 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAPAS: Efficient Two-Server Asymmetric Private Aggregation Beyond Prio(+)
Mar 20, 2026Privacy-preserving aggregation is a cornerstone for AI systems that learn from distributed data without exposing individual records, especially in federated learning and telemetry. Existing two-server protocols (e.g., Prio and successors) set a practical baseline by validating inputs while preventing any single party from learning users' values, but they impose symmetric costs on both servers and communication that scales with the per-client input dimension $L$. Modern learning tasks routinely involve dimensionalities $L$ in the tens to hundreds of millions of model parameters. We present TAPAS, a two-server asymmetric private aggregation scheme that addresses these limitations along four dimensions: (i) no trusted setup or preprocessing, (ii) server-side communication that is independent of $L$ (iii) post-quantum security based solely on standard lattice assumptions (LWE, SIS), and (iv) stronger robustness with identifiable abort and full malicious security for the servers. A key design choice is intentional asymmetry: one server bears the $O(L)$ aggregation and verification work, while the other operates as a lightweight facilitator with computation independent of $L$. This reduces total cost, enables the secondary server to run on commodity hardware, and strengthens the non-collusion assumption of the servers. One of our main contributions is a suite of new and efficient lattice-based zero-knowledge proofs; to our knowledge, we are the first to establish privacy and correctness with identifiable abort in the two-server setting.
ZKBoost: Zero-Knowledge Verifiable Training for XGBoost
Feb 04, 2026Gradient boosted decision trees, particularly XGBoost, are among the most effective methods for tabular data. As deployment in sensitive settings increases, cryptographic guarantees of model integrity become essential. We present ZKBoost, the first zero-knowledge proof of training (zkPoT) protocol for XGBoost, enabling model owners to prove correct training on a committed dataset without revealing data or parameters. We make three key contributions: (1) a fixed-point XGBoost implementation compatible with arithmetic circuits, enabling instantiation of efficient zkPoT, (2) a generic template of zkPoT for XGBoost, which can be instantiated with any general-purpose ZKP backend, and (3) vector oblivious linear evaluation (VOLE)-based instantiation resolving challenges in proving nonlinear fixed-point operations. Our fixed-point implementation matches standard XGBoost accuracy within 1\% while enabling practical zkPoT on real-world datasets.
Ethereum Price Prediction Employing Large Language Models for Short-term and Few-shot Forecasting
Mar 29, 2025Cryptocurrencies have transformed financial markets with their innovative blockchain technology and volatile price movements, presenting both challenges and opportunities for predictive analytics. Ethereum, being one of the leading cryptocurrencies, has experienced significant market fluctuations, making its price prediction an attractive yet complex problem. This paper presents a comprehensive study on the effectiveness of Large Language Models (LLMs) in predicting Ethereum prices for short-term and few-shot forecasting scenarios. The main challenge in training models for time series analysis is the lack of data. We address this by leveraging a novel approach that adapts existing pre-trained LLMs on natural language or images from billions of tokens to the unique characteristics of Ethereum price time series data. Through thorough experimentation and comparison with traditional and contemporary models, our results demonstrate that selectively freezing certain layers of pre-trained LLMs achieves state-of-the-art performance in this domain. This approach consistently surpasses benchmarks across multiple metrics, including Mean Squared Error (MSE), Mean Absolute Error (MAE), and Root Mean Squared Error (RMSE), demonstrating its effectiveness and robustness. Our research not only contributes to the existing body of knowledge on LLMs but also provides practical insights in the cryptocurrency prediction domain. The adaptability of pre-trained LLMs to handle the nature of Ethereum prices suggests a promising direction for future research, potentially including the integration of sentiment analysis to further refine forecasting accuracy.
MAFE: Multi-Agent Fair Environments for Decision-Making Systems
Feb 25, 2025Fairness constraints applied to machine learning (ML) models in static contexts have been shown to potentially produce adverse outcomes among demographic groups over time. To address this issue, emerging research focuses on creating fair solutions that persist over time. While many approaches treat this as a single-agent decision-making problem, real-world systems often consist of multiple interacting entities that influence outcomes. Explicitly modeling these entities as agents enables more flexible analysis of their interventions and the effects they have on a system's underlying dynamics. A significant challenge in conducting research on multi-agent systems is the lack of realistic environments that leverage the limited real-world data available for analysis. To address this gap, we introduce the concept of a Multi-Agent Fair Environment (MAFE) and present and analyze three MAFEs that model distinct social systems. Experimental results demonstrate the utility of our MAFEs as testbeds for developing multi-agent fair algorithms.
$\mathsf{OPA}$: One-shot Private Aggregation with Single Client Interaction and its Applications to Federated Learning
Oct 29, 2024



Our work aims to minimize interaction in secure computation due to the high cost and challenges associated with communication rounds, particularly in scenarios with many clients. In this work, we revisit the problem of secure aggregation in the single-server setting where a single evaluation server can securely aggregate client-held individual inputs. Our key contribution is the introduction of One-shot Private Aggregation ($\mathsf{OPA}$) where clients speak only once (or even choose not to speak) per aggregation evaluation. Since each client communicates only once per aggregation, this simplifies managing dropouts and dynamic participation, contrasting with multi-round protocols and aligning with plaintext secure aggregation, where clients interact only once. We construct $\mathsf{OPA}$ based on LWR, LWE, class groups, DCR and demonstrate applications to privacy-preserving Federated Learning (FL) where clients \emph{speak once}. This is a sharp departure from prior multi-round FL protocols whose study was initiated by Bonawitz et al. (CCS, 2017). Moreover, unlike the YOSO (You Only Speak Once) model for general secure computation, $\mathsf{OPA}$ eliminates complex committee selection protocols to achieve adaptive security. Beyond asymptotic improvements, $\mathsf{OPA}$ is practical, outperforming state-of-the-art solutions. We benchmark logistic regression classifiers for two datasets, while also building an MLP classifier to train on MNIST, CIFAR-10, and CIFAR-100 datasets. We build two flavors of $\caps$ (1) from (threshold) key homomorphic PRF and (2) from seed homomorphic PRG and secret sharing.
DMM: Distributed Matrix Mechanism for Differentially-Private Federated Learning using Packed Secret Sharing
Oct 21, 2024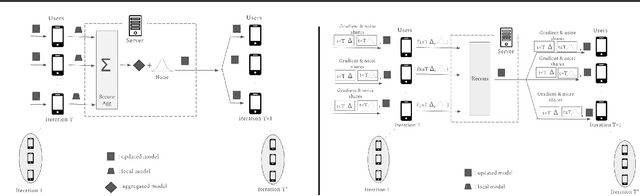
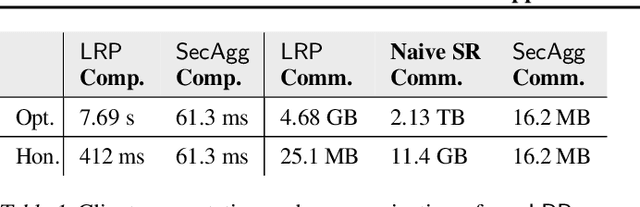
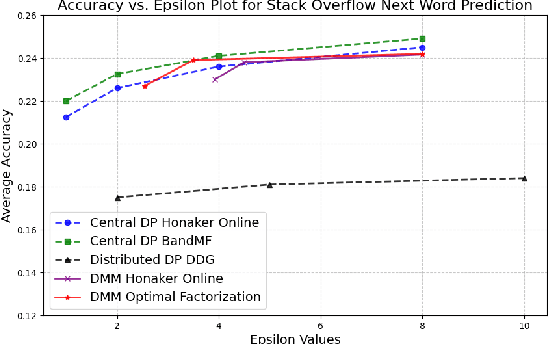
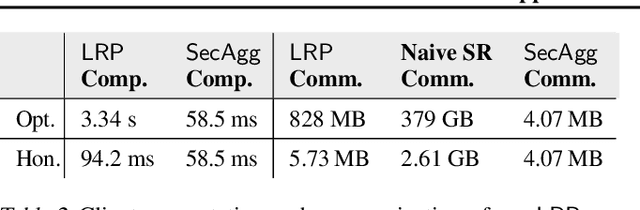
Federated Learning (FL) has gained lots of traction recently, both in industry and academia. In FL, a machine learning model is trained using data from various end-users arranged in committees across several rounds. Since such data can often be sensitive, a primary challenge in FL is providing privacy while still retaining utility of the model. Differential Privacy (DP) has become the main measure of privacy in the FL setting. DP comes in two flavors: central and local. In the former, a centralized server is trusted to receive the users' raw gradients from a training step, and then perturb their aggregation with some noise before releasing the next version of the model. In the latter (more private) setting, noise is applied on users' local devices, and only the aggregation of users' noisy gradients is revealed even to the server. Great strides have been made in increasing the privacy-utility trade-off in the central DP setting, by utilizing the so-called matrix mechanism. However, progress has been mostly stalled in the local DP setting. In this work, we introduce the distributed matrix mechanism to achieve the best-of-both-worlds; local DP and also better privacy-utility trade-off from the matrix mechanism. We accomplish this by proposing a cryptographic protocol that securely transfers sensitive values across rounds, which makes use of packed secret sharing. This protocol accommodates the dynamic participation of users per training round required by FL, including those that may drop out from the computation. We provide experiments which show that our mechanism indeed significantly improves the privacy-utility trade-off of FL models compared to previous local DP mechanisms, with little added overhead.
Balancing Fairness and Accuracy in Data-Restricted Binary Classification
Mar 12, 2024Applications that deal with sensitive information may have restrictions placed on the data available to a machine learning (ML) classifier. For example, in some applications, a classifier may not have direct access to sensitive attributes, affecting its ability to produce accurate and fair decisions. This paper proposes a framework that models the trade-off between accuracy and fairness under four practical scenarios that dictate the type of data available for analysis. Prior works examine this trade-off by analyzing the outputs of a scoring function that has been trained to implicitly learn the underlying distribution of the feature vector, class label, and sensitive attribute of a dataset. In contrast, our framework directly analyzes the behavior of the optimal Bayesian classifier on this underlying distribution by constructing a discrete approximation it from the dataset itself. This approach enables us to formulate multiple convex optimization problems, which allow us to answer the question: How is the accuracy of a Bayesian classifier affected in different data restricting scenarios when constrained to be fair? Analysis is performed on a set of fairness definitions that include group and individual fairness. Experiments on three datasets demonstrate the utility of the proposed framework as a tool for quantifying the trade-offs among different fairness notions and their distributional dependencies.
Bounding the Excess Risk for Linear Models Trained on Marginal-Preserving, Differentially-Private, Synthetic Data
Feb 06, 2024The growing use of machine learning (ML) has raised concerns that an ML model may reveal private information about an individual who has contributed to the training dataset. To prevent leakage of sensitive data, we consider using differentially-private (DP), synthetic training data instead of real training data to train an ML model. A key desirable property of synthetic data is its ability to preserve the low-order marginals of the original distribution. Our main contribution comprises novel upper and lower bounds on the excess empirical risk of linear models trained on such synthetic data, for continuous and Lipschitz loss functions. We perform extensive experimentation alongside our theoretical results.
A Canonical Data Transformation for Achieving Inter- and Within-group Fairness
Oct 23, 2023



Increases in the deployment of machine learning algorithms for applications that deal with sensitive data have brought attention to the issue of fairness in machine learning. Many works have been devoted to applications that require different demographic groups to be treated fairly. However, algorithms that aim to satisfy inter-group fairness (also called group fairness) may inadvertently treat individuals within the same demographic group unfairly. To address this issue, we introduce a formal definition of within-group fairness that maintains fairness among individuals from within the same group. We propose a pre-processing framework to meet both inter- and within-group fairness criteria with little compromise in accuracy. The framework maps the feature vectors of members from different groups to an inter-group-fair canonical domain before feeding them into a scoring function. The mapping is constructed to preserve the relative relationship between the scores obtained from the unprocessed feature vectors of individuals from the same demographic group, guaranteeing within-group fairness. We apply this framework to the COMPAS risk assessment and Law School datasets and compare its performance in achieving inter-group and within-group fairness to two regularization-based methods.
Flamingo: Multi-Round Single-Server Secure Aggregation with Applications to Private Federated Learning
Aug 19, 2023This paper introduces Flamingo, a system for secure aggregation of data across a large set of clients. In secure aggregation, a server sums up the private inputs of clients and obtains the result without learning anything about the individual inputs beyond what is implied by the final sum. Flamingo focuses on the multi-round setting found in federated learning in which many consecutive summations (averages) of model weights are performed to derive a good model. Previous protocols, such as Bell et al. (CCS '20), have been designed for a single round and are adapted to the federated learning setting by repeating the protocol multiple times. Flamingo eliminates the need for the per-round setup of previous protocols, and has a new lightweight dropout resilience protocol to ensure that if clients leave in the middle of a sum the server can still obtain a meaningful result. Furthermore, Flamingo introduces a new way to locally choose the so-called client neighborhood introduced by Bell et al. These techniques help Flamingo reduce the number of interactions between clients and the server, resulting in a significant reduction in the end-to-end runtime for a full training session over prior work. We implement and evaluate Flamingo and show that it can securely train a neural network on the (Extended) MNIST and CIFAR-100 datasets, and the model converges without a loss in accuracy, compared to a non-private federated learning system.