 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Ride-Hailing Forecasting at DiDi with Multi-View Geospatial Representation Learning from the Web
Feb 11, 2026The proliferation of ride-hailing services has fundamentally transformed urban mobility patterns, making accurate ride-hailing forecasting crucial for optimizing passenger experience and urban transportation efficiency. However, ride-hailing forecasting faces significant challenges due to geospatial heterogeneity and high susceptibility to external events. This paper proposes MVGR-Net(Multi-View Geospatial Representation Learning), a novel framework that addresses these challenges through a two-stage approach. In the pretraining stage, we learn comprehensive geospatial representations by integrating Points-of-Interest and temporal mobility patterns to capture regional characteristics from both semantic attribute and temporal mobility pattern views. The forecasting stage leverages these representations through a prompt-empowered framework that fine-tunes Large Language Models while incorporating external events. Extensive experiments on DiDi's real-world datasets demonstrate the state-of-the-art performance.
Embracing Imperfection: Simulating Students with Diverse Cognitive Levels Using LLM-based Agents
May 26, 2025Large language models (LLMs) are revolutionizing education, with LLM-based agents playing a key role in simulating student behavior. A major challenge in student simulation is modeling the diverse learning patterns of students at various cognitive levels. However, current LLMs, typically trained as ``helpful assistants'', target at generating perfect responses. As a result, they struggle to simulate students with diverse cognitive abilities, as they often produce overly advanced answers, missing the natural imperfections that characterize student learning and resulting in unrealistic simulations. To address this issue, we propose a training-free framework for student simulation. We begin by constructing a cognitive prototype for each student using a knowledge graph, which captures their understanding of concepts from past learning records. This prototype is then mapped to new tasks to predict student performance. Next, we simulate student solutions based on these predictions and iteratively refine them using a beam search method to better replicate realistic mistakes. To validate our approach, we construct the \texttt{Student\_100} dataset, consisting of $100$ students working on Python programming and $5,000$ learning records. Experimental results show that our method consistently outperforms baseline models, achieving $100\%$ improvement in simulation accuracy.
Rethinking the Threat and Accessibility of Adversarial Attacks against Face Recognition Systems
Jul 11, 2024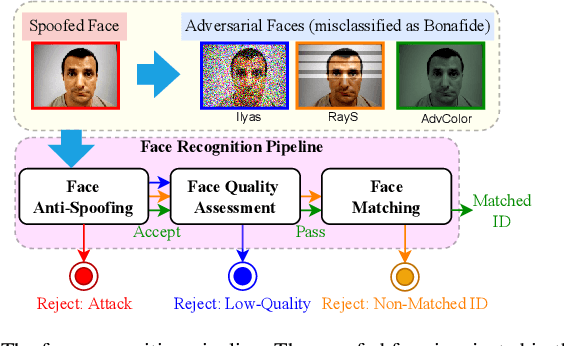
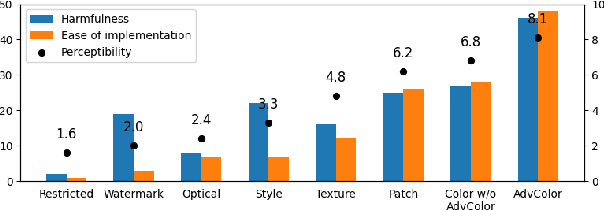
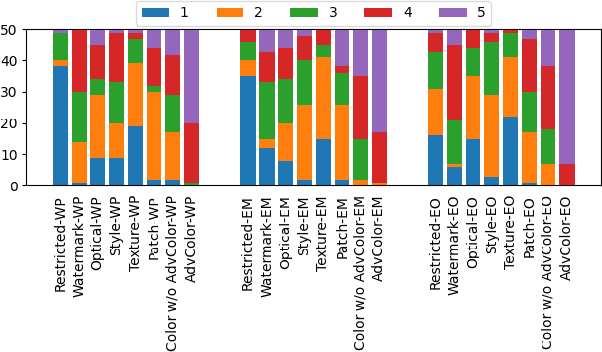

Face recognition pipelines have been widely deployed in various mission-critical systems in trust, equitable and responsible AI applications. However, the emergence of adversarial attacks has threatened the security of the entire recognition pipeline. Despite the sheer number of attack methods proposed for crafting adversarial examples in both digital and physical forms, it is never an easy task to assess the real threat level of different attacks and obtain useful insight into the key risks confronted by face recognition systems. Traditional attacks view imperceptibility as the most important measurement to keep perturbations stealthy, while we suspect that industry professionals may possess a different opinion. In this paper, we delve into measuring the threat brought about by adversarial attacks from the perspectives of the industry and the applications of face recognition. In contrast to widely studied sophisticated attacks in the field, we propose an effective yet easy-to-launch physical adversarial attack, named AdvColor, against black-box face recognition pipelines in the physical world. AdvColor fools models in the recognition pipeline via directly supplying printed photos of human faces to the system under adversarial illuminations. Experimental results show that physical AdvColor examples can achieve a fooling rate of more than 96% against the anti-spoofing model and an overall attack success rate of 88% against the face recognition pipeline. We also conduct a survey on the threats of prevailing adversarial attacks, including AdvColor, to understand the gap between the machine-measured and human-assessed threat levels of different forms of adversarial attacks. The survey results surprisingly indicate that, compared to deliberately launched imperceptible attacks, perceptible but accessible attacks pose more lethal threats to real-world commercial systems of face recognition.
Flow-Attention-based Spatio-Temporal Aggregation Network for 3D Mask Detection
Oct 25, 2023Anti-spoofing detection has become a necessity for face recognition systems due to the security threat posed by spoofing attacks. Despite great success in traditional attacks, most deep-learning-based methods perform poorly in 3D masks, which can highly simulate real faces in appearance and structure, suffering generalizability insufficiency while focusing only on the spatial domain with single frame input. This has been mitigated by the recent introduction of a biomedical technology called rPPG (remote photoplethysmography). However, rPPG-based methods are sensitive to noisy interference and require at least one second (> 25 frames) of observation time, which induces high computational overhead. To address these challenges, we propose a novel 3D mask detection framework, called FASTEN (Flow-Attention-based Spatio-Temporal aggrEgation Network). We tailor the network for focusing more on fine-grained details in large movements, which can eliminate redundant spatio-temporal feature interference and quickly capture splicing traces of 3D masks in fewer frames. Our proposed network contains three key modules: 1) a facial optical flow network to obtain non-RGB inter-frame flow information; 2) flow attention to assign different significance to each frame; 3) spatio-temporal aggregation to aggregate high-level spatial features and temporal transition features. Through extensive experiments, FASTEN only requires five frames of input and outperforms eight competitors for both intra-dataset and cross-dataset evaluations in terms of multiple detection metrics. Moreover, FASTEN has been deployed in real-world mobile devices for practical 3D mask detection.