 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Patients Really Ask: Exploring the Effect of False Assumptions in Patient Information Seeking
Jan 22, 2026Patients are increasingly using large language models (LLMs) to seek answers to their healthcare-related questions. However, benchmarking efforts in LLMs for question answering often focus on medical exam questions, which differ significantly in style and content from the questions patients actually raise in real life. To bridge this gap, we sourced data from Google's People Also Ask feature by querying the top 200 prescribed medications in the United States, curating a dataset of medical questions people commonly ask. A considerable portion of the collected questions contains incorrect assumptions and dangerous intentions. We demonstrate that the emergence of these corrupted questions is not uniformly random and depends heavily on the degree of incorrectness in the history of questions that led to their appearance. Current LLMs that perform strongly on other benchmarks struggle to identify incorrect assumptions in everyday questions.
Batch-of-Thought: Cross-Instance Learning for Enhanced LLM Reasoning
Jan 06, 2026Current Large Language Model reasoning systems process queries independently, discarding valuable cross-instance signals such as shared reasoning patterns and consistency constraints. We introduce Batch-of-Thought (BoT), a training-free method that processes related queries jointly to enable cross-instance learning. By performing comparative analysis across batches, BoT identifies high-quality reasoning templates, detects errors through consistency checks, and amortizes computational costs. We instantiate BoT within a multi-agent reflection architecture (BoT-R), where a Reflector performs joint evaluation to unlock mutual information gain unavailable in isolated processing. Experiments across three model families and six benchmarks demonstrate that BoT-R consistently improves accuracy and confidence calibration while reducing inference costs by up to 61%. Our theoretical and experimental analysis reveals when and why batch-aware reasoning benefits LLM systems.
Step-DeepResearch Technical Report
Dec 24, 2025As LLMs shift toward autonomous agents, Deep Research has emerged as a pivotal metric. However, existing academic benchmarks like BrowseComp often fail to meet real-world demands for open-ended research, which requires robust skills in intent recognition, long-horizon decision-making, and cross-source verification. To address this, we introduce Step-DeepResearch, a cost-effective, end-to-end agent. We propose a Data Synthesis Strategy Based on Atomic Capabilities to reinforce planning and report writing, combined with a progressive training path from agentic mid-training to SFT and RL. Enhanced by a Checklist-style Judger, this approach significantly improves robustness. Furthermore, to bridge the evaluation gap in the Chinese domain, we establish ADR-Bench for realistic deep research scenarios. Experimental results show that Step-DeepResearch (32B) scores 61.4% on Scale AI Research Rubrics. On ADR-Bench, it significantly outperforms comparable models and rivals SOTA closed-source models like OpenAI and Gemini DeepResearch. These findings prove that refined training enables medium-sized models to achieve expert-level capabilities at industry-leading cost-efficiency.
Counting Clues: A Lightweight Probabilistic Baseline Can Match an LLM
Dec 14, 2025Large language models (LLMs) excel on multiple-choice clinical diagnosis benchmarks, yet it is unclear how much of this performance reflects underlying probabilistic reasoning. We study this through questions from MedQA, where the task is to select the most likely diagnosis. We introduce the Frequency-Based Probabilistic Ranker (FBPR), a lightweight method that scores options with a smoothed Naive Bayes over concept-diagnosis co-occurrence statistics from a large corpus. When co-occurrence statistics were sourced from the pretraining corpora for OLMo and Llama, FBPR achieves comparable performance to the corresponding LLMs pretrained on that same corpus. Direct LLM inference and FBPR largely get different questions correct, with an overlap only slightly above random chance, indicating complementary strengths of each method. These findings highlight the continued value of explicit probabilistic baselines: they provide a meaningful performance reference point and a complementary signal for potential hybridization. While the performance of LLMs seems to be driven by a mechanism other than simple frequency aggregation, we show that an approach similar to the historically grounded, low-complexity expert systems still accounts for a substantial portion of benchmark performance.
Diagnosing our datasets: How does my language model learn clinical information?
May 21, 2025Large language models (LLMs) have performed well across various clinical natural language processing tasks, despite not being directly trained on electronic health record (EHR) data. In this work, we examine how popular open-source LLMs learn clinical information from large mined corpora through two crucial but understudied lenses: (1) their interpretation of clinical jargon, a foundational ability for understanding real-world clinical notes, and (2) their responses to unsupported medical claims. For both use cases, we investigate the frequency of relevant clinical information in their corresponding pretraining corpora, the relationship between pretraining data composition and model outputs, and the sources underlying this data. To isolate clinical jargon understanding, we evaluate LLMs on a new dataset MedLingo. Unsurprisingly, we find that the frequency of clinical jargon mentions across major pretraining corpora correlates with model performance. However, jargon frequently appearing in clinical notes often rarely appears in pretraining corpora, revealing a mismatch between available data and real-world usage. Similarly, we find that a non-negligible portion of documents support disputed claims that can then be parroted by models. Finally, we classified and analyzed the types of online sources in which clinical jargon and unsupported medical claims appear, with implications for future dataset composition.
TEMPO: Prompt-based Generative Pre-trained Transformer for Time Series Forecasting
Oct 12, 2023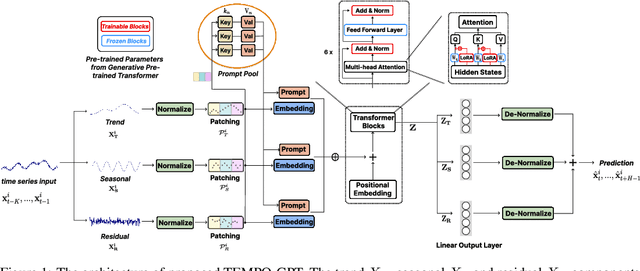
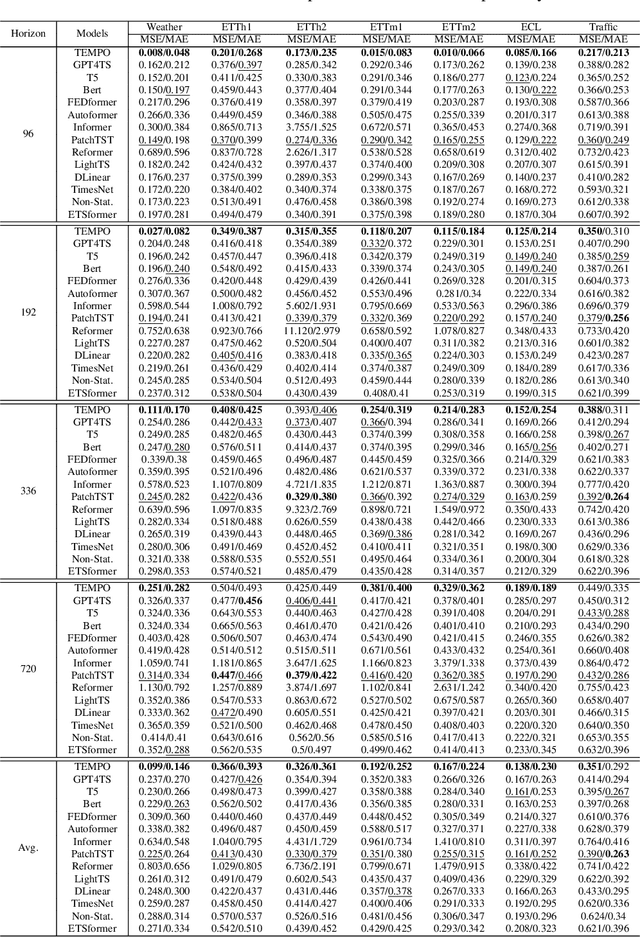


The past decade has witnessed significant advances in time series modeling with deep learning. While achieving state-of-the-art results, the best-performing architectures vary highly across applications and domains. Meanwhile, for natural language processing, the Generative Pre-trained Transformer (GPT) has demonstrated impressive performance via training one general-purpose model across various textual datasets. It is intriguing to explore whether GPT-type architectures can be effective for time series, capturing the intrinsic dynamic attributes and leading to significant accuracy improvements. In this paper, we propose a novel framework, TEMPO, that can effectively learn time series representations. We focus on utilizing two essential inductive biases of the time series task for pre-trained models: (i) decomposition of the complex interaction between trend, seasonal and residual components; and (ii) introducing the selection-based prompts to facilitate distribution adaptation in non-stationary time series. TEMPO expands the capability for dynamically modeling real-world temporal phenomena from data within diverse domains. Our experiments demonstrate the superior performance of TEMPO over state-of-the-art methods on a number of time series benchmark datasets. This performance gain is observed not only in standard supervised learning settings but also in scenarios involving previously unseen datasets as well as in scenarios with multi-modal inputs. This compelling finding highlights TEMPO's potential to constitute a foundational model-building framework.
I2I: Initializing Adapters with Improvised Knowledge
Apr 04, 2023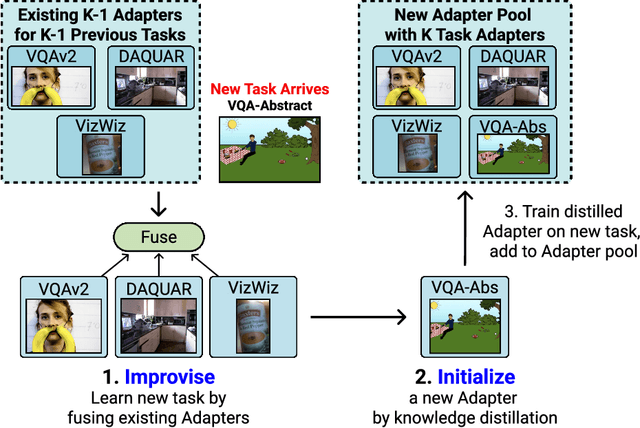

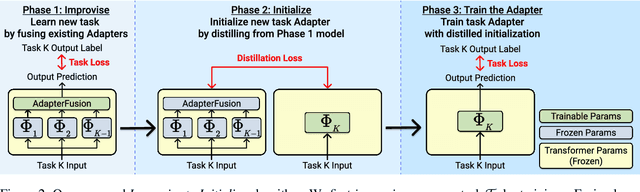

Adapters present a promising solution to the catastrophic forgetting problem in continual learning. However, training independent Adapter modules for every new task misses an opportunity for cross-task knowledge transfer. We propose Improvise to Initialize (I2I), a continual learning algorithm that initializes Adapters for incoming tasks by distilling knowledge from previously-learned tasks' Adapters. We evaluate I2I on CLiMB, a multimodal continual learning benchmark, by conducting experiments on sequences of visual question answering tasks. Adapters trained with I2I consistently achieve better task accuracy than independently-trained Adapters, demonstrating that our algorithm facilitates knowledge transfer between task Adapters. I2I also results in better cross-task knowledge transfer than the state-of-the-art AdapterFusion without incurring the associated parametric cost.