 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Pitfalls of "Security by Obscurity" And What They Mean for Transparent AI
Jan 30, 2025Calls for transparency in AI systems are growing in number and urgency from diverse stakeholders ranging from regulators to researchers to users (with a comparative absence of companies developing AI). Notions of transparency for AI abound, each addressing distinct interests and concerns. In computer security, transparency is likewise regarded as a key concept. The security community has for decades pushed back against so-called security by obscurity -- the idea that hiding how a system works protects it from attack -- against significant pressure from industry and other stakeholders. Over the decades, in a community process that is imperfect and ongoing, security researchers and practitioners have gradually built up some norms and practices around how to balance transparency interests with possible negative side effects. This paper asks: What insights can the AI community take from the security community's experience with transparency? We identify three key themes in the security community's perspective on the benefits of transparency and their approach to balancing transparency against countervailing interests. For each, we investigate parallels and insights relevant to transparency in AI. We then provide a case study discussion on how transparency has shaped the research subfield of anonymization. Finally, shifting our focus from similarities to differences, we highlight key transparency issues where modern AI systems present challenges different from other kinds of security-critical systems, raising interesting open questions for the security and AI communities alike.
Nonlinear Equivariant Imaging: Learning Multi-Parametric Tissue Mapping without Ground Truth for Compressive Quantitative MRI
Nov 23, 2022Current state-of-the-art reconstruction for quantitative tissue maps from fast, compressive, Magnetic Resonance Fingerprinting (MRF), use supervised deep learning, with the drawback of requiring high-fidelity ground truth tissue map training data which is limited. This paper proposes NonLinear Equivariant Imaging (NLEI), a self-supervised learning approach to eliminate the need for ground truth for deep MRF image reconstruction. NLEI extends the recent Equivariant Imaging framework to nonlinear inverse problems such as MRF. Only fast, compressed-sampled MRF scans are used for training. NLEI learns tissue mapping using spatiotemporal priors: spatial priors are obtained from the invariance of MRF data to a group of geometric image transformations, while temporal priors are obtained from a nonlinear Bloch response model approximated by a pre-trained neural network. Tested retrospectively on two acquisition settings, we observe that NLEI (self-supervised learning) closely approaches the performance of supervised learning, despite not using ground truth during training.
A Plug-and-Play Approach to Multiparametric Quantitative MRI: Image Reconstruction using Pre-Trained Deep Denoisers
Feb 10, 2022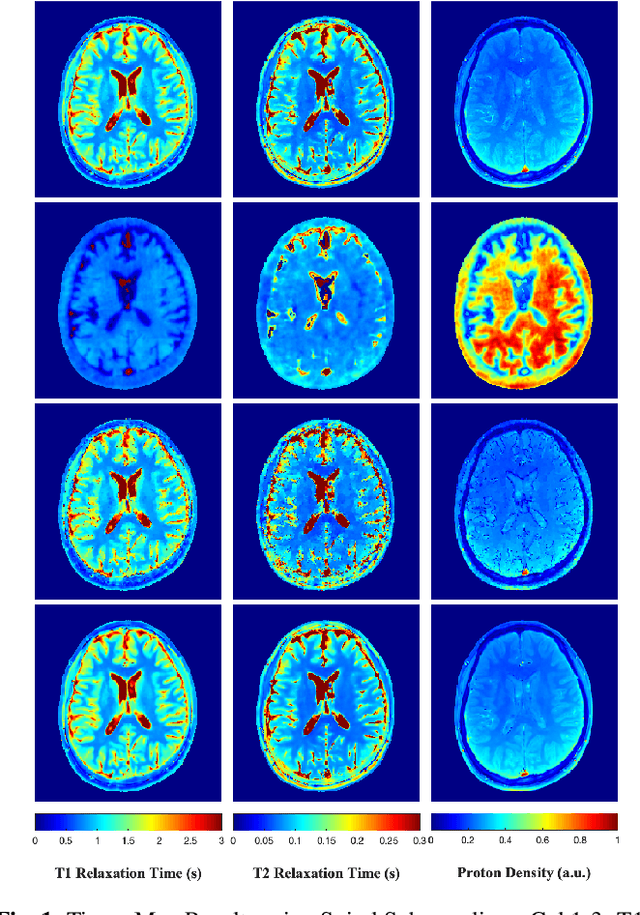
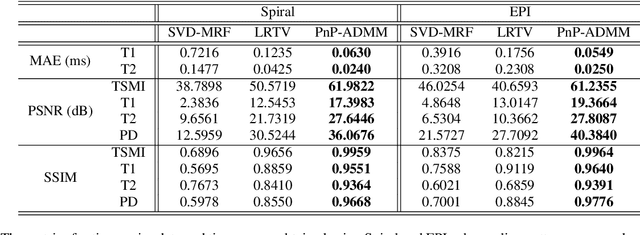
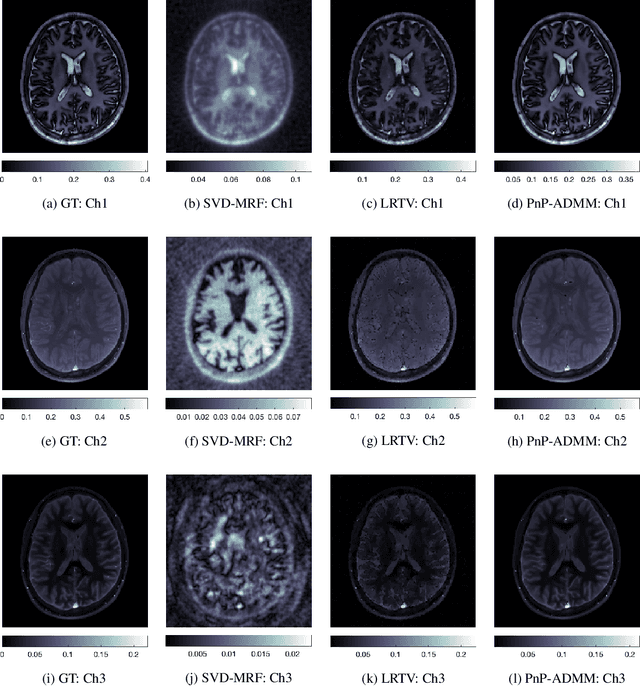
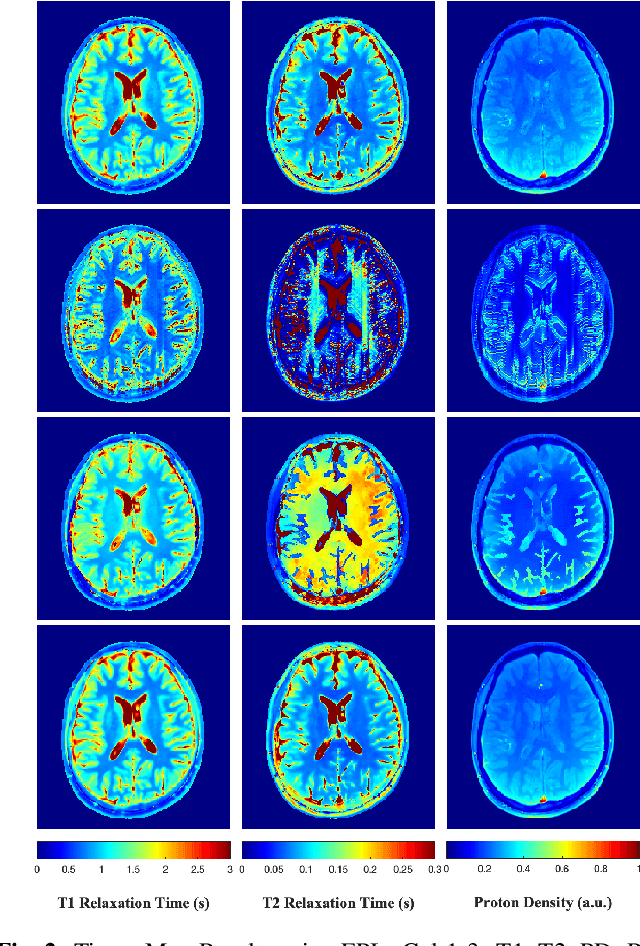
Current spatiotemporal deep learning approaches to Magnetic Resonance Fingerprinting (MRF) build artefact-removal models customised to a particular k-space subsampling pattern which is used for fast (compressed) acquisition. This may not be useful when the acquisition process is unknown during training of the deep learning model and/or changes during testing time. This paper proposes an iterative deep learning plug-and-play reconstruction approach to MRF which is adaptive to the forward acquisition process. Spatiotemporal image priors are learned by an image denoiser i.e. a Convolutional Neural Network (CNN), trained to remove generic white gaussian noise (not a particular subsampling artefact) from data. This CNN denoiser is then used as a data-driven shrinkage operator within the iterative reconstruction algorithm. This algorithm with the same denoiser model is then tested on two simulated acquisition processes with distinct subsampling patterns. The results show consistent de-aliasing performance against both acquisition schemes and accurate mapping of tissues' quantitative bio-properties. Software available: https://github.com/ketanfatania/QMRI-PnP-Recon-POC
Geometric Style Transfer
Jul 10, 2020
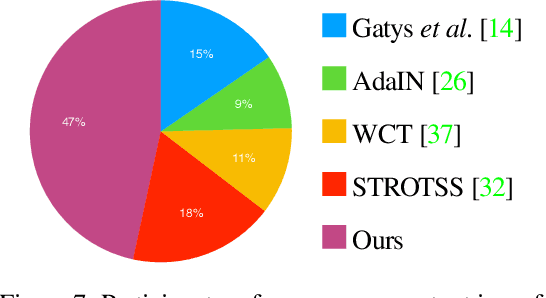
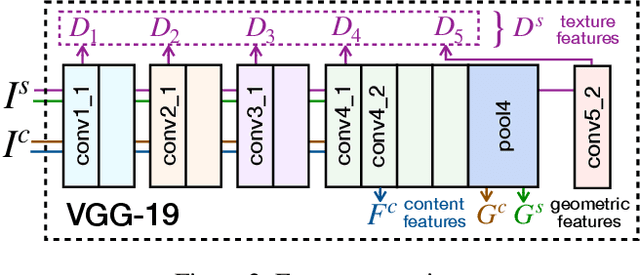
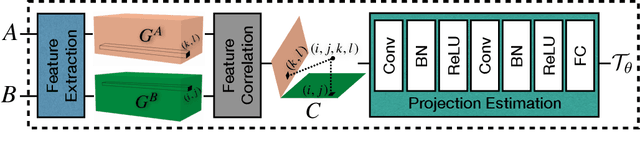
Neural style transfer (NST), where an input image is rendered in the style of another image, has been a topic of considerable progress in recent years. Research over that time has been dominated by transferring aspects of color and texture, yet these factors are only one component of style. Other factors of style include composition, the projection system used, and the way in which artists warp and bend objects. Our contribution is to introduce a neural architecture that supports transfer of geometric style. Unlike recent work in this area, we are unique in being general in that we are not restricted by semantic content. This new architecture runs prior to a network that transfers texture style, enabling us to transfer texture to a warped image. This form of network supports a second novelty: we extend the NST input paradigm. Users can input content/style pair as is common, or they can chose to input a content/texture-style/geometry-style triple. This three image input paradigm divides style into two parts and so provides significantly greater versatility to the output we can produce. We provide user studies that show the quality of our output, and quantify the importance of geometric style transfer to style recognition by humans.
VGPN: Voice-Guided Pointing Robot Navigation for Humans
Apr 03, 2020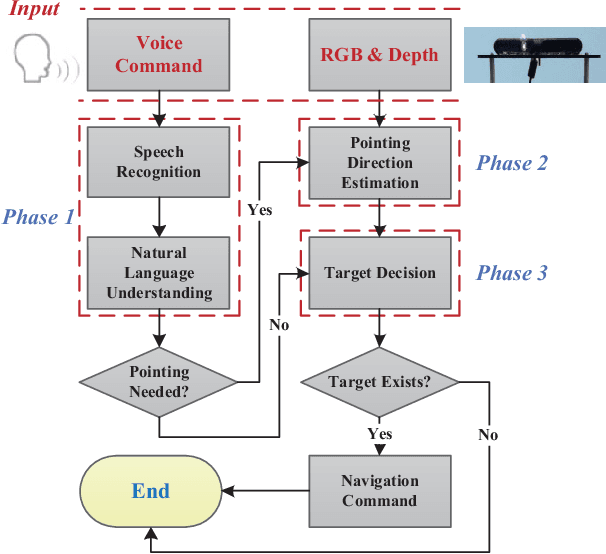
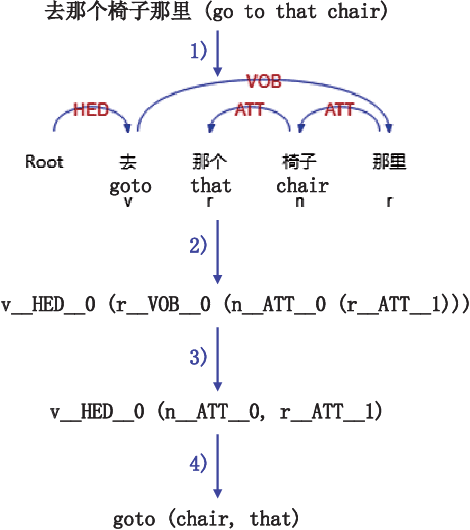


Pointing gestures are widely used in robot navigationapproaches nowadays. However, most approaches only use point-ing gestures, and these have two major limitations. Firstly, they need to recognize pointing gestures all the time, which leads to long processing time and significant system overheads. Secondly,the user's pointing direction may not be very accurate, so the robot may go to an undesired place. To relieve these limitations,we propose a voice-guided pointing robot navigation approach named VGPN, and implement its prototype on a wheeled robot,TurtleBot 2. VGPN recognizes a pointing gesture only if voice information is insufficient for navigation. VGPN also uses voice information as a supplementary channel to help determine the target position of the user's pointing gesture. In the evaluation,we compare VGPN to the pointing-only navigation approach. The results show that VGPN effectively reduces the processing timecost when pointing gesture is unnecessary, and improves the usersatisfaction with navigation accuracy.
Artistic Domain Generalisation Methods are Limited by their Deep Representations
Jul 29, 2019
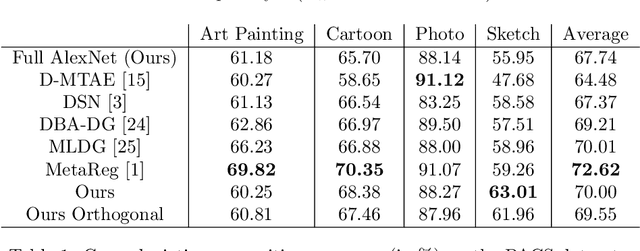

The cross-depiction problem refers to the task of recognising visual objects regardless of their depictions; whether photographed, painted, sketched, {\em etc}. In the past, some researchers considered cross-depiction to be domain adaptation (DA). More recent work considers cross-depiction as domain generalisation (DG), in which algorithms extend recognition from one set of domains (such as photographs and coloured artwork) to another (such as sketches). We show that fixing the last layer of AlexNet to random values provides a performance comparable to state of the art DA and DG algorithms, when tested over the PACS benchmark. With support from background literature, our results lead us to conclude that texture alone is insufficient to support generalisation; rather, higher-order representations such as structure and shape are necessary.
Rank3DGAN: Semantic mesh generation using relative attributes
May 28, 2019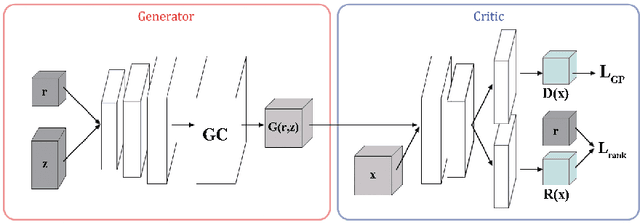

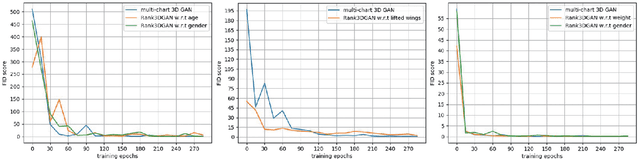
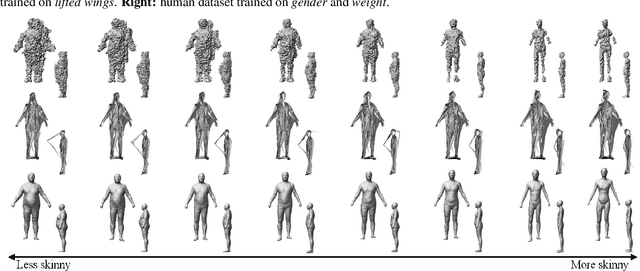
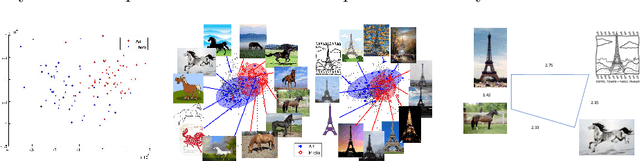
In this paper, we investigate a novel problem of using generative adversarial networks in the task of 3D shape generation according to semantic attributes. Recent works map 3D shapes into 2D parameter domain, which enables training Generative Adversarial Networks (GANs) for 3D shape generation task. We extend these architectures to the conditional setting, where we generate 3D shapes with respect to subjective attributes defined by the user. Given pairwise comparisons of 3D shapes, our model performs two tasks: it learns a generative model with a controlled latent space, and a ranking function for the 3D shapes based on their multi-chart representation in 2D. The capability of the model is demonstrated with experiments on HumanShape, Basel Face Model and reconstructed 3D CUB datasets. We also present various applications that benefit from our model, such as multi-attribute exploration, mesh editing, and mesh attribute transfer.
What and Where: A Context-based Recommendation System for Object Insertion
Nov 24, 2018

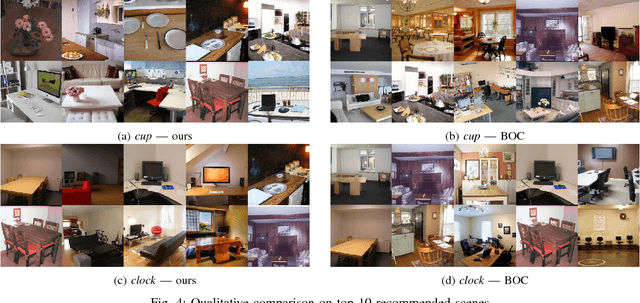

In this work, we propose a novel topic consisting of two dual tasks: 1) given a scene, recommend objects to insert, 2) given an object category, retrieve suitable background scenes. A bounding box for the inserted object is predicted in both tasks, which helps downstream applications such as semi-automated advertising and video composition. The major challenge lies in the fact that the target object is neither present nor localized at test time, whereas available datasets only provide scenes with existing objects. To tackle this problem, we build an unsupervised algorithm based on object-level contexts, which explicitly models the joint probability distribution of object categories and bounding boxes with a Gaussian mixture model. Experiments on our newly annotated test set demonstrate that our system outperforms existing baselines on all subtasks, and do so under a unified framework. Our contribution promises future extensions and applications.
Ranking CGANs: Subjective Control over Semantic Image Attributes
Jul 24, 2018


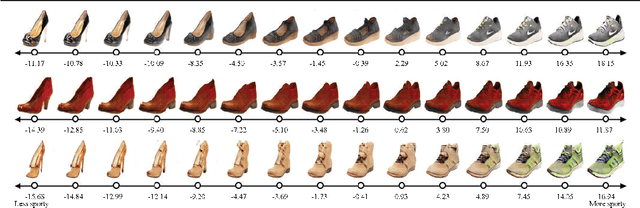
In this paper, we investigate the use of generative adversarial networks in the task of image generation according to subjective measures of semantic attributes. Unlike the standard (CGAN) that generates images from discrete categorical labels, our architecture handles both continuous and discrete scales. Given pairwise comparisons of images, our model, called RankCGAN, performs two tasks: it learns to rank images using a subjective measure; and it learns a generative model that can be controlled by that measure. RankCGAN associates each subjective measure of interest to a distinct dimension of some latent space. We perform experiments on UT-Zap50K, PubFig and OSR datasets and demonstrate that the model is expressive and diverse enough to conduct two-attribute exploration and image editing.
LineNet: a Zoomable CNN for Crowdsourced High Definition Maps Modeling in Urban Environments
Jul 16, 2018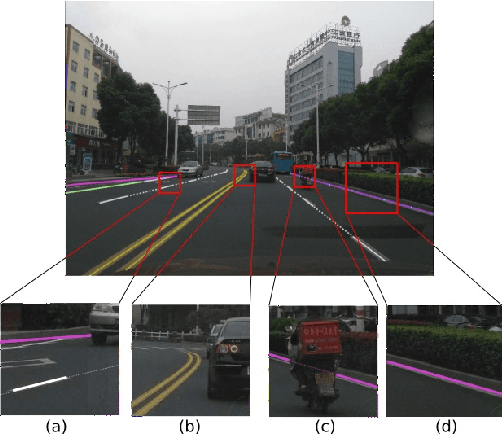
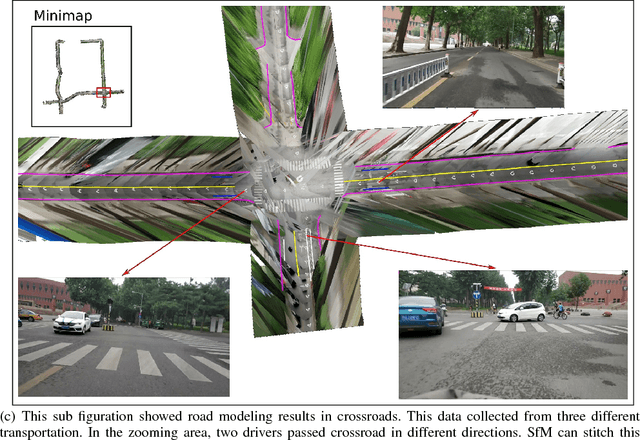
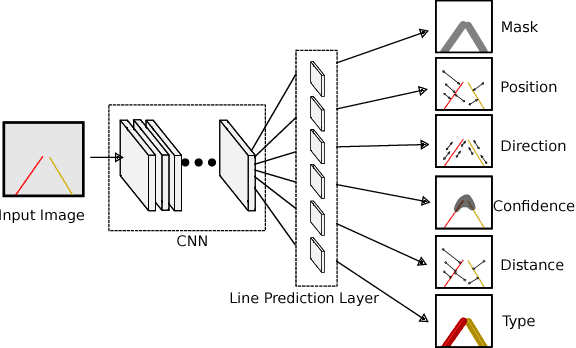
High Definition (HD) maps play an important role in modern traffic scenes. However, the development of HD maps coverage grows slowly because of the cost limitation. To efficiently model HD maps, we proposed a convolutional neural network with a novel prediction layer and a zoom module, called LineNet. It is designed for state-of-the-art lane detection in an unordered crowdsourced image dataset. And we introduced TTLane, a dataset for efficient lane detection in urban road modeling applications. Combining LineNet and TTLane, we proposed a pipeline to model HD maps with crowdsourced data for the first time. And the maps can be constructed precisely even with inaccurate crowdsourced data.