 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Universal Representations from Word to Sentence
Paper and Code
Sep 10, 2020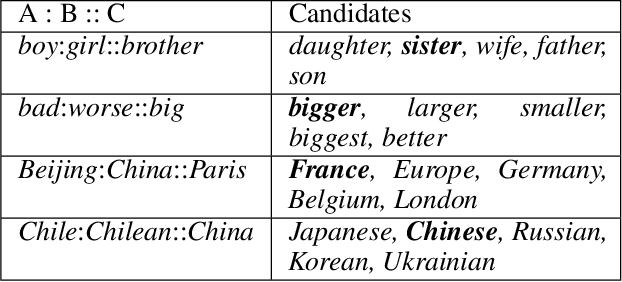
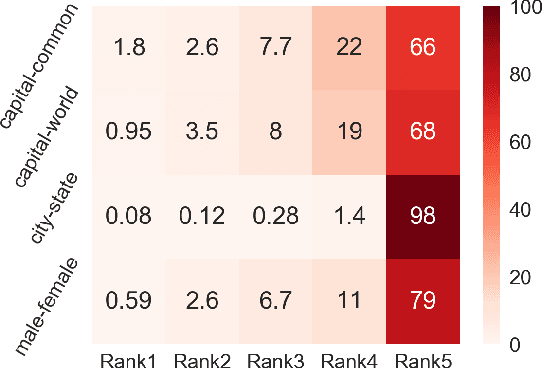

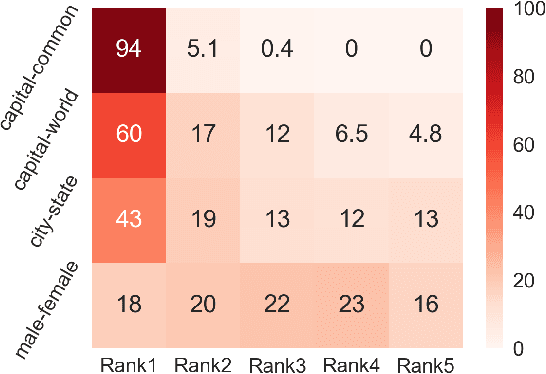
Despite the well-developed cut-edge representation learning for language, most language representation models usually focus on specific level of linguistic unit, which cause great inconvenience when being confronted with handling multiple layers of linguistic objects in a unified way. Thus this work introduces and explores the universal representation learning, i.e., embeddings of different levels of linguistic unit in a uniform vector space through a task-independent evaluation. We present our approach of constructing analogy datasets in terms of words, phrases and sentences and experiment with multiple representation models to examine geometric properties of the learned vector space. Then we empirically verify that well pre-trained Transformer models incorporated with appropriate training settings may effectively yield universal representation. Especially, our implementation of fine-tuning ALBERT on NLI and PPDB datasets achieves the highest accuracy on analogy tasks in different language levels. Further experiments on the insurance FAQ task show effectiveness of universal representation models in real-world applications.