 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKG-CMI: Knowledge graph enhanced cross-Mamba interaction for medical visual question answering
Apr 01, 2026Medical visual question answering (Med-VQA) is a crucial multimodal task in clinical decision support and telemedicine. Recent methods fail to fully leverage domain-specific medical knowledge, making it difficult to accurately associate lesion features in medical images with key diagnostic criteria. Additionally, classification-based approaches typically rely on predefined answer sets. Treating Med-VQA as a simple classification problem limits its ability to adapt to the diversity of free-form answers and may overlook detailed semantic information in those answers. To address these challenges, we propose a knowledge graph enhanced cross-Mamba interaction (KG-CMI) framework, which consists of a fine-grained cross-modal feature alignment (FCFA) module, a knowledge graph embedding (KGE) module, a cross-modal interaction representation (CMIR) module, and a free-form answer enhanced multi-task learning (FAMT) module. The KG-CMI learns cross-modal feature representations for images and texts by effectively integrating professional medical knowledge through a graph, establishing associations between lesion features and disease knowledge. Moreover, FAMT leverages auxiliary knowledge from open-ended questions, improving the model's capability for open-ended Med-VQA. Experimental results demonstrate that KG-CMI outperforms existing state-of-the-art methods on three Med-VQA datasets, i.e., VQA-RAD, SLAKE, and OVQA. Additionally, we conduct interpretability experiments to further validate the framework's effectiveness.
SHAPE: Structure-aware Hierarchical Unsupervised Domain Adaptation with Plausibility Evaluation for Medical Image Segmentation
Mar 23, 2026Unsupervised Domain Adaptation (UDA) is essential for deploying medical segmentation models across diverse clinical environments. Existing methods are fundamentally limited, suffering from semantically unaware feature alignment that results in poor distributional fidelity and from pseudo-label validation that disregards global anatomical constraints, thus failing to prevent the formation of globally implausible structures. To address these issues, we propose SHAPE (Structure-aware Hierarchical Unsupervised Domain Adaptation with Plausibility Evaluation), a framework that reframes adaptation towards global anatomical plausibility. Built on a DINOv3 foundation, its Hierarchical Feature Modulation (HFM) module first generates features with both high fidelity and class-awareness. This shifts the core challenge to robustly validating pseudo-labels. To augment conventional pixel-level validation, we introduce Hypergraph Plausibility Estimation (HPE), which leverages hypergraphs to assess the global anatomical plausibility that standard graphs cannot capture. This is complemented by Structural Anomaly Pruning (SAP) to purge remaining artifacts via cross-view stability. SHAPE significantly outperforms prior methods on cardiac and abdominal cross-modality benchmarks, achieving state-of-the-art average Dice scores of 90.08% (MRI->CT) and 78.51% (CT->MRI) on cardiac data, and 87.48% (MRI->CT) and 86.89% (CT->MRI) on abdominal data. The code is available at https://github.com/BioMedIA-repo/SHAPE.
DeepDR: an integrated deep-learning model web server for drug repositioning
Nov 12, 2025Background: Identifying new indications for approved drugs is a complex and time-consuming process that requires extensive knowledge of pharmacology, clinical data, and advanced computational methods. Recently, deep learning (DL) methods have shown their capability for the accurate prediction of drug repositioning. However, implementing DL-based modeling requires in-depth domain knowledge and proficient programming skills. Results: In this application, we introduce DeepDR, the first integrated platform that combines a variety of established DL-based models for disease- and target-specific drug repositioning tasks. DeepDR leverages invaluable experience to recommend candidate drugs, which covers more than 15 networks and a comprehensive knowledge graph that includes 5.9 million edges across 107 types of relationships connecting drugs, diseases, proteins/genes, pathways, and expression from six existing databases and a large scientific corpus of 24 million PubMed publications. Additionally, the recommended results include detailed descriptions of the recommended drugs and visualize key patterns with interpretability through a knowledge graph. Conclusion: DeepDR is free and open to all users without the requirement of registration. We believe it can provide an easy-to-use, systematic, highly accurate, and computationally automated platform for both experimental and computational scientists.
ERSR: An Ellipse-constrained pseudo-label refinement and symmetric regularization framework for semi-supervised fetal head segmentation in ultrasound images
Aug 27, 2025
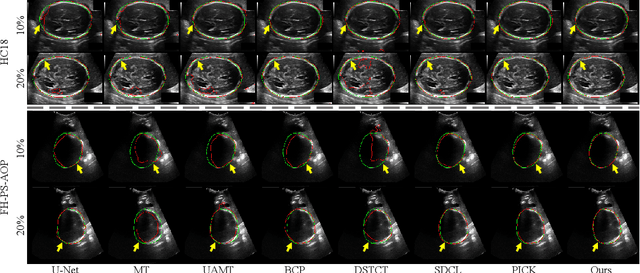

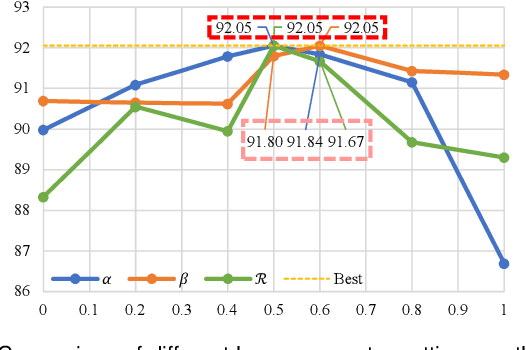
Automated segmentation of the fetal head in ultrasound images is critical for prenatal monitoring. However, achieving robust segmentation remains challenging due to the poor quality of ultrasound images and the lack of annotated data. Semi-supervised methods alleviate the lack of annotated data but struggle with the unique characteristics of fetal head ultrasound images, making it challenging to generate reliable pseudo-labels and enforce effective consistency regularization constraints. To address this issue, we propose a novel semi-supervised framework, ERSR, for fetal head ultrasound segmentation. Our framework consists of the dual-scoring adaptive filtering strategy, the ellipse-constrained pseudo-label refinement, and the symmetry-based multiple consistency regularization. The dual-scoring adaptive filtering strategy uses boundary consistency and contour regularity criteria to evaluate and filter teacher outputs. The ellipse-constrained pseudo-label refinement refines these filtered outputs by fitting least-squares ellipses, which strengthens pixels near the center of the fitted ellipse and suppresses noise simultaneously. The symmetry-based multiple consistency regularization enforces multi-level consistency across perturbed images, symmetric regions, and between original predictions and pseudo-labels, enabling the model to capture robust and stable shape representations. Our method achieves state-of-the-art performance on two benchmarks. On the HC18 dataset, it reaches Dice scores of 92.05% and 95.36% with 10% and 20% labeled data, respectively. On the PSFH dataset, the scores are 91.68% and 93.70% under the same settings.
Iterative pseudo-labeling based adaptive copy-paste supervision for semi-supervised tumor segmentation
Aug 06, 2025Semi-supervised learning (SSL) has attracted considerable attention in medical image processing. The latest SSL methods use a combination of consistency regularization and pseudo-labeling to achieve remarkable success. However, most existing SSL studies focus on segmenting large organs, neglecting the challenging scenarios where there are numerous tumors or tumors of small volume. Furthermore, the extensive capabilities of data augmentation strategies, particularly in the context of both labeled and unlabeled data, have yet to be thoroughly investigated. To tackle these challenges, we introduce a straightforward yet effective approach, termed iterative pseudo-labeling based adaptive copy-paste supervision (IPA-CP), for tumor segmentation in CT scans. IPA-CP incorporates a two-way uncertainty based adaptive augmentation mechanism, aiming to inject tumor uncertainties present in the mean teacher architecture into adaptive augmentation. Additionally, IPA-CP employs an iterative pseudo-label transition strategy to generate more robust and informative pseudo labels for the unlabeled samples. Extensive experiments on both in-house and public datasets show that our framework outperforms state-of-the-art SSL methods in medical image segmentation. Ablation study results demonstrate the effectiveness of our technical contributions.
Location embedding based pairwise distance learning for fine-grained diagnosis of urinary stones
Jun 29, 2024The precise diagnosis of urinary stones is crucial for devising effective treatment strategies. The diagnostic process, however, is often complicated by the low contrast between stones and surrounding tissues, as well as the variability in stone locations across different patients. To address this issue, we propose a novel location embedding based pairwise distance learning network (LEPD-Net) that leverages low-dose abdominal X-ray imaging combined with location information for the fine-grained diagnosis of urinary stones. LEPD-Net enhances the representation of stone-related features through context-aware region enhancement, incorporates critical location knowledge via stone location embedding, and achieves recognition of fine-grained objects with our innovative fine-grained pairwise distance learning. Additionally, we have established an in-house dataset on urinary tract stones to demonstrate the effectiveness of our proposed approach. Comprehensive experiments conducted on this dataset reveal that our framework significantly surpasses existing state-of-the-art methods.
Inter- and intra-uncertainty based feature aggregation model for semi-supervised histopathology image segmentation
Mar 19, 2024Acquiring pixel-level annotations is often limited in applications such as histology studies that require domain expertise. Various semi-supervised learning approaches have been developed to work with limited ground truth annotations, such as the popular teacher-student models. However, hierarchical prediction uncertainty within the student model (intra-uncertainty) and image prediction uncertainty (inter-uncertainty) have not been fully utilized by existing methods. To address these issues, we first propose a novel inter- and intra-uncertainty regularization method to measure and constrain both inter- and intra-inconsistencies in the teacher-student architecture. We also propose a new two-stage network with pseudo-mask guided feature aggregation (PG-FANet) as the segmentation model. The two-stage structure complements with the uncertainty regularization strategy to avoid introducing extra modules in solving uncertainties and the aggregation mechanisms enable multi-scale and multi-stage feature integration. Comprehensive experimental results over the MoNuSeg and CRAG datasets show that our PG-FANet outperforms other state-of-the-art methods and our semi-supervised learning framework yields competitive performance with a limited amount of labeled data.
MolCAP: Molecular Chemical reActivity pretraining and prompted-finetuning enhanced molecular representation learning
Jun 13, 2023



Molecular representation learning (MRL) is a fundamental task for drug discovery. However, previous deep-learning (DL) methods focus excessively on learning robust inner-molecular representations by mask-dominated pretraining framework, neglecting abundant chemical reactivity molecular relationships that have been demonstrated as the determining factor for various molecular property prediction tasks. Here, we present MolCAP to promote MRL, a graph pretraining Transformer based on chemical reactivity (IMR) knowledge with prompted finetuning. Results show that MolCAP outperforms comparative methods based on traditional molecular pretraining framework, in 13 publicly available molecular datasets across a diversity of biomedical tasks. Prompted by MolCAP, even basic graph neural networks are capable of achieving surprising performance that outperforms previous models, indicating the promising prospect of applying reactivity information for MRL. In addition, manual designed molecular templets are potential to uncover the dataset bias. All in all, we expect our MolCAP to gain more chemical meaningful insights for the entire process of drug discovery.
Multi-view deep learning based molecule design and structural optimization accelerates the SARS-CoV-2 inhibitor discovery
Dec 03, 2022In this work, we propose MEDICO, a Multi-viEw Deep generative model for molecule generation, structural optimization, and the SARS-CoV-2 Inhibitor disCOvery. To the best of our knowledge, MEDICO is the first-of-this-kind graph generative model that can generate molecular graphs similar to the structure of targeted molecules, with a multi-view representation learning framework to sufficiently and adaptively learn comprehensive structural semantics from targeted molecular topology and geometry. We show that our MEDICO significantly outperforms the state-of-the-art methods in generating valid, unique, and novel molecules under benchmarking comparisons. In particular, we showcase the multi-view deep learning model enables us to generate not only the molecules structurally similar to the targeted molecules but also the molecules with desired chemical properties, demonstrating the strong capability of our model in exploring the chemical space deeply. Moreover, case study results on targeted molecule generation for the SARS-CoV-2 main protease (Mpro) show that by integrating molecule docking into our model as chemical priori, we successfully generate new small molecules with desired drug-like properties for the Mpro, potentially accelerating the de novo design of Covid-19 drugs. Further, we apply MEDICO to the structural optimization of three well-known Mpro inhibitors (N3, 11a, and GC376) and achieve ~88% improvement in their binding affinity to Mpro, demonstrating the application value of our model for the development of therapeutics for SARS-CoV-2 infection.
MSMG-Net: Multi-scale Multi-grained Supervised Metworks for Multi-task Image Manipulation Detection and Localization
Nov 06, 2022



With the rapid advances of image editing techniques in recent years, image manipulation detection has attracted considerable attention since the increasing security risks posed by tampered images. To address these challenges, a novel multi-scale multi-grained deep network (MSMG-Net) is proposed to automatically identify manipulated regions. In our MSMG-Net, a parallel multi-scale feature extraction structure is used to extract multi-scale features. Then the multi-grained feature learning is utilized to perceive object-level semantics relation of multi-scale features by introducing the shunted self-attention. To fuse multi-scale multi-grained features, global and local feature fusion block are designed for manipulated region segmentation by a bottom-up approach and multi-level feature aggregation block is designed for edge artifacts detection by a top-down approach. Thus, MSMG-Net can effectively perceive the object-level semantics and encode the edge artifact. Experimental results on five benchmark datasets justify the superior performance of the proposed method, outperforming state-of-the-art manipulation detection and localization methods. Extensive ablation experiments and feature visualization demonstrate the multi-scale multi-grained learning can present effective visual representations of manipulated regions. In addition, MSMG-Net shows better robustness when various post-processing methods further manipulate images.