 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Light Object Tracking: A Benchmark
Aug 21, 2024In recent years, the field of visual tracking has made significant progress with the application of large-scale training datasets. These datasets have supported the development of sophisticated algorithms, enhancing the accuracy and stability of visual object tracking. However, most research has primarily focused on favorable illumination circumstances, neglecting the challenges of tracking in low-ligh environments. In low-light scenes, lighting may change dramatically, targets may lack distinct texture features, and in some scenarios, targets may not be directly observable. These factors can lead to a severe decline in tracking performance. To address this issue, we introduce LLOT, a benchmark specifically designed for Low-Light Object Tracking. LLOT comprises 269 challenging sequences with a total of over 132K frames, each carefully annotated with bounding boxes. This specially designed dataset aims to promote innovation and advancement in object tracking techniques for low-light conditions, addressing challenges not adequately covered by existing benchmarks. To assess the performance of existing methods on LLOT, we conducted extensive tests on 39 state-of-the-art tracking algorithms. The results highlight a considerable gap in low-light tracking performance. In response, we propose H-DCPT, a novel tracker that incorporates historical and darkness clue prompts to set a stronger baseline. H-DCPT outperformed all 39 evaluated methods in our experiments, demonstrating significant improvements. We hope that our benchmark and H-DCPT will stimulate the development of novel and accurate methods for tracking objects in low-light conditions. The LLOT and code are available at https://github.com/OpenCodeGithub/H-DCPT.
Eyes Can Deceive: Benchmarking Counterfactual Reasoning Abilities of Multi-modal Large Language Models
Apr 19, 2024



Counterfactual reasoning, as a crucial manifestation of human intelligence, refers to making presuppositions based on established facts and extrapolating potential outcomes. Existing multimodal large language models (MLLMs) have exhibited impressive cognitive and reasoning capabilities, which have been examined across a wide range of Visual Question Answering (VQA) benchmarks. Nevertheless, how will existing MLLMs perform when faced with counterfactual questions? To answer this question, we first curate a novel \textbf{C}ounter\textbf{F}actual \textbf{M}ulti\textbf{M}odal reasoning benchmark, abbreviated as \textbf{CFMM}, to systematically assess the counterfactual reasoning capabilities of MLLMs. Our CFMM comprises six challenging tasks, each including hundreds of carefully human-labeled counterfactual questions, to evaluate MLLM's counterfactual reasoning capabilities across diverse aspects. Through experiments, interestingly, we find that existing MLLMs prefer to believe what they see, but ignore the counterfactual presuppositions presented in the question, thereby leading to inaccurate responses. Furthermore, we evaluate a wide range of prevalent MLLMs on our proposed CFMM. The significant gap between their performance on our CFMM and that on several VQA benchmarks indicates that there is still considerable room for improvement in existing MLLMs toward approaching human-level intelligence. On the other hand, through boosting MLLMs performances on our CFMM in the future, potential avenues toward developing MLLMs with advanced intelligence can be explored.
Flow-Attention-based Spatio-Temporal Aggregation Network for 3D Mask Detection
Oct 25, 2023Anti-spoofing detection has become a necessity for face recognition systems due to the security threat posed by spoofing attacks. Despite great success in traditional attacks, most deep-learning-based methods perform poorly in 3D masks, which can highly simulate real faces in appearance and structure, suffering generalizability insufficiency while focusing only on the spatial domain with single frame input. This has been mitigated by the recent introduction of a biomedical technology called rPPG (remote photoplethysmography). However, rPPG-based methods are sensitive to noisy interference and require at least one second (> 25 frames) of observation time, which induces high computational overhead. To address these challenges, we propose a novel 3D mask detection framework, called FASTEN (Flow-Attention-based Spatio-Temporal aggrEgation Network). We tailor the network for focusing more on fine-grained details in large movements, which can eliminate redundant spatio-temporal feature interference and quickly capture splicing traces of 3D masks in fewer frames. Our proposed network contains three key modules: 1) a facial optical flow network to obtain non-RGB inter-frame flow information; 2) flow attention to assign different significance to each frame; 3) spatio-temporal aggregation to aggregate high-level spatial features and temporal transition features. Through extensive experiments, FASTEN only requires five frames of input and outperforms eight competitors for both intra-dataset and cross-dataset evaluations in terms of multiple detection metrics. Moreover, FASTEN has been deployed in real-world mobile devices for practical 3D mask detection.
Pre-training Universal Language Representation
May 30, 2021

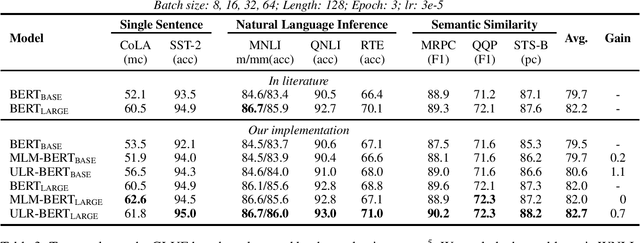
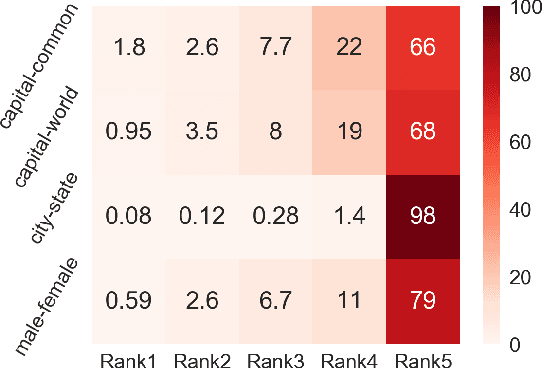
Despite the well-developed cut-edge representation learning for language, most language representation models usually focus on specific levels of linguistic units. This work introduces universal language representation learning, i.e., embeddings of different levels of linguistic units or text with quite diverse lengths in a uniform vector space. We propose the training objective MiSAD that utilizes meaningful n-grams extracted from large unlabeled corpus by a simple but effective algorithm for pre-trained language models. Then we empirically verify that well designed pre-training scheme may effectively yield universal language representation, which will bring great convenience when handling multiple layers of linguistic objects in a unified way. Especially, our model achieves the highest accuracy on analogy tasks in different language levels and significantly improves the performance on downstream tasks in the GLUE benchmark and a question answering dataset.
BURT: BERT-inspired Universal Representation from Learning Meaningful Segment
Dec 31, 2020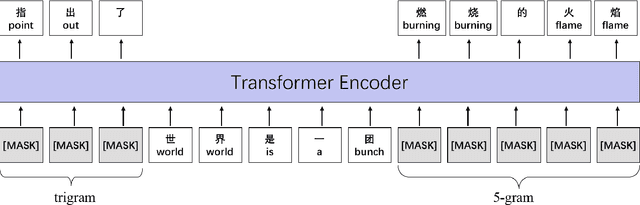
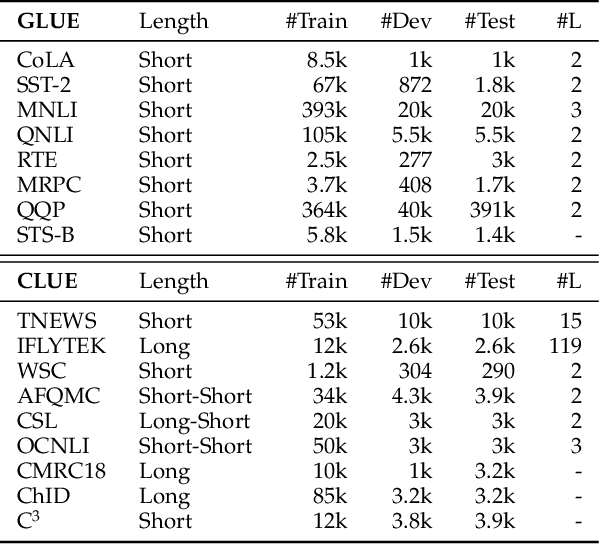
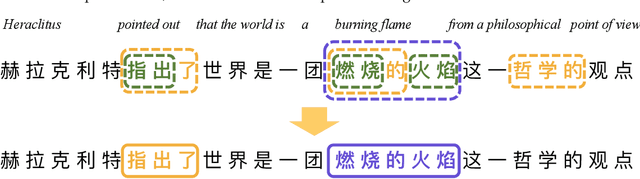
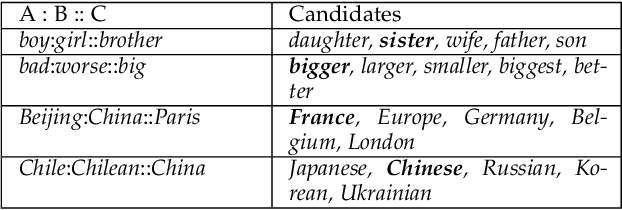
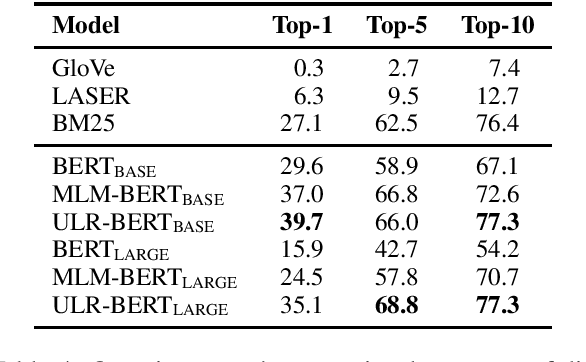
Although pre-trained contextualized language models such as BERT achieve significant performance on various downstream tasks, current language representation still only focuses on linguistic objective at a specific granularity, which may not applicable when multiple levels of linguistic units are involved at the same time. Thus this work introduces and explores the universal representation learning, i.e., embeddings of different levels of linguistic unit in a uniform vector space. We present a universal representation model, BURT (BERT-inspired Universal Representation from learning meaningful segmenT), to encode different levels of linguistic unit into the same vector space. Specifically, we extract and mask meaningful segments based on point-wise mutual information (PMI) to incorporate different granular objectives into the pre-training stage. We conduct experiments on datasets for English and Chinese including the GLUE and CLUE benchmarks, where our model surpasses its baselines and alternatives on a wide range of downstream tasks. We present our approach of constructing analogy datasets in terms of words, phrases and sentences and experiment with multiple representation models to examine geometric properties of the learned vector space through a task-independent evaluation. Finally, we verify the effectiveness of our unified pre-training strategy in two real-world text matching scenarios. As a result, our model significantly outperforms existing information retrieval (IR) methods and yields universal representations that can be directly applied to retrieval-based question-answering and natural language generation tasks.
Learning Universal Representations from Word to Sentence
Sep 10, 2020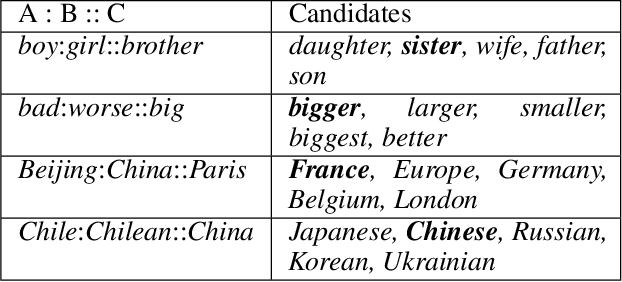

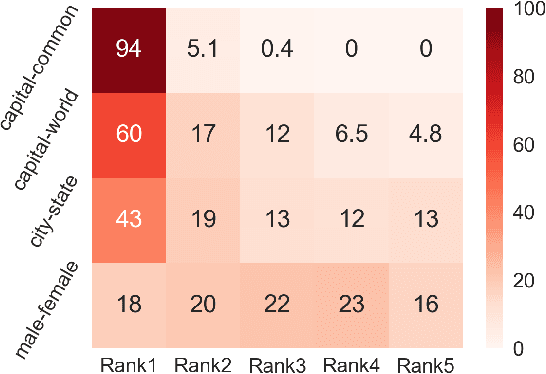
Despite the well-developed cut-edge representation learning for language, most language representation models usually focus on specific level of linguistic unit, which cause great inconvenience when being confronted with handling multiple layers of linguistic objects in a unified way. Thus this work introduces and explores the universal representation learning, i.e., embeddings of different levels of linguistic unit in a uniform vector space through a task-independent evaluation. We present our approach of constructing analogy datasets in terms of words, phrases and sentences and experiment with multiple representation models to examine geometric properties of the learned vector space. Then we empirically verify that well pre-trained Transformer models incorporated with appropriate training settings may effectively yield universal representation. Especially, our implementation of fine-tuning ALBERT on NLI and PPDB datasets achieves the highest accuracy on analogy tasks in different language levels. Further experiments on the insurance FAQ task show effectiveness of universal representation models in real-world applications.
Learning Better Universal Representations from Pre-trained Contextualized Language Models
Apr 29, 2020
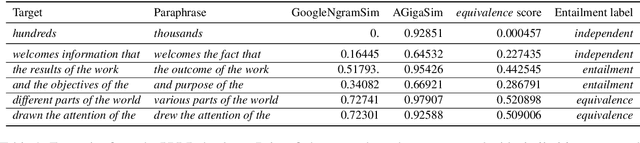
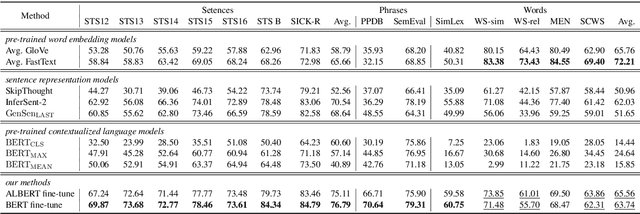
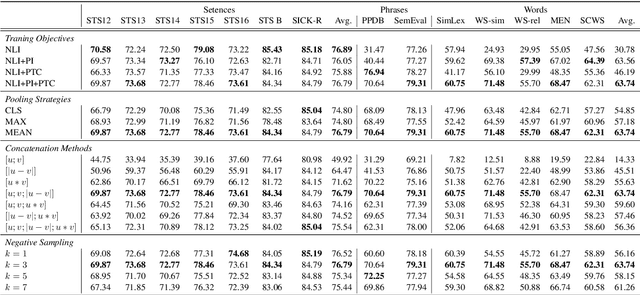
Pre-trained contextualized language models such as BERT have shown great effectiveness in a wide range of downstream natural language processing (NLP) tasks. However, the effective representations offered by the models target at each token inside a sequence rather than each sequence and the fine-tuning step involves the input of both sequences at one time, leading to unsatisfying representation of each individual sequence. Besides, as sentence-level representations taken as the full training context in these models, there comes inferior performance on lower-level linguistic units (phrases and words). In this work, we present a novel framework on BERT that is capable of generating universal, fixed-size representations for input sequences of any lengths, i.e., words, phrases, and sentences, using a large scale of natural language inference and paraphrase data with multiple training objectives. Our proposed framework adopts the Siamese network, learning sentence-level representations from natural language inference dataset and phrase and word-level representations from paraphrasing dataset, respectively. We evaluate our model across different granularity of text similarity tasks, including STS tasks, SemEval2013 Task 5(a) and some commonly used word similarity tasks, where our model substantially outperforms other representation models on sentence-level datasets and achieves significant improvements in word-level and phrase-level representation.