 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniSurg: A Video-Native Foundation Model for Universal Understanding of Surgical Videos
Feb 05, 2026While foundation models have advanced surgical video analysis, current approaches rely predominantly on pixel-level reconstruction objectives that waste model capacity on low-level visual details - such as smoke, specular reflections, and fluid motion - rather than semantic structures essential for surgical understanding. We present UniSurg, a video-native foundation model that shifts the learning paradigm from pixel-level reconstruction to latent motion prediction. Built on the Video Joint Embedding Predictive Architecture (V-JEPA), UniSurg introduces three key technical innovations tailored to surgical videos: 1) motion-guided latent prediction to prioritize semantically meaningful regions, 2) spatiotemporal affinity self-distillation to enforce relational consistency, and 3) feature diversity regularization to prevent representation collapse in texture-sparse surgical scenes. To enable large-scale pretraining, we curate UniSurg-15M, the largest surgical video dataset to date, comprising 3,658 hours of video from 50 sources across 13 anatomical regions. Extensive experiments across 17 benchmarks demonstrate that UniSurg significantly outperforms state-of-the-art methods on surgical workflow recognition (+14.6% F1 on EgoSurgery, +10.3% on PitVis), action triplet recognition (39.54% mAP-IVT on CholecT50), skill assessment, polyp segmentation, and depth estimation. These results establish UniSurg as a new standard for universal, motion-oriented surgical video understanding.
BREATH-VL: Vision-Language-Guided 6-DoF Bronchoscopy Localization via Semantic-Geometric Fusion
Jan 07, 2026Vision-language models (VLMs) have recently shown remarkable performance in navigation and localization tasks by leveraging large-scale pretraining for semantic understanding. However, applying VLMs to 6-DoF endoscopic camera localization presents several challenges: 1) the lack of large-scale, high-quality, densely annotated, and localization-oriented vision-language datasets in real-world medical settings; 2) limited capability for fine-grained pose regression; and 3) high computational latency when extracting temporal features from past frames. To address these issues, we first construct BREATH dataset, the largest in-vivo endoscopic localization dataset to date, collected in the complex human airway. Building on this dataset, we propose BREATH-VL, a hybrid framework that integrates semantic cues from VLMs with geometric information from vision-based registration methods for accurate 6-DoF pose estimation. Our motivation lies in the complementary strengths of both approaches: VLMs offer generalizable semantic understanding, while registration methods provide precise geometric alignment. To further enhance the VLM's ability to capture temporal context, we introduce a lightweight context-learning mechanism that encodes motion history as linguistic prompts, enabling efficient temporal reasoning without expensive video-level computation. Extensive experiments demonstrate that the vision-language module delivers robust semantic localization in challenging surgical scenes. Building on this, our BREATH-VL outperforms state-of-the-art vision-only localization methods in both accuracy and generalization, reducing translational error by 25.5% compared with the best-performing baseline, while achieving competitive computational latency.
Anatomy-R1: Enhancing Anatomy Reasoning in Multimodal Large Language Models via Anatomical Similarity Curriculum and Group Diversity Augmentation
Dec 24, 2025Multimodal Large Language Models (MLLMs) have achieved impressive progress in natural image reasoning, yet their potential in medical imaging remains underexplored, especially in clinical anatomical surgical images. Anatomy understanding tasks demand precise understanding and clinically coherent answers, which are difficult to achieve due to the complexity of medical data and the scarcity of high-quality expert annotations. These challenges limit the effectiveness of conventional Supervised Fine-Tuning (SFT) strategies. While recent work has demonstrated that Group Relative Policy Optimization (GRPO) can enhance reasoning in MLLMs without relying on large amounts of data, we find two weaknesses that hinder GRPO's reasoning performance in anatomy recognition: 1) knowledge cannot be effectively shared between different anatomical structures, resulting in uneven information gain and preventing the model from converging, and 2) the model quickly converges to a single reasoning path, suppressing the exploration of diverse strategies. To overcome these challenges, we propose two novel methods. First, we implement a progressive learning strategy called Anatomical Similarity Curriculum Learning by controlling question difficulty via the similarity of answer choices, enabling the model to master complex problems incrementally. Second, we utilize question augmentation referred to as Group Diversity Question Augmentation to expand the model's search space for difficult queries, mitigating the tendency to produce uniform responses. Comprehensive experiments on the SGG-VQA and OmniMedVQA benchmarks show our method achieves a significant improvement across the two benchmarks, demonstrating its effectiveness in enhancing the medical reasoning capabilities of MLLMs. The code can be found in https://github.com/tomato996/Anatomy-R1
Multimodal Causal-Driven Representation Learning for Generalizable Medical Image Segmentation
Aug 07, 2025Vision-Language Models (VLMs), such as CLIP, have demonstrated remarkable zero-shot capabilities in various computer vision tasks. However, their application to medical imaging remains challenging due to the high variability and complexity of medical data. Specifically, medical images often exhibit significant domain shifts caused by various confounders, including equipment differences, procedure artifacts, and imaging modes, which can lead to poor generalization when models are applied to unseen domains. To address this limitation, we propose Multimodal Causal-Driven Representation Learning (MCDRL), a novel framework that integrates causal inference with the VLM to tackle domain generalization in medical image segmentation. MCDRL is implemented in two steps: first, it leverages CLIP's cross-modal capabilities to identify candidate lesion regions and construct a confounder dictionary through text prompts, specifically designed to represent domain-specific variations; second, it trains a causal intervention network that utilizes this dictionary to identify and eliminate the influence of these domain-specific variations while preserving the anatomical structural information critical for segmentation tasks. Extensive experiments demonstrate that MCDRL consistently outperforms competing methods, yielding superior segmentation accuracy and exhibiting robust generalizability.
A Benchmark for Crime Surveillance Video Analysis with Large Models
Feb 13, 2025Anomaly analysis in surveillance videos is a crucial topic in computer vision. In recent years, multimodal large language models (MLLMs) have outperformed task-specific models in various domains. Although MLLMs are particularly versatile, their abilities to understand anomalous concepts and details are insufficiently studied because of the outdated benchmarks of this field not providing MLLM-style QAs and efficient algorithms to assess the model's open-ended text responses. To fill this gap, we propose a benchmark for crime surveillance video analysis with large models denoted as UCVL, including 1,829 videos and reorganized annotations from the UCF-Crime and UCF-Crime Annotation datasets. We design six types of questions and generate diverse QA pairs. Then we develop detailed instructions and use OpenAI's GPT-4o for accurate assessment. We benchmark eight prevailing MLLMs ranging from 0.5B to 40B parameters, and the results demonstrate the reliability of this bench. Moreover, we finetune LLaVA-OneVision on UCVL's training set. The improvement validates our data's high quality for video anomaly analysis.
MME-Industry: A Cross-Industry Multimodal Evaluation Benchmark
Jan 28, 2025

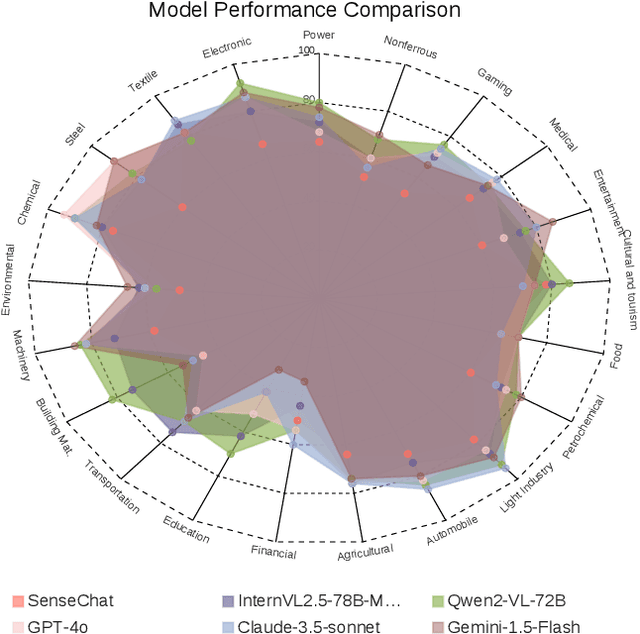
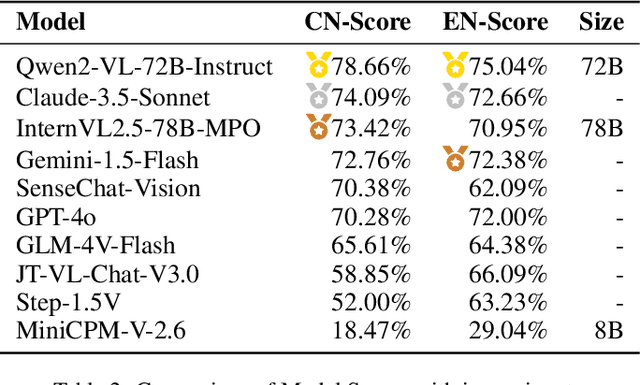
With the rapid advancement of Multimodal Large Language Models (MLLMs), numerous evaluation benchmarks have emerged. However, comprehensive assessments of their performance across diverse industrial applications remain limited. In this paper, we introduce MME-Industry, a novel benchmark designed specifically for evaluating MLLMs in industrial settings.The benchmark encompasses 21 distinct domain, comprising 1050 question-answer pairs with 50 questions per domain. To ensure data integrity and prevent potential leakage from public datasets, all question-answer pairs were manually crafted and validated by domain experts. Besides, the benchmark's complexity is effectively enhanced by incorporating non-OCR questions that can be answered directly, along with tasks requiring specialized domain knowledge. Moreover, we provide both Chinese and English versions of the benchmark, enabling comparative analysis of MLLMs' capabilities across these languages. Our findings contribute valuable insights into MLLMs' practical industrial applications and illuminate promising directions for future model optimization research.
AnyDesign: Versatile Area Fashion Editing via Mask-Free Diffusion
Aug 21, 2024



Fashion image editing aims to modify a person's appearance based on a given instruction. Existing methods require auxiliary tools like segmenters and keypoint extractors, lacking a flexible and unified framework. Moreover, these methods are limited in the variety of clothing types they can handle, as most datasets focus on people in clean backgrounds and only include generic garments such as tops, pants, and dresses. These limitations restrict their applicability in real-world scenarios. In this paper, we first extend an existing dataset for human generation to include a wider range of apparel and more complex backgrounds. This extended dataset features people wearing diverse items such as tops, pants, dresses, skirts, headwear, scarves, shoes, socks, and bags. Additionally, we propose AnyDesign, a diffusion-based method that enables mask-free editing on versatile areas. Users can simply input a human image along with a corresponding prompt in either text or image format. Our approach incorporates Fashion DiT, equipped with a Fashion-Guidance Attention (FGA) module designed to fuse explicit apparel types and CLIP-encoded apparel features. Both Qualitative and quantitative experiments demonstrate that our method delivers high-quality fashion editing and outperforms contemporary text-guided fashion editing methods.
Recurrent Context Compression: Efficiently Expanding the Context Window of LLM
Jun 10, 2024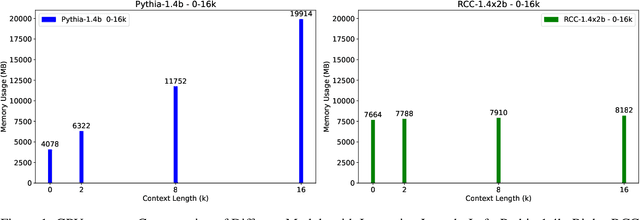

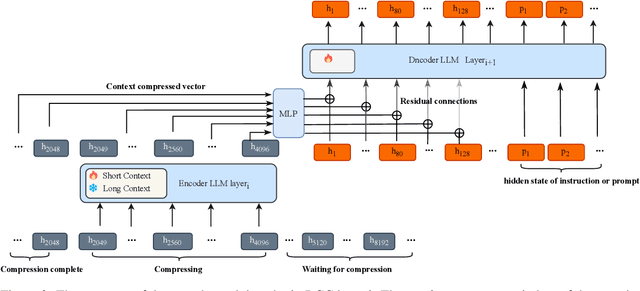

To extend the context length of Transformer-based large language models (LLMs) and improve comprehension capabilities, we often face limitations due to computational resources and bounded memory storage capacity. This work introduces a method called Recurrent Context Compression (RCC), designed to efficiently expand the context window length of LLMs within constrained storage space. We also investigate the issue of poor model responses when both instructions and context are compressed in downstream tasks, and propose an instruction reconstruction method to mitigate this problem. We validated the effectiveness of our approach on multiple tasks, achieving a compression rate of up to 32x on text reconstruction tasks with a BLEU4 score close to 0.95, and nearly 100\% accuracy on a passkey retrieval task with a sequence length of 1M. Finally, our method demonstrated competitive performance in long-text question-answering tasks compared to non-compressed methods, while significantly saving storage resources in long-text inference tasks. Our code, models, and demo are available at https://github.com/WUHU-G/RCC_Transformer
PFDM: Parser-Free Virtual Try-on via Diffusion Model
Feb 05, 2024



Virtual try-on can significantly improve the garment shopping experiences in both online and in-store scenarios, attracting broad interest in computer vision. However, to achieve high-fidelity try-on performance, most state-of-the-art methods still rely on accurate segmentation masks, which are often produced by near-perfect parsers or manual labeling. To overcome the bottleneck, we propose a parser-free virtual try-on method based on the diffusion model (PFDM). Given two images, PFDM can "wear" garments on the target person seamlessly by implicitly warping without any other information. To learn the model effectively, we synthesize many pseudo-images and construct sample pairs by wearing various garments on persons. Supervised by the large-scale expanded dataset, we fuse the person and garment features using a proposed Garment Fusion Attention (GFA) mechanism. Experiments demonstrate that our proposed PFDM can successfully handle complex cases, synthesize high-fidelity images, and outperform both state-of-the-art parser-free and parser-based models.
Large-scale Bisample Learning on ID vs. Spot Face Recognition
Jun 11, 2018


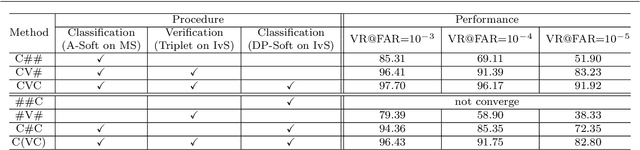
In many face recognition applications, there is large amount of face data with two images for each person. One is an ID photo for face enrollment, and the other is a probe photo captured on spot. Most existing methods are designed for training data with limited breadth (relatively small class number) and sufficient depth (many samples for each class). They would meet great challenges when applied on this ID vs. Spot (IvS) data, including the under-represented intra-class variations and the excessive demand on computing devices. In this paper, we propose a deep learning based large-scale bisample learning (LBL) method for IvS face recognition. To tackle the bisample problem that there are only two samples for each class, a classification-verification-classification (CVC) training strategy is proposed to progressively enhance the IvS performance. Besides, a dominant prototype softmax (DP-softmax) is incorporated to make the deep learning applicable on large-scale classes. We conduct LBL on a IvS face dataset with more than two million identities. Experimental results show the proposed method achieves superior performance than previous ones, validating the effectiveness of LBL on IvS face recognition.