrieval-augmented reasoning as a powerful paradigm for low-prevalence conditions in medical imaging.
INR meets Multi-Contrast MRI Reconstruction
Sep 05, 2025Multi-contrast MRI sequences allow for the acquisition of images with varying tissue contrast within a single scan. The resulting multi-contrast images can be used to extract quantitative information on tissue microstructure. To make such multi-contrast sequences feasible for clinical routine, the usually very long scan times need to be shortened e.g. through undersampling in k-space. However, this comes with challenges for the reconstruction. In general, advanced reconstruction techniques such as compressed sensing or deep learning-based approaches can enable the acquisition of high-quality images despite the acceleration. In this work, we leverage redundant anatomical information of multi-contrast sequences to achieve even higher acceleration rates. We use undersampling patterns that capture the contrast information located at the k-space center, while performing complementary undersampling across contrasts for high frequencies. To reconstruct this highly sparse k-space data, we propose an implicit neural representation (INR) network that is ideal for using the complementary information acquired across contrasts as it jointly reconstructs all contrast images. We demonstrate the benefits of our proposed INR method by applying it to multi-contrast MRI using the MPnRAGE sequence, where it outperforms the state-of-the-art parallel imaging compressed sensing (PICS) reconstruction method, even at higher acceleration factors.
Improved Patch Denoising Diffusion Probabilistic Models for Magnetic Resonance Fingerprinting
Oct 29, 2024

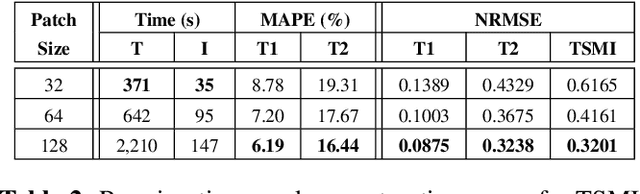

Magnetic Resonance Fingerprinting (MRF) is a time-efficient approach to quantitative MRI, enabling the mapping of multiple tissue properties from a single, accelerated scan. However, achieving accurate reconstructions remains challenging, particularly in highly accelerated and undersampled acquisitions, which are crucial for reducing scan times. While deep learning techniques have advanced image reconstruction, the recent introduction of diffusion models offers new possibilities for imaging tasks, though their application in the medical field is still emerging. Notably, diffusion models have not yet been explored for the MRF problem. In this work, we propose for the first time a conditional diffusion probabilistic model for MRF image reconstruction. Qualitative and quantitative comparisons on in-vivo brain scan data demonstrate that the proposed approach can outperform established deep learning and compressed sensing algorithms for MRF reconstruction. Extensive ablation studies also explore strategies to improve computational efficiency of our approach.
StoDIP: Efficient 3D MRF image reconstruction with deep image priors and stochastic iterations
Aug 05, 2024


Magnetic Resonance Fingerprinting (MRF) is a time-efficient approach to quantitative MRI for multiparametric tissue mapping. The reconstruction of quantitative maps requires tailored algorithms for removing aliasing artefacts from the compressed sampled MRF acquisitions. Within approaches found in the literature, many focus solely on two-dimensional (2D) image reconstruction, neglecting the extension to volumetric (3D) scans despite their higher relevance and clinical value. A reason for this is that transitioning to 3D imaging without appropriate mitigations presents significant challenges, including increased computational cost and storage requirements, and the need for large amount of ground-truth (artefact-free) data for training. To address these issues, we introduce StoDIP, a new algorithm that extends the ground-truth-free Deep Image Prior (DIP) reconstruction to 3D MRF imaging. StoDIP employs memory-efficient stochastic updates across the multicoil MRF data, a carefully selected neural network architecture, as well as faster nonuniform FFT (NUFFT) transformations. This enables a faster convergence compared against a conventional DIP implementation without these features. Tested on a dataset of whole-brain scans from healthy volunteers, StoDIP demonstrated superior performance over the ground-truth-free reconstruction baselines, both quantitatively and qualitatively.
Deep Image Priors for Magnetic Resonance Fingerprinting with pretrained Bloch-consistent denoising autoencoders
Jul 29, 2024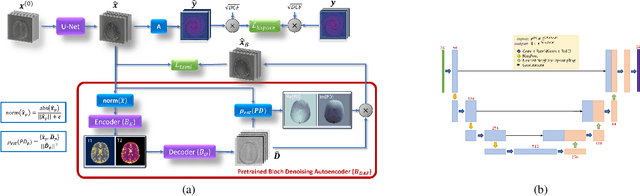
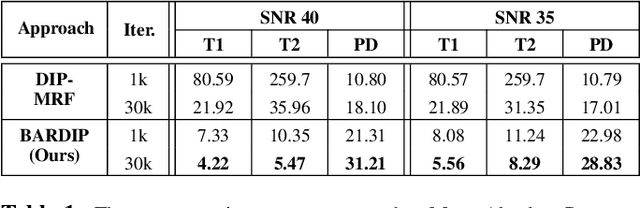

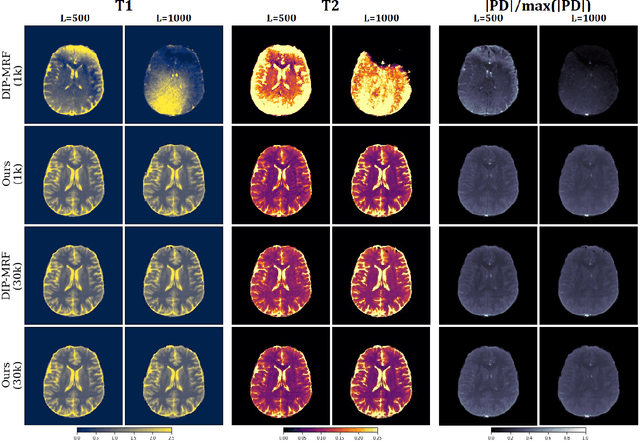
The estimation of multi-parametric quantitative maps from Magnetic Resonance Fingerprinting (MRF) compressed sampled acquisitions, albeit successful, remains a challenge due to the high underspampling rate and artifacts naturally occuring during image reconstruction. Whilst state-of-the-art DL methods can successfully address the task, to fully exploit their capabilities they often require training on a paired dataset, in an area where ground truth is seldom available. In this work, we propose a method that combines a deep image prior (DIP) module that, without ground truth and in conjunction with a Bloch consistency enforcing autoencoder, can tackle the problem, resulting in a method faster and of equivalent or better accuracy than DIP-MRF.
Nonlinear Equivariant Imaging: Learning Multi-Parametric Tissue Mapping without Ground Truth for Compressive Quantitative MRI
Nov 23, 2022Current state-of-the-art reconstruction for quantitative tissue maps from fast, compressive, Magnetic Resonance Fingerprinting (MRF), use supervised deep learning, with the drawback of requiring high-fidelity ground truth tissue map training data which is limited. This paper proposes NonLinear Equivariant Imaging (NLEI), a self-supervised learning approach to eliminate the need for ground truth for deep MRF image reconstruction. NLEI extends the recent Equivariant Imaging framework to nonlinear inverse problems such as MRF. Only fast, compressed-sampled MRF scans are used for training. NLEI learns tissue mapping using spatiotemporal priors: spatial priors are obtained from the invariance of MRF data to a group of geometric image transformations, while temporal priors are obtained from a nonlinear Bloch response model approximated by a pre-trained neural network. Tested retrospectively on two acquisition settings, we observe that NLEI (self-supervised learning) closely approaches the performance of supervised learning, despite not using ground truth during training.
A Plug-and-Play Approach to Multiparametric Quantitative MRI: Image Reconstruction using Pre-Trained Deep Denoisers
Feb 10, 2022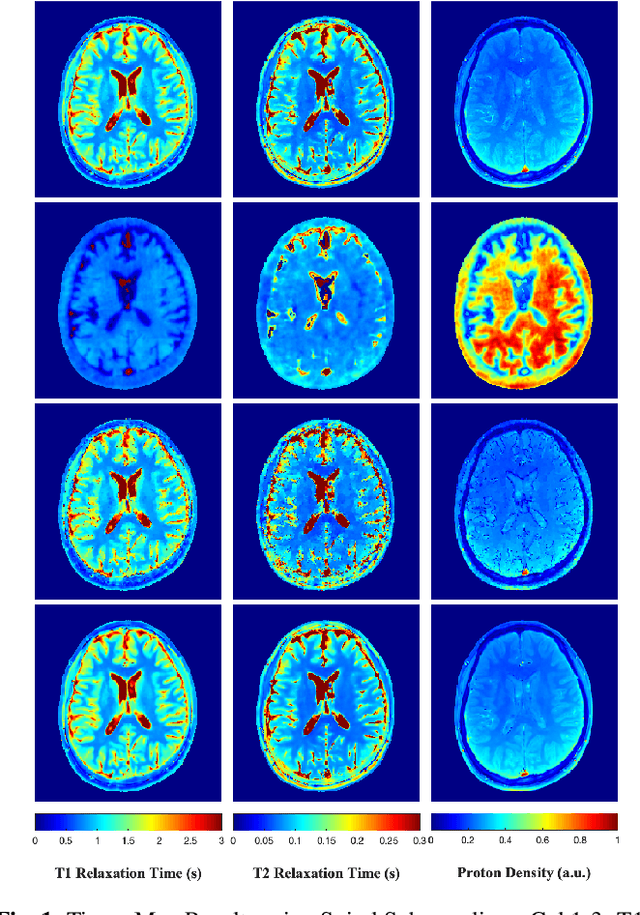
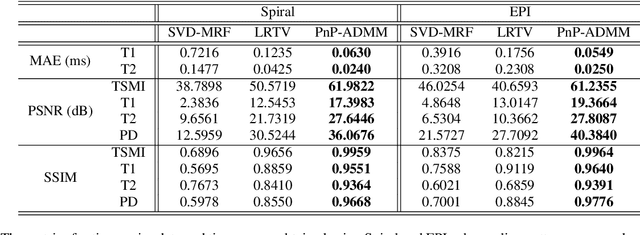
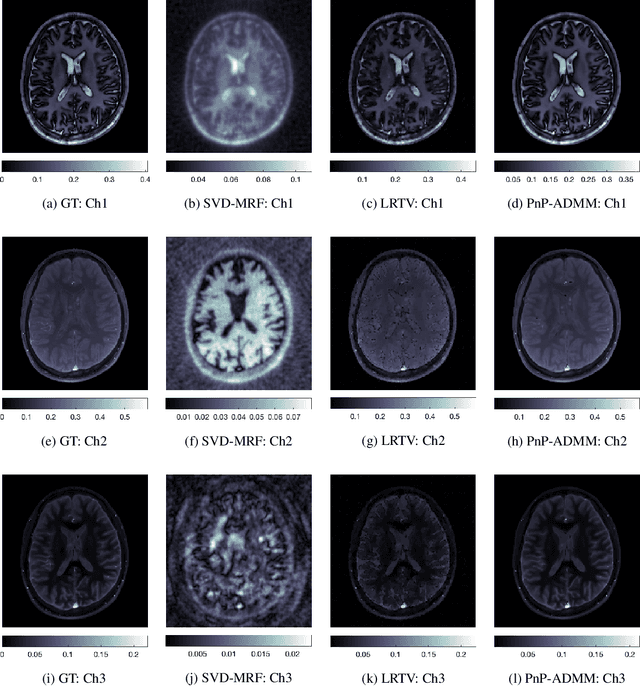
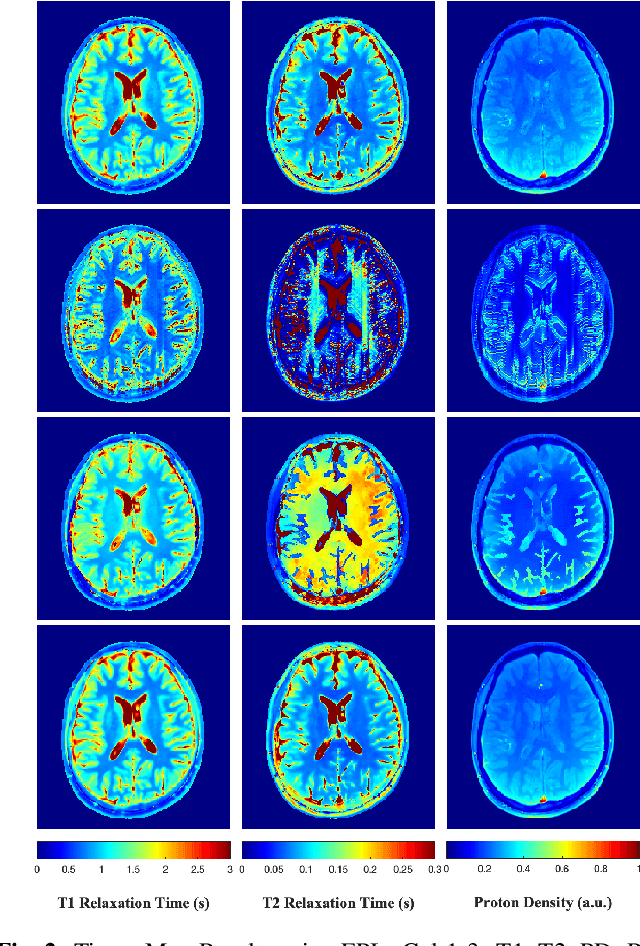
Current spatiotemporal deep learning approaches to Magnetic Resonance Fingerprinting (MRF) build artefact-removal models customised to a particular k-space subsampling pattern which is used for fast (compressed) acquisition. This may not be useful when the acquisition process is unknown during training of the deep learning model and/or changes during testing time. This paper proposes an iterative deep learning plug-and-play reconstruction approach to MRF which is adaptive to the forward acquisition process. Spatiotemporal image priors are learned by an image denoiser i.e. a Convolutional Neural Network (CNN), trained to remove generic white gaussian noise (not a particular subsampling artefact) from data. This CNN denoiser is then used as a data-driven shrinkage operator within the iterative reconstruction algorithm. This algorithm with the same denoiser model is then tested on two simulated acquisition processes with distinct subsampling patterns. The results show consistent de-aliasing performance against both acquisition schemes and accurate mapping of tissues' quantitative bio-properties. Software available: https://github.com/ketanfatania/QMRI-PnP-Recon-POC
Deep MR Fingerprinting with total-variation and low-rank subspace priors
Feb 26, 2019
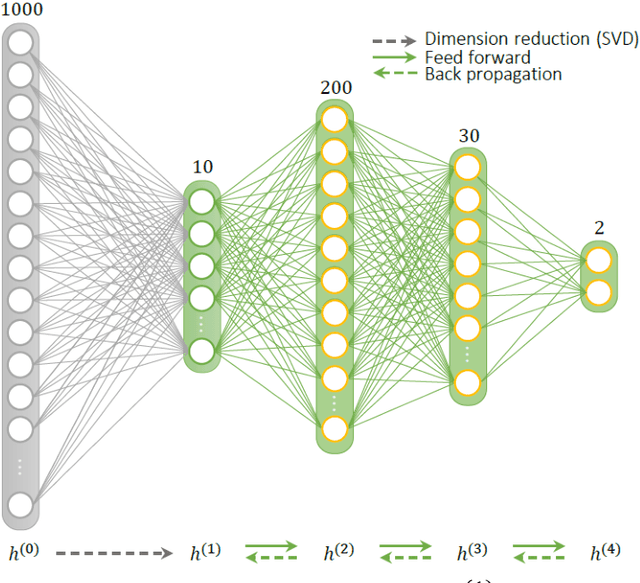
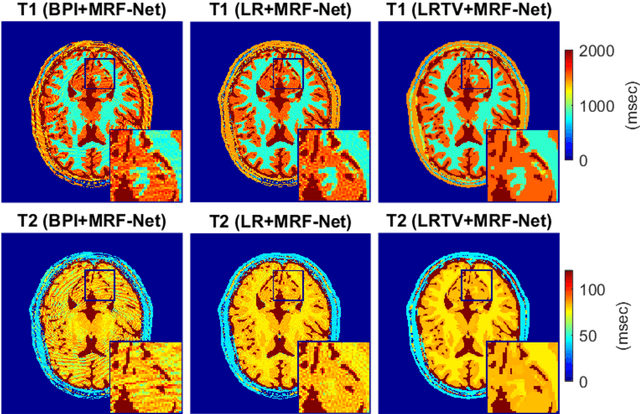
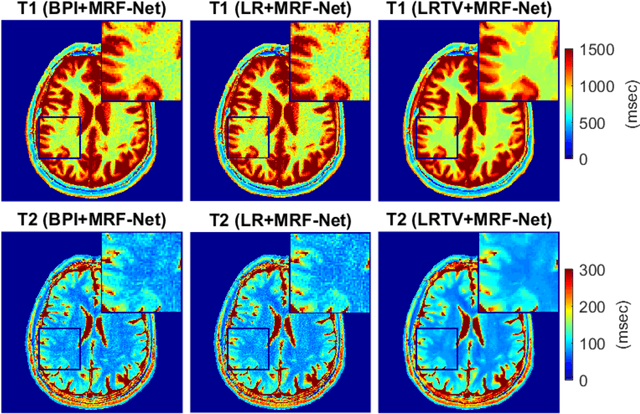
Deep learning (DL) has recently emerged to address the heavy storage and computation requirements of the baseline dictionary-matching (DM) for Magnetic Resonance Fingerprinting (MRF) reconstruction. Fed with non-iterated back-projected images, the network is unable to fully resolve spatially-correlated corruptions caused from the undersampling artefacts. We propose an accelerated iterative reconstruction to minimize these artefacts before feeding into the network. This is done through a convex regularization that jointly promotes spatio-temporal regularities of the MRF time-series. Except for training, the rest of the parameter estimation pipeline is dictionary-free. We validate the proposed approach on synthetic and in-vivo datasets.