 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Face Representation from Scratch
Paper and Code
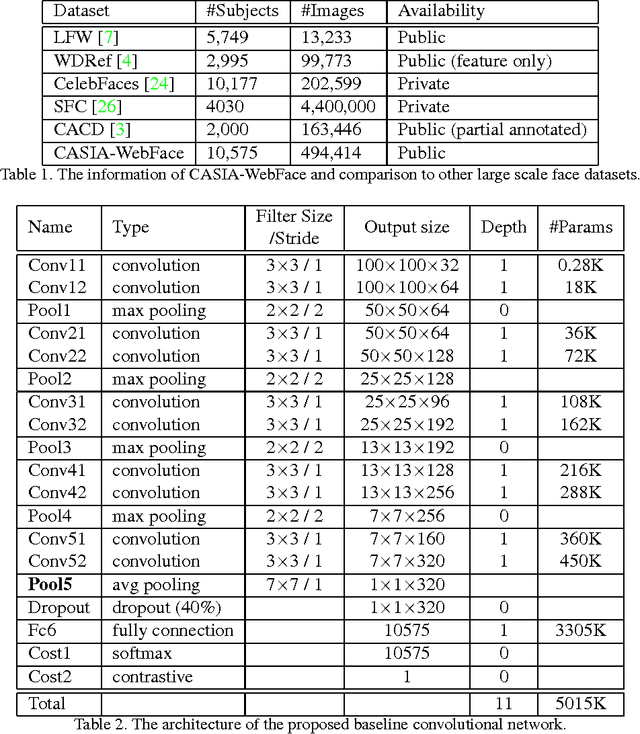

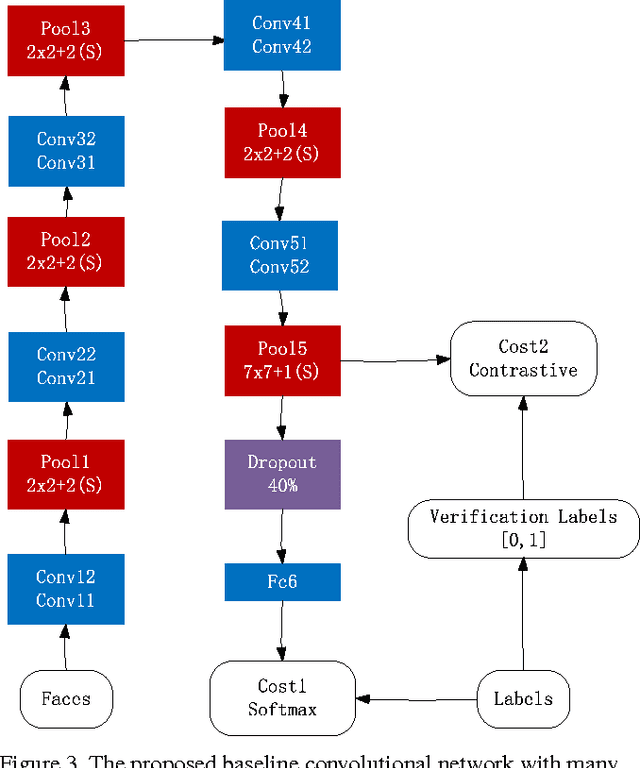
Pushing by big data and deep convolutional neural network (CNN), the performance of face recognition is becoming comparable to human. Using private large scale training datasets, several groups achieve very high performance on LFW, i.e., 97% to 99%. While there are many open source implementations of CNN, none of large scale face dataset is publicly available. The current situation in the field of face recognition is that data is more important than algorithm. To solve this problem, this paper proposes a semi-automatical way to collect face images from Internet and builds a large scale dataset containing about 10,000 subjects and 500,000 images, called CASIAWebFace. Based on the database, we use a 11-layer CNN to learn discriminative representation and obtain state-of-theart accuracy on LFW and YTF. The publication of CASIAWebFace will attract more research groups entering this field and accelerate the development of face recognition in the wild.