 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining-Free Object-Background Compositional T2I via Dynamic Spatial Guidance and Multi-Path Pruning
Apr 10, 2026Existing text-to-image diffusion models, while excelling at subject synthesis, exhibit a persistent foreground bias that treats the background as a passive and under-optimized byproduct. This imbalance compromises global scene coherence and constrains compositional control. To address the limitation, we propose a training-free framework that restructures diffusion sampling to explicitly account for foreground-background interactions. Our approach consists of two key components. First, Dynamic Spatial Guidance introduces a soft, time step dependent gating mechanism that modulates foreground and background attention during the diffusion process, enabling spatially balanced generation. Second, Multi-Path Pruning performs multi-path latent exploration and dynamically filters candidate trajectories using both internal attention statistics and external semantic alignment signals, retaining trajectories that better satisfy object-background constraints. We further develop a benchmark specifically designed to evaluate object-background compositionality. Extensive evaluations across multiple diffusion backbones demonstrate consistent improvements in background coherence and object-background compositional alignment.
Canonical Pose Reconstruction from Single Depth Image for 3D Non-rigid Pose Recovery on Limited Datasets
May 23, 2025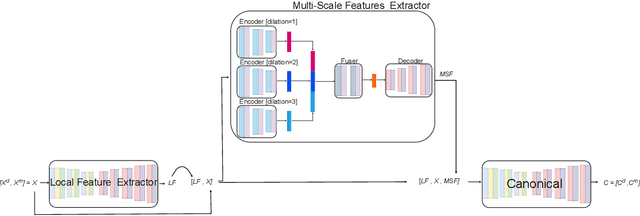
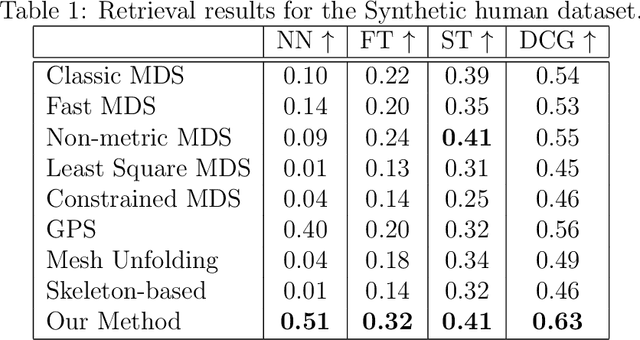
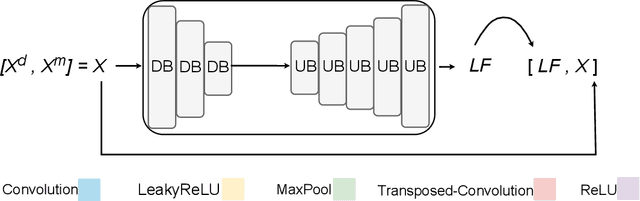

3D reconstruction from 2D inputs, especially for non-rigid objects like humans, presents unique challenges due to the significant range of possible deformations. Traditional methods often struggle with non-rigid shapes, which require extensive training data to cover the entire deformation space. This study addresses these limitations by proposing a canonical pose reconstruction model that transforms single-view depth images of deformable shapes into a canonical form. This alignment facilitates shape reconstruction by enabling the application of rigid object reconstruction techniques, and supports recovering the input pose in voxel representation as part of the reconstruction task, utilizing both the original and deformed depth images. Notably, our model achieves effective results with only a small dataset of approximately 300 samples. Experimental results on animal and human datasets demonstrate that our model outperforms other state-of-the-art methods.
Core-Set Selection for Data-efficient Land Cover Segmentation
May 02, 2025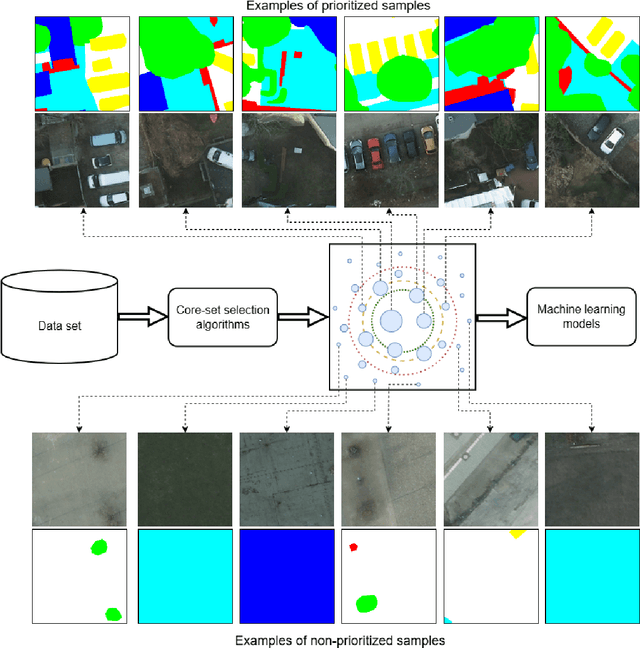


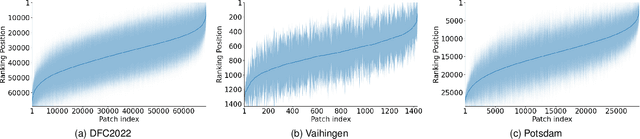
The increasing accessibility of remotely sensed data and the potential of such data to inform large-scale decision-making has driven the development of deep learning models for many Earth Observation tasks. Traditionally, such models must be trained on large datasets. However, the common assumption that broadly larger datasets lead to better outcomes tends to overlook the complexities of the data distribution, the potential for introducing biases and noise, and the computational resources required for processing and storing vast datasets. Therefore, effective solutions should consider both the quantity and quality of data. In this paper, we propose six novel core-set selection methods for selecting important subsets of samples from remote sensing image segmentation datasets that rely on imagery only, labels only, and a combination of each. We benchmark these approaches against a random-selection baseline on three commonly used land cover classification datasets: DFC2022, Vaihingen, and Potsdam. In each of the datasets, we demonstrate that training on a subset of samples outperforms the random baseline, and some approaches outperform training on all available data. This result shows the importance and potential of data-centric learning for the remote sensing domain. The code is available at https://github.com/keillernogueira/data-centric-rs-classification/.
Integrating Semi-Supervised and Active Learning for Semantic Segmentation
Jan 31, 2025



In this paper, we propose a novel active learning approach integrated with an improved semi-supervised learning framework to reduce the cost of manual annotation and enhance model performance. Our proposed approach effectively leverages both the labelled data selected through active learning and the unlabelled data excluded from the selection process. The proposed active learning approach pinpoints areas where the pseudo-labels are likely to be inaccurate. Then, an automatic and efficient pseudo-label auto-refinement (PLAR) module is proposed to correct pixels with potentially erroneous pseudo-labels by comparing their feature representations with those of labelled regions. This approach operates without increasing the labelling budget and is based on the cluster assumption, which states that pixels belonging to the same class should exhibit similar representations in feature space. Furthermore, manual labelling is only applied to the most difficult and uncertain areas in unlabelled data, where insufficient information prevents the PLAR module from making a decision. We evaluated the proposed hybrid semi-supervised active learning framework on two benchmark datasets, one from natural and the other from remote sensing imagery domains. In both cases, it outperformed state-of-the-art methods in the semantic segmentation task.
Patch-GAN Transfer Learning with Reconstructive Models for Cloud Removal
Jan 09, 2025Cloud removal plays a crucial role in enhancing remote sensing image analysis, yet accurately reconstructing cloud-obscured regions remains a significant challenge. Recent advancements in generative models have made the generation of realistic images increasingly accessible, offering new opportunities for this task. Given the conceptual alignment between image generation and cloud removal tasks, generative models present a promising approach for addressing cloud removal in remote sensing. In this work, we propose a deep transfer learning approach built on a generative adversarial network (GAN) framework to explore the potential of the novel masked autoencoder (MAE) image reconstruction model in cloud removal. Due to the complexity of remote sensing imagery, we further propose using a patch-wise discriminator to determine whether each patch of the image is real or not. The proposed reconstructive transfer learning approach demonstrates significant improvements in cloud removal performance compared to other GAN-based methods. Additionally, whilst direct comparisons with some of the state-of-the-art cloud removal techniques are limited due to unclear details regarding their train/test data splits, the proposed model achieves competitive results based on available benchmarks.
AttentionPainter: An Efficient and Adaptive Stroke Predictor for Scene Painting
Oct 21, 2024



Stroke-based Rendering (SBR) aims to decompose an input image into a sequence of parameterized strokes, which can be rendered into a painting that resembles the input image. Recently, Neural Painting methods that utilize deep learning and reinforcement learning models to predict the stroke sequences have been developed, but suffer from longer inference time or unstable training. To address these issues, we propose AttentionPainter, an efficient and adaptive model for single-step neural painting. First, we propose a novel scalable stroke predictor, which predicts a large number of stroke parameters within a single forward process, instead of the iterative prediction of previous Reinforcement Learning or auto-regressive methods, which makes AttentionPainter faster than previous neural painting methods. To further increase the training efficiency, we propose a Fast Stroke Stacking algorithm, which brings 13 times acceleration for training. Moreover, we propose Stroke-density Loss, which encourages the model to use small strokes for detailed information, to help improve the reconstruction quality. Finally, we propose a new stroke diffusion model for both conditional and unconditional stroke-based generation, which denoises in the stroke parameter space and facilitates stroke-based inpainting and editing applications helpful for human artists design. Extensive experiments show that AttentionPainter outperforms the state-of-the-art neural painting methods.
SuperSVG: Superpixel-based Scalable Vector Graphics Synthesis
Jun 14, 2024SVG (Scalable Vector Graphics) is a widely used graphics format that possesses excellent scalability and editability. Image vectorization, which aims to convert raster images to SVGs, is an important yet challenging problem in computer vision and graphics. Existing image vectorization methods either suffer from low reconstruction accuracy for complex images or require long computation time. To address this issue, we propose SuperSVG, a superpixel-based vectorization model that achieves fast and high-precision image vectorization. Specifically, we decompose the input image into superpixels to help the model focus on areas with similar colors and textures. Then, we propose a two-stage self-training framework, where a coarse-stage model is employed to reconstruct the main structure and a refinement-stage model is used for enriching the details. Moreover, we propose a novel dynamic path warping loss to help the refinement-stage model to inherit knowledge from the coarse-stage model. Extensive qualitative and quantitative experiments demonstrate the superior performance of our method in terms of reconstruction accuracy and inference time compared to state-of-the-art approaches. The code is available in \url{https://github.com/sjtuplayer/SuperSVG}.
Knowledge Distillation for Road Detection based on cross-model Semi-Supervised Learning
Feb 07, 2024The advancement of knowledge distillation has played a crucial role in enabling the transfer of knowledge from larger teacher models to smaller and more efficient student models, and is particularly beneficial for online and resource-constrained applications. The effectiveness of the student model heavily relies on the quality of the distilled knowledge received from the teacher. Given the accessibility of unlabelled remote sensing data, semi-supervised learning has become a prevalent strategy for enhancing model performance. However, relying solely on semi-supervised learning with smaller models may be insufficient due to their limited capacity for feature extraction. This limitation restricts their ability to exploit training data. To address this issue, we propose an integrated approach that combines knowledge distillation and semi-supervised learning methods. This hybrid approach leverages the robust capabilities of large models to effectively utilise large unlabelled data whilst subsequently providing the small student model with rich and informative features for enhancement. The proposed semi-supervised learning-based knowledge distillation (SSLKD) approach demonstrates a notable improvement in the performance of the student model, in the application of road segmentation, surpassing the effectiveness of traditional semi-supervised learning methods.
DiverseNet: Decision Diversified Semi-supervised Semantic Segmentation Networks for Remote Sensing Imagery
Nov 22, 2023Semi-supervised learning is designed to help reduce the cost of the manual labelling process by exploiting the use of useful features from a large quantity of unlabelled data during training. Since pixel-level manual labelling in large-scale remote sensing imagery is expensive, semi-supervised learning becomes an appropriate solution to this. However, most of the existing semi-supervised learning methods still lack efficient perturbation methods to promote diversity of features and the precision of pseudo labels during training. In order to fill this gap, we propose DiverseNet architectures which explore multi-head and multi-model semi-supervised learning algorithms by simultaneously promoting precision and diversity during training. The two proposed methods of DiverseNet, namely the DiverseHead and DiverseModel, achieve the highest semantic segmentation performance in four widely utilised remote sensing imagery data sets compared to state-of-the-art semi-supervised learning methods. Meanwhile, the proposed DiverseHead architecture is relatively lightweight in terms of parameter space compared to the state-of-the-art methods whilst reaching high-performance results for all the tested data sets.
SAMVG: A Multi-stage Image Vectorization Model with the Segment-Anything Model
Nov 09, 2023


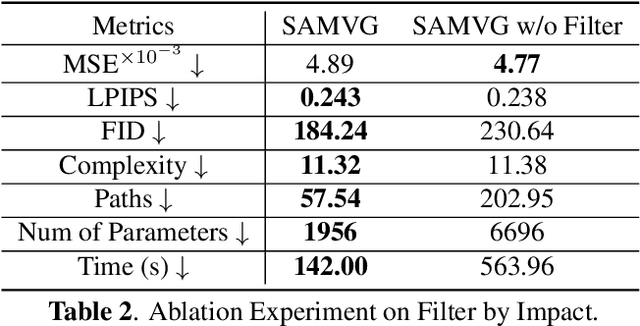
Vector graphics are widely used in graphical designs and have received more and more attention. However, unlike raster images which can be easily obtained, acquiring high-quality vector graphics, typically through automatically converting from raster images remains a significant challenge, especially for more complex images such as photos or artworks. In this paper, we propose SAMVG, a multi-stage model to vectorize raster images into SVG (Scalable Vector Graphics). Firstly, SAMVG uses general image segmentation provided by the Segment-Anything Model and uses a novel filtering method to identify the best dense segmentation map for the entire image. Secondly, SAMVG then identifies missing components and adds more detailed components to the SVG. Through a series of extensive experiments, we demonstrate that SAMVG can produce high quality SVGs in any domain while requiring less computation time and complexity compared to previous state-of-the-art methods.