 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Governance-Oriented Low-Altitude Intelligence: A Management-Centric Multi-Modal Benchmark With Implicitly Coordinated Vision-Language Reasoning Framework
Jan 27, 2026Low-altitude vision systems are becoming a critical infrastructure for smart city governance. However, existing object-centric perception paradigms and loosely coupled vision-language pipelines are still difficult to support management-oriented anomaly understanding required in real-world urban governance. To bridge this gap, we introduce GovLA-10K, the first management-oriented multi-modal benchmark for low-altitude intelligence, along with GovLA-Reasoner, a unified vision-language reasoning framework tailored for governance-aware aerial perception. Unlike existing studies that aim to exhaustively annotate all visible objects, GovLA-10K is deliberately designed around functionally salient targets that directly correspond to practical management needs, and further provides actionable management suggestions grounded in these observations. To effectively coordinate the fine-grained visual grounding with high-level contextual language reasoning, GovLA-Reasoner introduces an efficient feature adapter that implicitly coordinates discriminative representation sharing between the visual detector and the large language model (LLM). Extensive experiments show that our method significantly improves performance while avoiding the need of fine-tuning for any task-specific individual components. We believe our work offers a new perspective and foundation for future studies on management-aware low-altitude vision-language systems.
PixCLIP: Achieving Fine-grained Visual Language Understanding via Any-granularity Pixel-Text Alignment Learning
Nov 06, 2025While the Contrastive Language-Image Pretraining(CLIP) model has achieved remarkable success in a variety of downstream vison language understanding tasks, enhancing its capability for fine-grained image-text alignment remains an active research focus. To this end, most existing works adopt the strategy of explicitly increasing the granularity of visual information processing, e.g., incorporating visual prompts to guide the model focus on specific local regions within the image. Meanwhile, researches on Multimodal Large Language Models(MLLMs) have demonstrated that training with long and detailed textual descriptions can effectively improve the model's fine-grained vision-language alignment. However, the inherent token length limitation of CLIP's text encoder fundamentally limits CLIP to process more granular textual information embedded in long text sequences. To synergistically leverage the advantages of enhancing both visual and textual content processing granularity, we propose PixCLIP, a novel framework designed to concurrently accommodate visual prompt inputs and process lengthy textual descriptions. Specifically, we first establish an automated annotation pipeline capable of generating pixel-level localized, long-form textual descriptions for images. Utilizing this pipeline, we construct LongGRIT, a high-quality dataset comprising nearly 1.5 million samples. Secondly, we replace CLIP's original text encoder with the LLM and propose a three-branch pixel-text alignment learning framework, facilitating fine-grained alignment between image regions and corresponding textual descriptions at arbitrary granularity. Experiments demonstrate that PixCLIP showcases breakthroughs in pixel-level interaction and handling long-form texts, achieving state-of-the-art performance.
Enhancing Text-to-SQL Capabilities of Large Language Models via Domain Database Knowledge Injection
Sep 24, 2024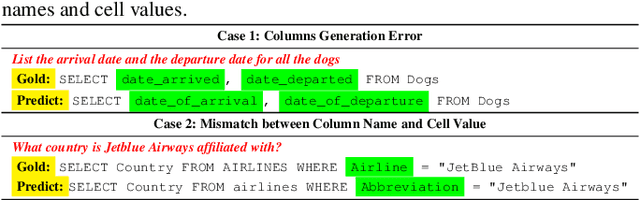

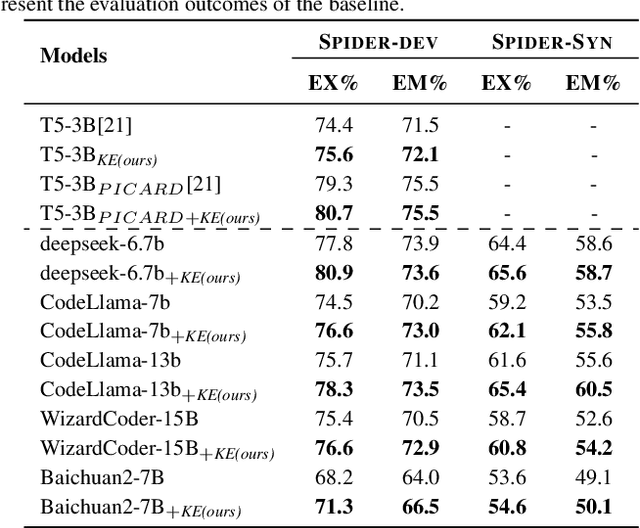
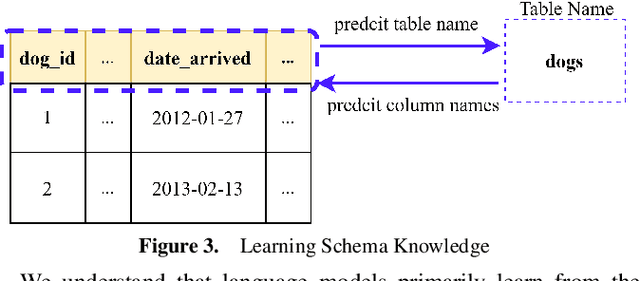
Text-to-SQL is a subtask in semantic parsing that has seen rapid progress with the evolution of Large Language Models (LLMs). However, LLMs face challenges due to hallucination issues and a lack of domain-specific database knowledge(such as table schema and cell values). As a result, they can make errors in generating table names, columns, and matching values to the correct columns in SQL statements. This paper introduces a method of knowledge injection to enhance LLMs' ability to understand schema contents by incorporating prior knowledge. This approach improves their performance in Text-to-SQL tasks. Experimental results show that pre-training LLMs on domain-specific database knowledge and fine-tuning them on downstream Text-to-SQL tasks significantly improves the Execution Match (EX) and Exact Match (EM) metrics across various models. This effectively reduces errors in generating column names and matching values to the columns. Furthermore, the knowledge-injected models can be applied to many downstream Text-to-SQL tasks, demonstrating the generalizability of the approach presented in this paper.
AnyDesign: Versatile Area Fashion Editing via Mask-Free Diffusion
Aug 21, 2024



Fashion image editing aims to modify a person's appearance based on a given instruction. Existing methods require auxiliary tools like segmenters and keypoint extractors, lacking a flexible and unified framework. Moreover, these methods are limited in the variety of clothing types they can handle, as most datasets focus on people in clean backgrounds and only include generic garments such as tops, pants, and dresses. These limitations restrict their applicability in real-world scenarios. In this paper, we first extend an existing dataset for human generation to include a wider range of apparel and more complex backgrounds. This extended dataset features people wearing diverse items such as tops, pants, dresses, skirts, headwear, scarves, shoes, socks, and bags. Additionally, we propose AnyDesign, a diffusion-based method that enables mask-free editing on versatile areas. Users can simply input a human image along with a corresponding prompt in either text or image format. Our approach incorporates Fashion DiT, equipped with a Fashion-Guidance Attention (FGA) module designed to fuse explicit apparel types and CLIP-encoded apparel features. Both Qualitative and quantitative experiments demonstrate that our method delivers high-quality fashion editing and outperforms contemporary text-guided fashion editing methods.
Pattern-Aware Chain-of-Thought Prompting in Large Language Models
Apr 23, 2024

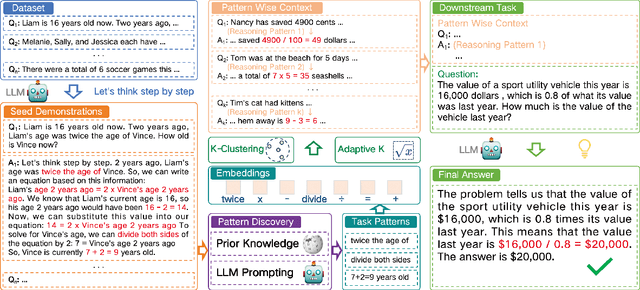

Chain-of-thought (CoT) prompting can guide language models to engage in complex multi-step reasoning. The quality of provided demonstrations significantly impacts the success of downstream inference tasks. While existing automated methods prioritize accuracy and semantics in these demonstrations, we show that the underlying reasoning patterns play a more crucial role in such tasks. In this paper, we propose Pattern-Aware CoT, a prompting method that considers the diversity of demonstration patterns. By incorporating patterns such as step length and reasoning process within intermediate steps, PA-CoT effectively mitigates the issue of bias induced by demonstrations and enables better generalization to diverse scenarios. We conduct experiments on nine reasoning benchmark tasks using two open-source LLMs. The results show that our method substantially enhances reasoning performance and exhibits robustness to errors. The code will be made publicly available.
PFDM: Parser-Free Virtual Try-on via Diffusion Model
Feb 05, 2024



Virtual try-on can significantly improve the garment shopping experiences in both online and in-store scenarios, attracting broad interest in computer vision. However, to achieve high-fidelity try-on performance, most state-of-the-art methods still rely on accurate segmentation masks, which are often produced by near-perfect parsers or manual labeling. To overcome the bottleneck, we propose a parser-free virtual try-on method based on the diffusion model (PFDM). Given two images, PFDM can "wear" garments on the target person seamlessly by implicitly warping without any other information. To learn the model effectively, we synthesize many pseudo-images and construct sample pairs by wearing various garments on persons. Supervised by the large-scale expanded dataset, we fuse the person and garment features using a proposed Garment Fusion Attention (GFA) mechanism. Experiments demonstrate that our proposed PFDM can successfully handle complex cases, synthesize high-fidelity images, and outperform both state-of-the-art parser-free and parser-based models.