 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Quest for Early Detection of Retinal Disease: 3D CycleGAN-based Translation of Optical Coherence Tomography into Confocal Microscopy
Aug 07, 2024



Optical coherence tomography (OCT) and confocal microscopy are pivotal in retinal imaging, offering distinct advantages and limitations. In vivo OCT offers rapid, non-invasive imaging but can suffer from clarity issues and motion artifacts, while ex vivo confocal microscopy, providing high-resolution, cellular-detailed color images, is invasive and raises ethical concerns. To bridge the benefits of both modalities, we propose a novel framework based on unsupervised 3D CycleGAN for translating unpaired in vivo OCT to ex vivo confocal microscopy images. This marks the first attempt to exploit the inherent 3D information of OCT and translate it into the rich, detailed color domain of confocal microscopy. We also introduce a unique dataset, OCT2Confocal, comprising mouse OCT and confocal retinal images, facilitating the development of and establishing a benchmark for cross-modal image translation research. Our model has been evaluated both quantitatively and qualitatively, achieving Fr\'echet Inception Distance (FID) scores of 0.766 and Kernel Inception Distance (KID) scores as low as 0.153, and leading subjective Mean Opinion Scores (MOS). Our model demonstrated superior image fidelity and quality with limited data over existing methods. Our approach effectively synthesizes color information from 3D confocal images, closely approximating target outcomes and suggesting enhanced potential for diagnostic and monitoring applications in ophthalmology.
TaGAT: Topology-Aware Graph Attention Network For Multi-modal Retinal Image Fusion
Jul 19, 2024


In the realm of medical image fusion, integrating information from various modalities is crucial for improving diagnostics and treatment planning, especially in retinal health, where the important features exhibit differently in different imaging modalities. Existing deep learning-based approaches insufficiently focus on retinal image fusion, and thus fail to preserve enough anatomical structure and fine vessel details in retinal image fusion. To address this, we propose the Topology-Aware Graph Attention Network (TaGAT) for multi-modal retinal image fusion, leveraging a novel Topology-Aware Encoder (TAE) with Graph Attention Networks (GAT) to effectively enhance spatial features with retinal vasculature's graph topology across modalities. The TAE encodes the base and detail features, extracted via a Long-short Range (LSR) encoder from retinal images, into the graph extracted from the retinal vessel. Within the TAE, the GAT-based Graph Information Update (GIU) block dynamically refines and aggregates the node features to generate topology-aware graph features. The updated graph features with base and detail features are combined and decoded as a fused image. Our model outperforms state-of-the-art methods in Fluorescein Fundus Angiography (FFA) with Color Fundus (CF) and Optical Coherence Tomography (OCT) with confocal microscopy retinal image fusion. The source code can be accessed via https://github.com/xintian-99/TaGAT.
OCT2Confocal: 3D CycleGAN based Translation of Retinal OCT Images to Confocal Microscopy
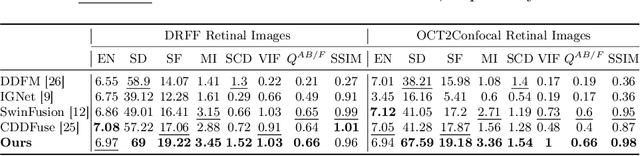
Nov 26, 2023Optical coherence tomography (OCT) and confocal microscopy are pivotal in retinal imaging, each presenting unique benefits and limitations. In vivo OCT offers rapid, non-invasive imaging but can be hampered by clarity issues and motion artifacts. Ex vivo confocal microscopy provides high-resolution, cellular detailed color images but is invasive and poses ethical concerns and potential tissue damage. To bridge these modalities, we developed a 3D CycleGAN framework for unsupervised translation of in vivo OCT to ex vivo confocal microscopy images. Applied to our OCT2Confocal dataset, this framework effectively translates between 3D medical data domains, capturing vascular, textural, and cellular details with precision. This marks the first attempt to exploit the inherent 3D information of OCT and translate it into the rich, detailed color domain of confocal microscopy. Assessed through quantitative and qualitative metrics, the 3D CycleGAN framework demonstrates commendable image fidelity and quality, outperforming existing methods despite the constraints of limited data. This non-invasive generation of retinal confocal images has the potential to further enhance diagnostic and monitoring capabilities in ophthalmology.
Optimal Transport-based Graph Matching for 3D retinal OCT image registration
Feb 28, 2022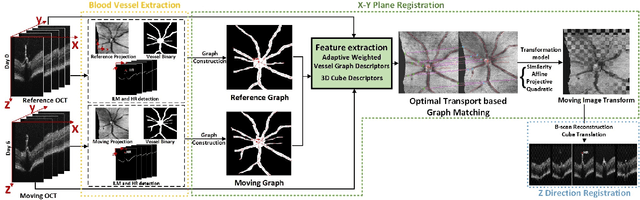



Registration of longitudinal optical coherence tomography (OCT) images assists disease monitoring and is essential in image fusion applications. Mouse retinal OCT images are often collected for longitudinal study of eye disease models such as uveitis, but their quality is often poor compared with human imaging. This paper presents a novel but efficient framework involving an optimal transport based graph matching (OT-GM) method for 3D mouse OCT image registration. We first perform registration of fundus-like images obtained by projecting all b-scans of a volume on a plane orthogonal to them, hereafter referred to as the x-y plane. We introduce Adaptive Weighted Vessel Graph Descriptors (AWVGD) and 3D Cube Descriptors (CD) to identify the correspondence between nodes of graphs extracted from segmented vessels within the OCT projection images. The AWVGD comprises scaling, translation and rotation, which are computationally efficient, whereas CD exploits 3D spatial and frequency domain information. The OT-GM method subsequently performs the correct alignment in the x-y plane. Finally, registration along the direction orthogonal to the x-y plane (the z-direction) is guided by the segmentation of two important anatomical features peculiar to mouse b-scans, the Internal Limiting Membrane (ILM) and the hyaloid remnant (HR). Both subjective and objective evaluation results demonstrate that our framework outperforms other well-established methods on mouse OCT images within a reasonable execution time.
Non-convex Super-resolution of OCT images via sparse representation
Oct 22, 2020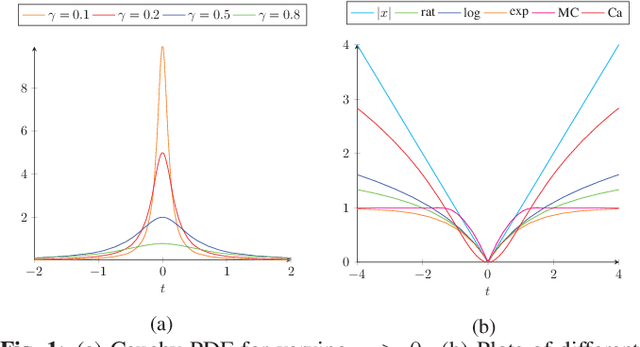
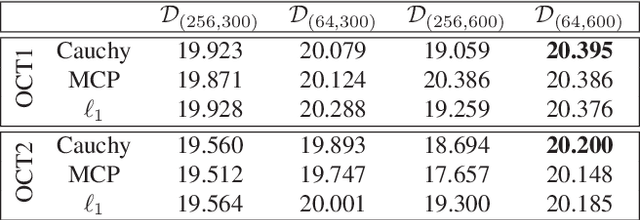
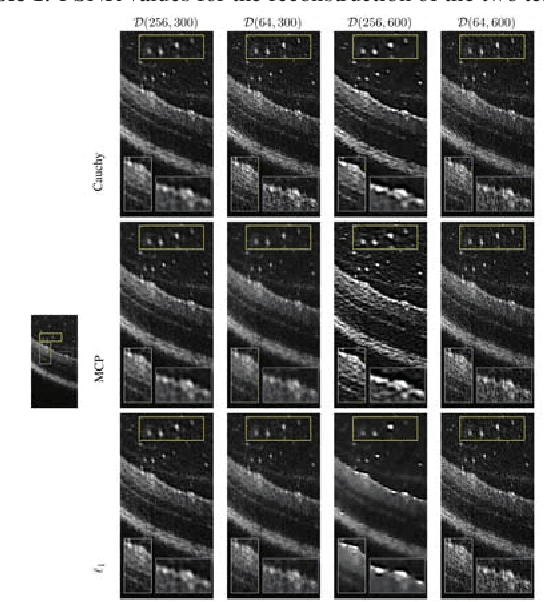
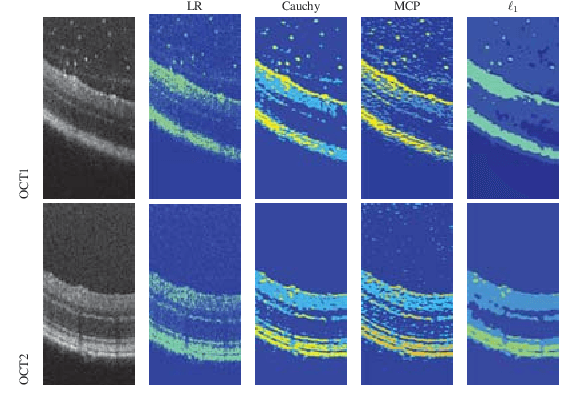
We propose a non-convex variational model for the super-resolution of Optical Coherence Tomography (OCT) images of the murine eye, by enforcing sparsity with respect to suitable dictionaries learnt from high-resolution OCT data. The statistical characteristics of OCT images motivate the use of {\alpha}-stable distributions for learning dictionaries, by considering the non-Gaussian case, {\alpha}=1. The sparsity-promoting cost function relies on a non-convex penalty - Cauchy-based or Minimax Concave Penalty (MCP) - which makes the problem particularly challenging. We propose an efficient algorithm for minimizing the function based on the forward-backward splitting strategy which guarantees at each iteration the existence and uniqueness of the proximal point. Comparisons with standard convex L1-based reconstructions show the better performance of non-convex models, especially in view of further OCT image analysis