 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBURT: BERT-inspired Universal Representation from Learning Meaningful Segment
Paper and Code
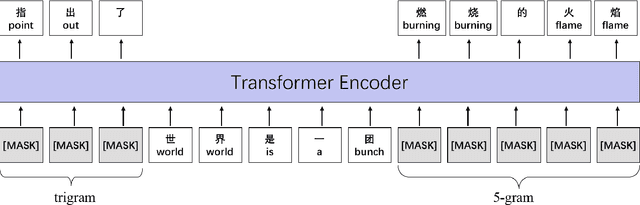
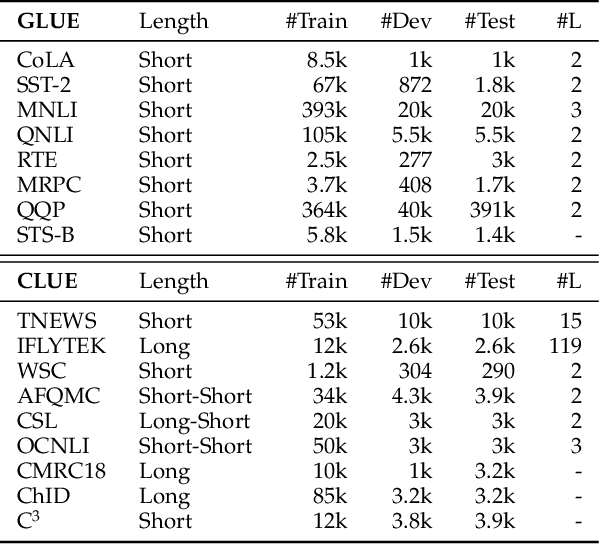
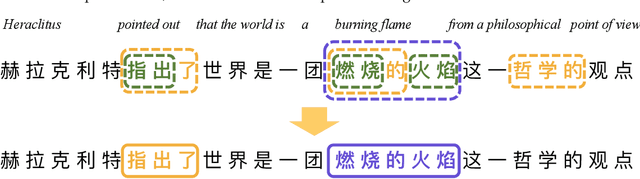
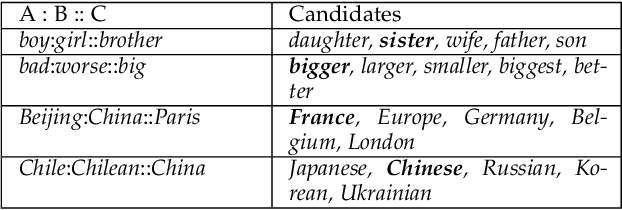
Although pre-trained contextualized language models such as BERT achieve significant performance on various downstream tasks, current language representation still only focuses on linguistic objective at a specific granularity, which may not applicable when multiple levels of linguistic units are involved at the same time. Thus this work introduces and explores the universal representation learning, i.e., embeddings of different levels of linguistic unit in a uniform vector space. We present a universal representation model, BURT (BERT-inspired Universal Representation from learning meaningful segmenT), to encode different levels of linguistic unit into the same vector space. Specifically, we extract and mask meaningful segments based on point-wise mutual information (PMI) to incorporate different granular objectives into the pre-training stage. We conduct experiments on datasets for English and Chinese including the GLUE and CLUE benchmarks, where our model surpasses its baselines and alternatives on a wide range of downstream tasks. We present our approach of constructing analogy datasets in terms of words, phrases and sentences and experiment with multiple representation models to examine geometric properties of the learned vector space through a task-independent evaluation. Finally, we verify the effectiveness of our unified pre-training strategy in two real-world text matching scenarios. As a result, our model significantly outperforms existing information retrieval (IR) methods and yields universal representations that can be directly applied to retrieval-based question-answering and natural language generation tasks.