 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Better Universal Representations from Pre-trained Contextualized Language Models
Paper and Code

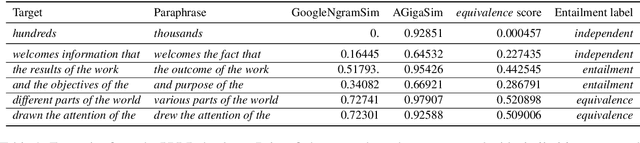
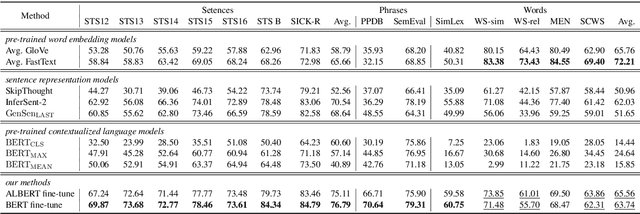
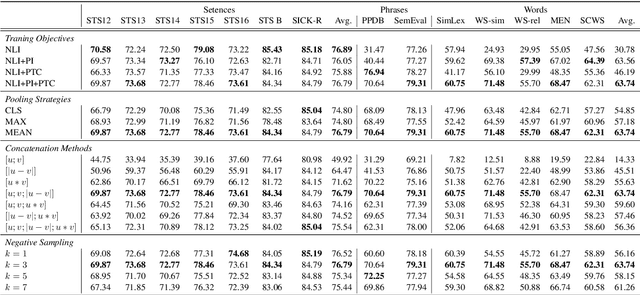
Pre-trained contextualized language models such as BERT have shown great effectiveness in a wide range of downstream natural language processing (NLP) tasks. However, the effective representations offered by the models target at each token inside a sequence rather than each sequence and the fine-tuning step involves the input of both sequences at one time, leading to unsatisfying representation of each individual sequence. Besides, as sentence-level representations taken as the full training context in these models, there comes inferior performance on lower-level linguistic units (phrases and words). In this work, we present a novel framework on BERT that is capable of generating universal, fixed-size representations for input sequences of any lengths, i.e., words, phrases, and sentences, using a large scale of natural language inference and paraphrase data with multiple training objectives. Our proposed framework adopts the Siamese network, learning sentence-level representations from natural language inference dataset and phrase and word-level representations from paraphrasing dataset, respectively. We evaluate our model across different granularity of text similarity tasks, including STS tasks, SemEval2013 Task 5(a) and some commonly used word similarity tasks, where our model substantially outperforms other representation models on sentence-level datasets and achieves significant improvements in word-level and phrase-level representation.