 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Classification-Aware Super-Resolution Framework for Ship Targets in SAR Imagery
Aug 08, 2025High-resolution imagery plays a critical role in improving the performance of visual recognition tasks such as classification, detection, and segmentation. In many domains, including remote sensing and surveillance, low-resolution images can limit the accuracy of automated analysis. To address this, super-resolution (SR) techniques have been widely adopted to attempt to reconstruct high-resolution images from low-resolution inputs. Related traditional approaches focus solely on enhancing image quality based on pixel-level metrics, leaving the relationship between super-resolved image fidelity and downstream classification performance largely underexplored. This raises a key question: can integrating classification objectives directly into the super-resolution process further improve classification accuracy? In this paper, we try to respond to this question by investigating the relationship between super-resolution and classification through the deployment of a specialised algorithmic strategy. We propose a novel methodology that increases the resolution of synthetic aperture radar imagery by optimising loss functions that account for both image quality and classification performance. Our approach improves image quality, as measured by scientifically ascertained image quality indicators, while also enhancing classification accuracy.
Feature-Space Oversampling for Addressing Class Imbalance in SAR Ship Classification
Aug 08, 2025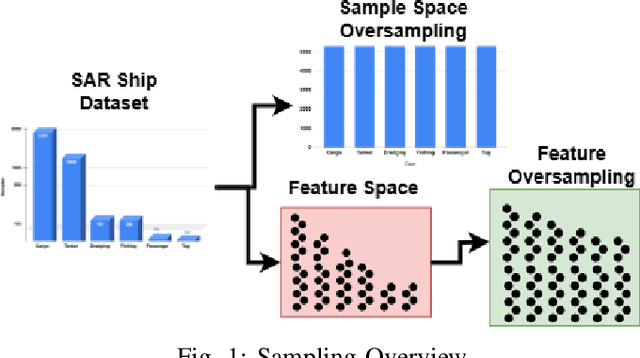
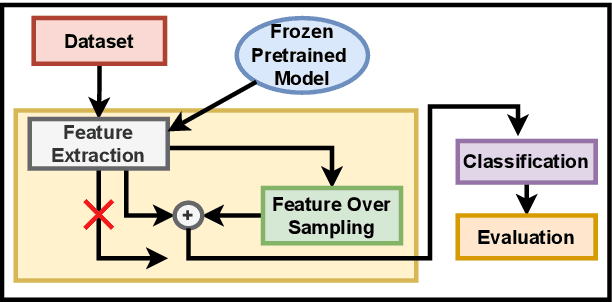
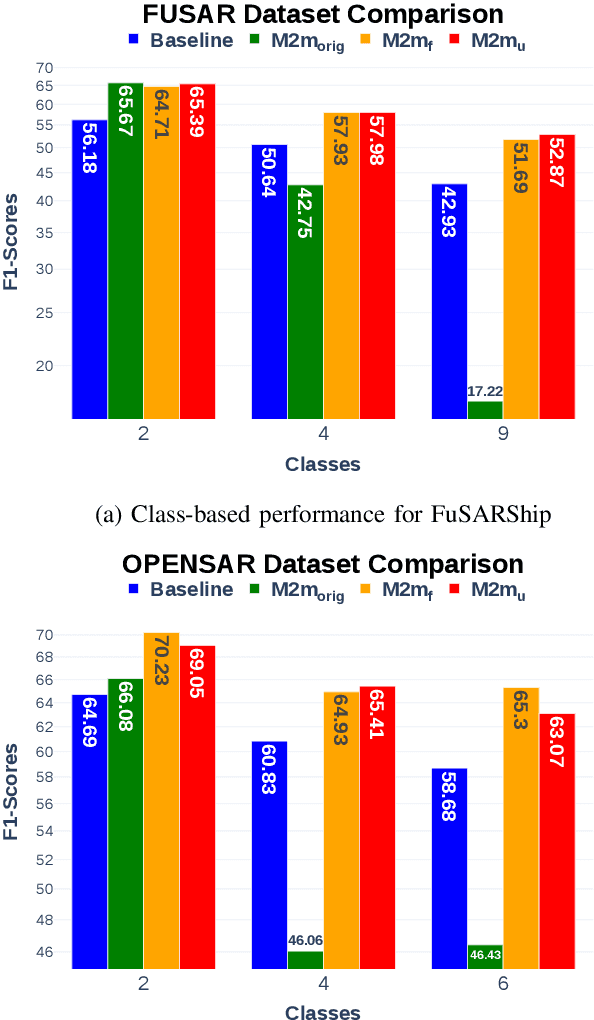
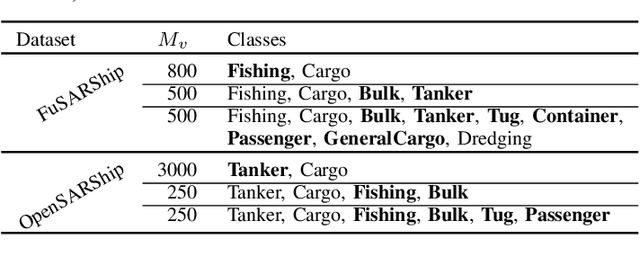
SAR ship classification faces the challenge of long-tailed datasets, which complicates the classification of underrepresented classes. Oversampling methods have proven effective in addressing class imbalance in optical data. In this paper, we evaluated the effect of oversampling in the feature space for SAR ship classification. We propose two novel algorithms inspired by the Major-to-minor (M2m) method M2m$_f$, M2m$_u$. The algorithms are tested on two public datasets, OpenSARShip (6 classes) and FuSARShip (9 classes), using three state-of-the-art models as feature extractors: ViT, VGG16, and ResNet50. Additionally, we also analyzed the impact of oversampling methods on different class sizes. The results demonstrated the effectiveness of our novel methods over the original M2m and baselines, with an average F1-score increase of 8.82% for FuSARShip and 4.44% for OpenSARShip.
Integrating Semi-Supervised and Active Learning for Semantic Segmentation
Jan 31, 2025



In this paper, we propose a novel active learning approach integrated with an improved semi-supervised learning framework to reduce the cost of manual annotation and enhance model performance. Our proposed approach effectively leverages both the labelled data selected through active learning and the unlabelled data excluded from the selection process. The proposed active learning approach pinpoints areas where the pseudo-labels are likely to be inaccurate. Then, an automatic and efficient pseudo-label auto-refinement (PLAR) module is proposed to correct pixels with potentially erroneous pseudo-labels by comparing their feature representations with those of labelled regions. This approach operates without increasing the labelling budget and is based on the cluster assumption, which states that pixels belonging to the same class should exhibit similar representations in feature space. Furthermore, manual labelling is only applied to the most difficult and uncertain areas in unlabelled data, where insufficient information prevents the PLAR module from making a decision. We evaluated the proposed hybrid semi-supervised active learning framework on two benchmark datasets, one from natural and the other from remote sensing imagery domains. In both cases, it outperformed state-of-the-art methods in the semantic segmentation task.
Patch-GAN Transfer Learning with Reconstructive Models for Cloud Removal
Jan 09, 2025Cloud removal plays a crucial role in enhancing remote sensing image analysis, yet accurately reconstructing cloud-obscured regions remains a significant challenge. Recent advancements in generative models have made the generation of realistic images increasingly accessible, offering new opportunities for this task. Given the conceptual alignment between image generation and cloud removal tasks, generative models present a promising approach for addressing cloud removal in remote sensing. In this work, we propose a deep transfer learning approach built on a generative adversarial network (GAN) framework to explore the potential of the novel masked autoencoder (MAE) image reconstruction model in cloud removal. Due to the complexity of remote sensing imagery, we further propose using a patch-wise discriminator to determine whether each patch of the image is real or not. The proposed reconstructive transfer learning approach demonstrates significant improvements in cloud removal performance compared to other GAN-based methods. Additionally, whilst direct comparisons with some of the state-of-the-art cloud removal techniques are limited due to unclear details regarding their train/test data splits, the proposed model achieves competitive results based on available benchmarks.
Quantifying Extreme Opinions on Reddit Amidst the 2023 Israeli-Palestinian Conflict
Dec 14, 2024This study investigates the dynamics of extreme opinions on social media during the 2023 Israeli-Palestinian conflict, utilising a comprehensive dataset of over 450,000 posts from four Reddit subreddits (r/Palestine, r/Judaism, r/IsraelPalestine, and r/worldnews). A lexicon-based, unsupervised methodology was developed to measure "extreme opinions" by considering factors such as anger, polarity, and subjectivity. The analysis identifies significant peaks in extremism scores that correspond to pivotal real-life events, such as the IDF's bombings of Al Quds Hospital and the Jabalia Refugee Camp, and the end of a ceasefire following a terrorist attack. Additionally, this study explores the distribution and correlation of these scores across different subreddits and over time, providing insights into the propagation of polarised sentiments in response to conflict events. By examining the quantitative effects of each score on extremism and analysing word cloud similarities through Jaccard indices, the research offers a nuanced understanding of the factors driving extreme online opinions. This approach underscores the potential of social media analytics in capturing the complex interplay between real-world events and online discourse, while also highlighting the limitations and challenges of measuring extremism in social media contexts.
RKFNet: A Novel Neural Network Aided Robust Kalman Filter
Mar 25, 2024Driven by the filtering challenges in linear systems disturbed by non-Gaussian heavy-tailed noise, the robust Kalman filters (RKFs) leveraging diverse heavy-tailed distributions have been introduced. However, the RKFs rely on precise noise models, and large model errors can degrade their filtering performance. Also, the posterior approximation by the employed variational Bayesian (VB) method can further decrease the estimation precision. Here, we introduce an innovative RKF method, the RKFNet, which combines the heavy-tailed-distribution-based RKF framework with the deep learning (DL) technique and eliminates the need for the precise parameters of the heavy-tailed distributions. To reduce the VB approximation error, the mixing-parameter-based function and the scale matrix are estimated by the incorporated neural network structures. Also, the stable training process is achieved by our proposed unsupervised scheduled sampling (USS) method, where a loss function based on the Student's t (ST) distribution is utilised to overcome the disturbance of the noise outliers and the filtering results of the traditional RKFs are employed as reference sequences. Furthermore, the RKFNet is evaluated against various RKFs and recurrent neural networks (RNNs) under three kinds of heavy-tailed measurement noises, and the simulation results showcase its efficacy in terms of estimation accuracy and efficiency.
Knowledge Distillation for Road Detection based on cross-model Semi-Supervised Learning
Feb 07, 2024The advancement of knowledge distillation has played a crucial role in enabling the transfer of knowledge from larger teacher models to smaller and more efficient student models, and is particularly beneficial for online and resource-constrained applications. The effectiveness of the student model heavily relies on the quality of the distilled knowledge received from the teacher. Given the accessibility of unlabelled remote sensing data, semi-supervised learning has become a prevalent strategy for enhancing model performance. However, relying solely on semi-supervised learning with smaller models may be insufficient due to their limited capacity for feature extraction. This limitation restricts their ability to exploit training data. To address this issue, we propose an integrated approach that combines knowledge distillation and semi-supervised learning methods. This hybrid approach leverages the robust capabilities of large models to effectively utilise large unlabelled data whilst subsequently providing the small student model with rich and informative features for enhancement. The proposed semi-supervised learning-based knowledge distillation (SSLKD) approach demonstrates a notable improvement in the performance of the student model, in the application of road segmentation, surpassing the effectiveness of traditional semi-supervised learning methods.
DiverseNet: Decision Diversified Semi-supervised Semantic Segmentation Networks for Remote Sensing Imagery
Nov 22, 2023Semi-supervised learning is designed to help reduce the cost of the manual labelling process by exploiting the use of useful features from a large quantity of unlabelled data during training. Since pixel-level manual labelling in large-scale remote sensing imagery is expensive, semi-supervised learning becomes an appropriate solution to this. However, most of the existing semi-supervised learning methods still lack efficient perturbation methods to promote diversity of features and the precision of pseudo labels during training. In order to fill this gap, we propose DiverseNet architectures which explore multi-head and multi-model semi-supervised learning algorithms by simultaneously promoting precision and diversity during training. The two proposed methods of DiverseNet, namely the DiverseHead and DiverseModel, achieve the highest semantic segmentation performance in four widely utilised remote sensing imagery data sets compared to state-of-the-art semi-supervised learning methods. Meanwhile, the proposed DiverseHead architecture is relatively lightweight in terms of parameter space compared to the state-of-the-art methods whilst reaching high-performance results for all the tested data sets.
Confidence-Guided Semi-supervised Learning in Land Cover Classification
May 17, 2023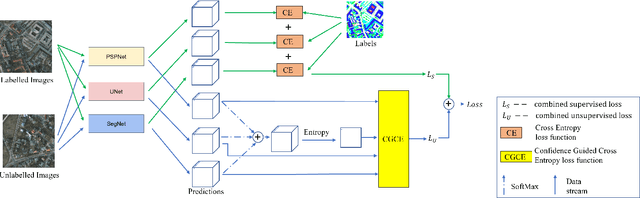



Semi-supervised learning has been well developed to help reduce the cost of manual labelling by exploiting a large quantity of unlabelled data. Especially in the application of land cover classification, pixel-level manual labelling in large-scale imagery is labour-intensive and expensive. However, the existing semi-supervised learning methods pay limited attention to the quality of pseudo-labels whilst supervising the network. That is, nevertheless, one of the critical factors determining network performance. In order to fill this gap, we develop a confidence-guided semi-supervised learning (CGSSL) approach to make use of high-confidence pseudo labels and reduce the negative effect of low-confidence ones on training the land cover classification network. Meanwhile, the proposed semi-supervised learning approach uses multiple network architectures to increase pseudo-label diversity. The proposed semi-supervised learning approach significantly improves the performance of land cover classification compared to the classical semi-supervised learning methods in computer vision and even outperforms fully supervised learning with a complete set of labelled imagery of the benchmark Potsdam land cover data set.
High-precision Density Mapping of Marine Debris and Floating Plastics via Satellite Imagery
Oct 11, 2022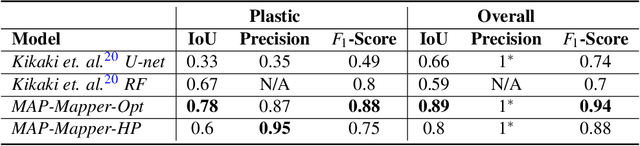
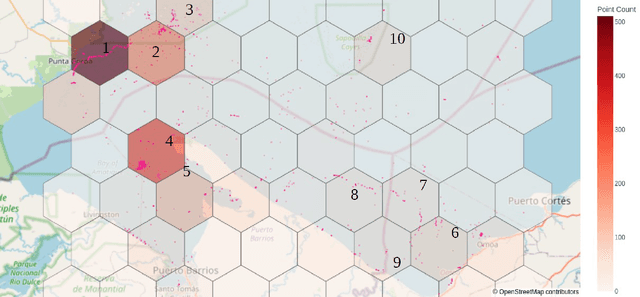
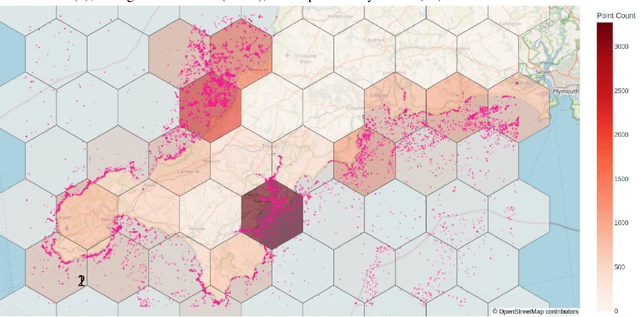
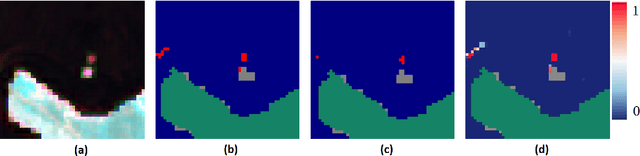
Combining multi-spectral satellite data and machine learning has been suggested as a method for monitoring plastic pollutants in the ocean environment. Recent studies have made theoretical progress regarding the identification of marine plastic via machine learning. However, no study has assessed the application of these methods for mapping and monitoring marine-plastic density. As such, this paper comprised of three main components: (1) the development of a machine learning model, (2) the construction of the MAP-Mapper, an automated tool for mapping marine-plastic density, and finally (3) an evaluation of the whole system for out-of-distribution test locations. The findings from this paper leverage the fact that machine learning models need to be high-precision to reduce the impact of false positives on results. The developed MAP-Mapper architectures provide users choices to reach high-precision ($\textit{abbv.}$ -HP) or optimum precision-recall ($\textit{abbv.}$ -Opt) values in terms of the training/test data set. Our MAP-Mapper-HP model greatly increased the precision of plastic detection to 95\%, whilst MAP-Mapper-Opt reaches precision-recall pair of 87\%-88\%. The MAP-Mapper contributes to the literature with the first tool to exploit advanced deep/machine learning and multi-spectral imagery to map marine-plastic density in automated software. The proposed data pipeline has taken a novel approach to map plastic density in ocean regions. As such, this enables an initial assessment of the challenges and opportunities of this method to help guide future work and scientific study.