 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Agentic Regulator: Risks for AI in Finance and a Proposed Agent-based Framework for Governance
Dec 12, 2025Generative and agentic artificial intelligence is entering financial markets faster than existing governance can adapt. Current model-risk frameworks assume static, well-specified algorithms and one-time validations; large language models and multi-agent trading systems violate those assumptions by learning continuously, exchanging latent signals, and exhibiting emergent behavior. Drawing on complex adaptive systems theory, we model these technologies as decentralized ensembles whose risks propagate along multiple time-scales. We then propose a modular governance architecture. The framework decomposes oversight into four layers of "regulatory blocks": (i) self-regulation modules embedded beside each model, (ii) firm-level governance blocks that aggregate local telemetry and enforce policy, (iii) regulator-hosted agents that monitor sector-wide indicators for collusive or destabilizing patterns, and (iv) independent audit blocks that supply third-party assurance. Eight design strategies enable the blocks to evolve as fast as the models they police. A case study on emergent spoofing in multi-agent trading shows how the layered controls quarantine harmful behavior in real time while preserving innovation. The architecture remains compatible with today's model-risk rules yet closes critical observability and control gaps, providing a practical path toward resilient, adaptive AI governance in financial systems.
Exploring Sentiment Manipulation by LLM-Enabled Intelligent Trading Agents
Feb 22, 2025Companies across all economic sectors continue to deploy large language models at a rapid pace. Reinforcement learning is experiencing a resurgence of interest due to its association with the fine-tuning of language models from human feedback. Tool-chain language models control task-specific agents; if the converse has not already appeared, it soon will. In this paper, we present what we believe is the first investigation of an intelligent trading agent based on continuous deep reinforcement learning that also controls a large language model with which it can post to a social media feed observed by other traders. We empirically investigate the performance and impact of such an agent in a simulated financial market, finding that it learns to optimize its total reward, and thereby augment its profit, by manipulating the sentiment of the posts it produces. The paper concludes with discussion, limitations, and suggestions for future work.
Learning Not to Spoof
Jun 09, 2023As intelligent trading agents based on reinforcement learning (RL) gain prevalence, it becomes more important to ensure that RL agents obey laws, regulations, and human behavioral expectations. There is substantial literature concerning the aversion of obvious catastrophes like crashing a helicopter or bankrupting a trading account, but little around the avoidance of subtle non-normative behavior for which there are examples, but no programmable definition. Such behavior may violate legal or regulatory, rather than physical or monetary, constraints. In this article, I consider a series of experiments in which an intelligent stock trading agent maximizes profit but may also inadvertently learn to spoof the market in which it participates. I first inject a hand-coded spoofing agent to a multi-agent market simulation and learn to recognize spoofing activity sequences. Then I replace the hand-coded spoofing trader with a simple profit-maximizing RL agent and observe that it independently discovers spoofing as the optimal strategy. Finally, I introduce a method to incorporate the recognizer as normative guide, shaping the agent's perceived rewards and altering its selected actions. The agent remains profitable while avoiding spoofing behaviors that would result in even higher profit. After presenting the empirical results, I conclude with some recommendations. The method should generalize to the reduction of any unwanted behavior for which a recognizer can be learned.
Collusion Resistant Federated Learning with Oblivious Distributed Differential Privacy
Feb 20, 2022
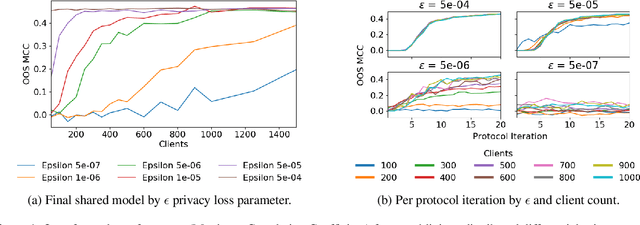
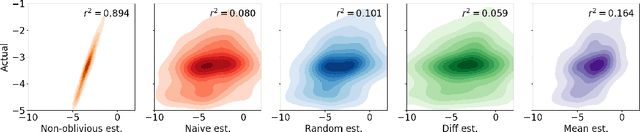
Privacy-preserving federated learning enables a population of distributed clients to jointly learn a shared model while keeping client training data private, even from an untrusted server. Prior works do not provide efficient solutions that protect against collusion attacks in which parties collaborate to expose an honest client's model parameters. We present an efficient mechanism based on oblivious distributed differential privacy that is the first to protect against such client collusion, including the "Sybil" attack in which a server preferentially selects compromised devices or simulates fake devices. We leverage the novel privacy mechanism to construct a secure federated learning protocol and prove the security of that protocol. We conclude with empirical analysis of the protocol's execution speed, learning accuracy, and privacy performance on two data sets within a realistic simulation of 5,000 distributed network clients.
Differentially Private Secure Multi-Party Computation for Federated Learning in Financial Applications
Oct 12, 2020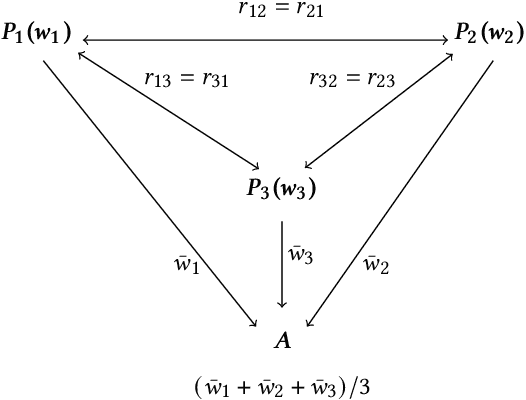
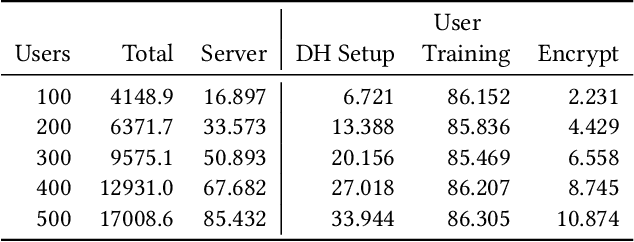
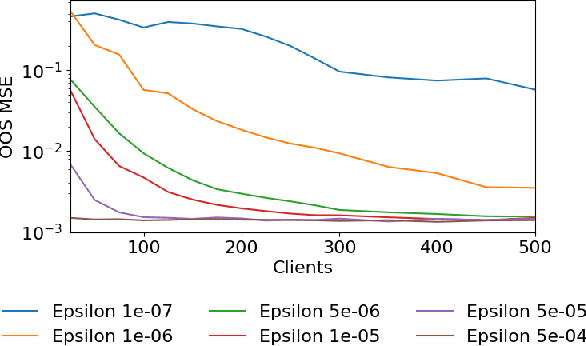
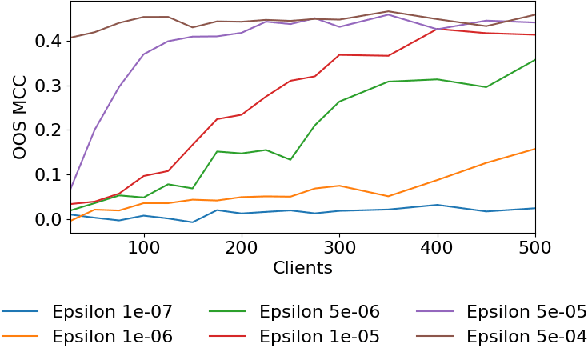
Federated Learning enables a population of clients, working with a trusted server, to collaboratively learn a shared machine learning model while keeping each client's data within its own local systems. This reduces the risk of exposing sensitive data, but it is still possible to reverse engineer information about a client's private data set from communicated model parameters. Most federated learning systems therefore use differential privacy to introduce noise to the parameters. This adds uncertainty to any attempt to reveal private client data, but also reduces the accuracy of the shared model, limiting the useful scale of privacy-preserving noise. A system can further reduce the coordinating server's ability to recover private client information, without additional accuracy loss, by also including secure multiparty computation. An approach combining both techniques is especially relevant to financial firms as it allows new possibilities for collaborative learning without exposing sensitive client data. This could produce more accurate models for important tasks like optimal trade execution, credit origination, or fraud detection. The key contributions of this paper are: We present a privacy-preserving federated learning protocol to a non-specialist audience, demonstrate it using logistic regression on a real-world credit card fraud data set, and evaluate it using an open-source simulation platform which we have adapted for the development of federated learning systems.
Intra-day Equity Price Prediction using Deep Learning as a Measure of Market Efficiency
Aug 22, 2019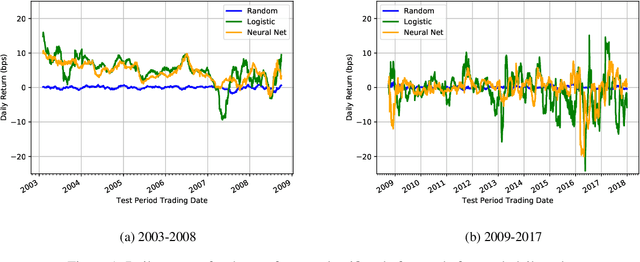
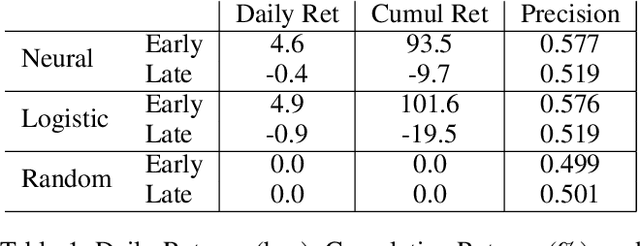
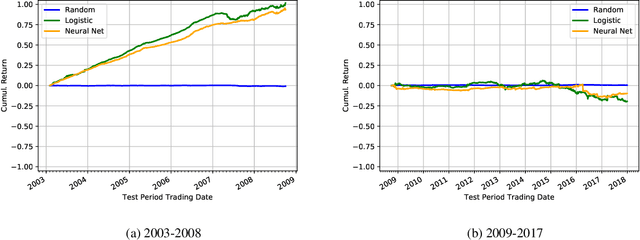

In finance, the weak form of the Efficient Market Hypothesis asserts that historic stock price and volume data cannot inform predictions of future prices. In this paper we show that, to the contrary, future intra-day stock prices could be predicted effectively until 2009. We demonstrate this using two different profitable machine learning-based trading strategies. However, the effectiveness of both approaches diminish over time, and neither of them are profitable after 2009. We present our implementation and results in detail for the period 2003-2017 and propose a novel idea: the use of such flexible machine learning methods as an objective measure of relative market efficiency. We conclude with a candidate explanation, comparing our returns over time with high-frequency trading volume, and suggest concrete steps for further investigation.