 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Text-to-SQL Capabilities of Large Language Models via Domain Database Knowledge Injection
Sep 24, 2024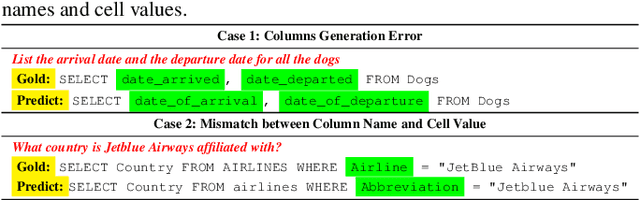

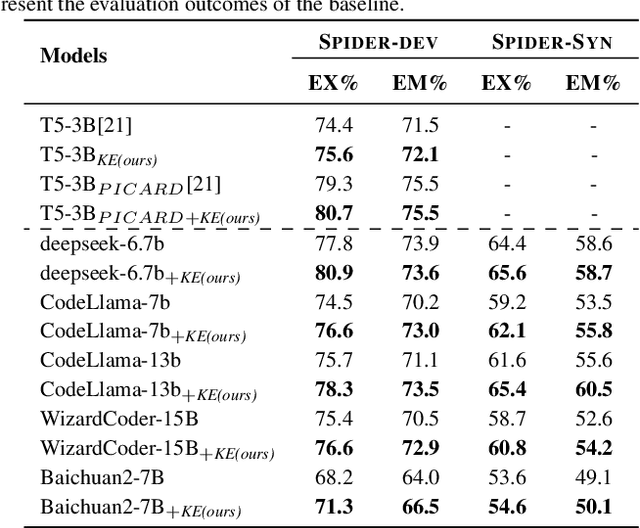
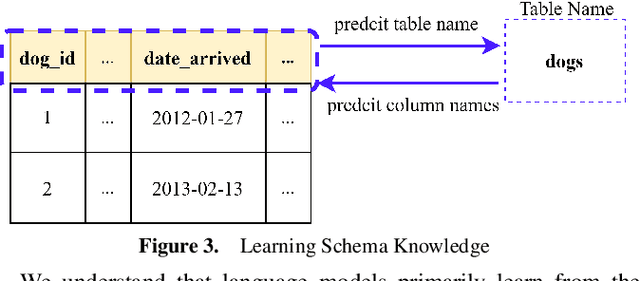
Text-to-SQL is a subtask in semantic parsing that has seen rapid progress with the evolution of Large Language Models (LLMs). However, LLMs face challenges due to hallucination issues and a lack of domain-specific database knowledge(such as table schema and cell values). As a result, they can make errors in generating table names, columns, and matching values to the correct columns in SQL statements. This paper introduces a method of knowledge injection to enhance LLMs' ability to understand schema contents by incorporating prior knowledge. This approach improves their performance in Text-to-SQL tasks. Experimental results show that pre-training LLMs on domain-specific database knowledge and fine-tuning them on downstream Text-to-SQL tasks significantly improves the Execution Match (EX) and Exact Match (EM) metrics across various models. This effectively reduces errors in generating column names and matching values to the columns. Furthermore, the knowledge-injected models can be applied to many downstream Text-to-SQL tasks, demonstrating the generalizability of the approach presented in this paper.
Recurrent Context Compression: Efficiently Expanding the Context Window of LLM
Jun 10, 2024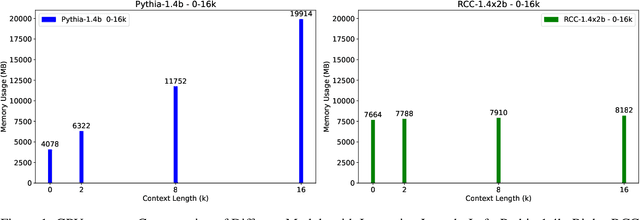

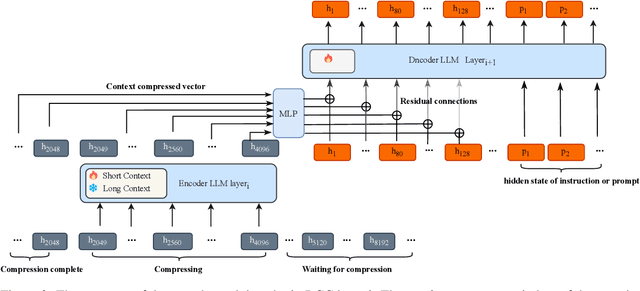

To extend the context length of Transformer-based large language models (LLMs) and improve comprehension capabilities, we often face limitations due to computational resources and bounded memory storage capacity. This work introduces a method called Recurrent Context Compression (RCC), designed to efficiently expand the context window length of LLMs within constrained storage space. We also investigate the issue of poor model responses when both instructions and context are compressed in downstream tasks, and propose an instruction reconstruction method to mitigate this problem. We validated the effectiveness of our approach on multiple tasks, achieving a compression rate of up to 32x on text reconstruction tasks with a BLEU4 score close to 0.95, and nearly 100\% accuracy on a passkey retrieval task with a sequence length of 1M. Finally, our method demonstrated competitive performance in long-text question-answering tasks compared to non-compressed methods, while significantly saving storage resources in long-text inference tasks. Our code, models, and demo are available at https://github.com/WUHU-G/RCC_Transformer
Pattern-Aware Chain-of-Thought Prompting in Large Language Models
Apr 23, 2024

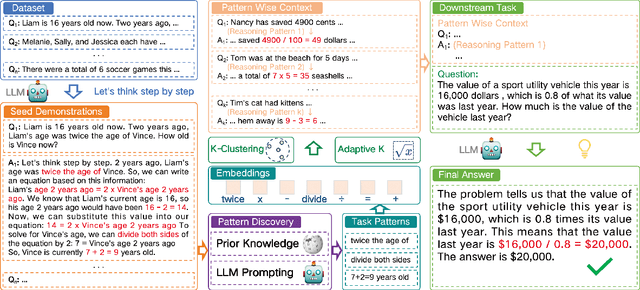

Chain-of-thought (CoT) prompting can guide language models to engage in complex multi-step reasoning. The quality of provided demonstrations significantly impacts the success of downstream inference tasks. While existing automated methods prioritize accuracy and semantics in these demonstrations, we show that the underlying reasoning patterns play a more crucial role in such tasks. In this paper, we propose Pattern-Aware CoT, a prompting method that considers the diversity of demonstration patterns. By incorporating patterns such as step length and reasoning process within intermediate steps, PA-CoT effectively mitigates the issue of bias induced by demonstrations and enables better generalization to diverse scenarios. We conduct experiments on nine reasoning benchmark tasks using two open-source LLMs. The results show that our method substantially enhances reasoning performance and exhibits robustness to errors. The code will be made publicly available.