 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAusSmoke meets MultiNatSmoke: a fully-labelled diverse smoke segmentation dataset
Apr 26, 2026Wildfires are an escalating global concern due to the devastating impacts on the environment, economy, and human health, with notable incidents such as the 2019-2020 Australian bushfires and the 2025 California wildfires underscoring the severity of these events. AI-enabled camera-based smoke detection has emerged as a promising approach for the rapid detection of wildfires. However, existing wildfire smoke segmentation datasets that are used for training detection and segmentation models are limited in scale, geographically constrained, and often rely on synthetic imagery, which hinders effective training and generalization. To overcome these limitations, we present AusSmoke, a new smoke segmentation dataset collected from Australia to address the data scarcity in this region. Furthermore, we introduce a MultiNational geographically diverse and substantially larger fully-labelled benchmark, called MultiNatSmoke, that consolidates publicly available international datasets with the newly collected Australian imagery, expanding the scale by an order of magnitude over previous collections. Finally, we benchmark smoke segmentation models, demonstrating improved performance and enhanced generalization across diverse geographical contexts. The project is available at \href{https://github.com/henryzhao0615/MultiNatSmoke}{Github}.
PraNet-V2: Dual-Supervised Reverse Attention for Medical Image Segmentation
Apr 15, 2025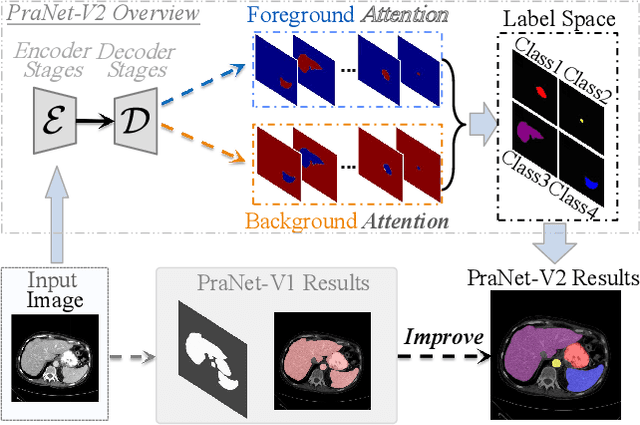
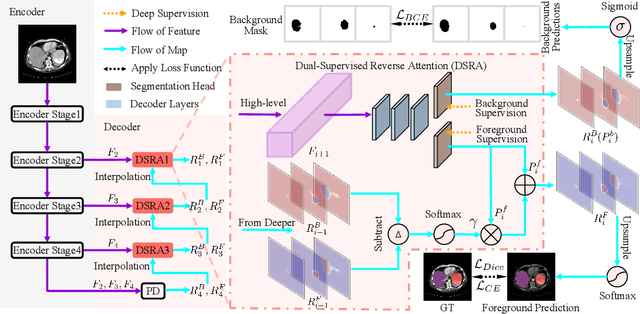
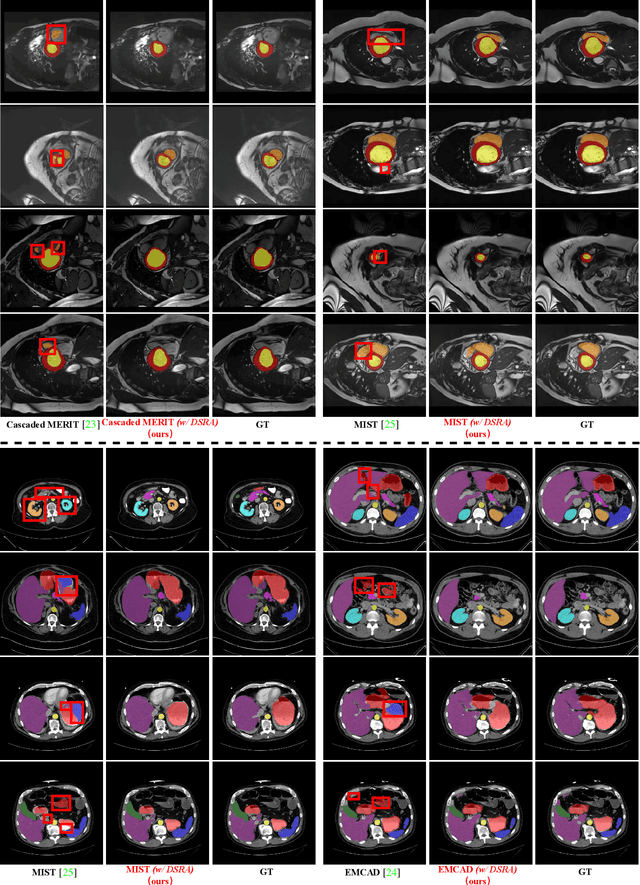
Accurate medical image segmentation is essential for effective diagnosis and treatment. Previously, PraNet-V1 was proposed to enhance polyp segmentation by introducing a reverse attention (RA) module that utilizes background information. However, PraNet-V1 struggles with multi-class segmentation tasks. To address this limitation, we propose PraNet-V2, which, compared to PraNet-V1, effectively performs a broader range of tasks including multi-class segmentation. At the core of PraNet-V2 is the Dual-Supervised Reverse Attention (DSRA) module, which incorporates explicit background supervision, independent background modeling, and semantically enriched attention fusion. Our PraNet-V2 framework demonstrates strong performance on four polyp segmentation datasets. Additionally, by integrating DSRA to iteratively enhance foreground segmentation results in three state-of-the-art semantic segmentation models, we achieve up to a 1.36% improvement in mean Dice score. Code is available at: https://github.com/ai4colonoscopy/PraNet-V2/tree/main/binary_seg/jittor.
VideoExpert: Augmented LLM for Temporal-Sensitive Video Understanding
Apr 10, 2025
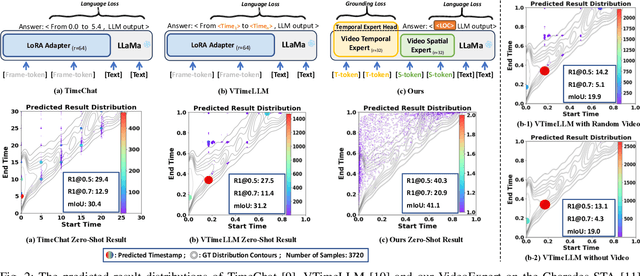
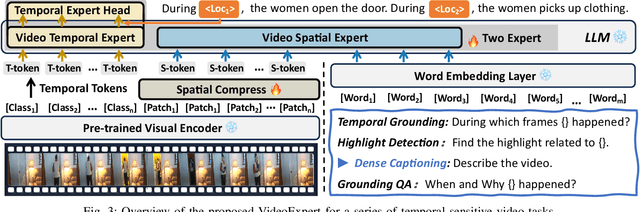
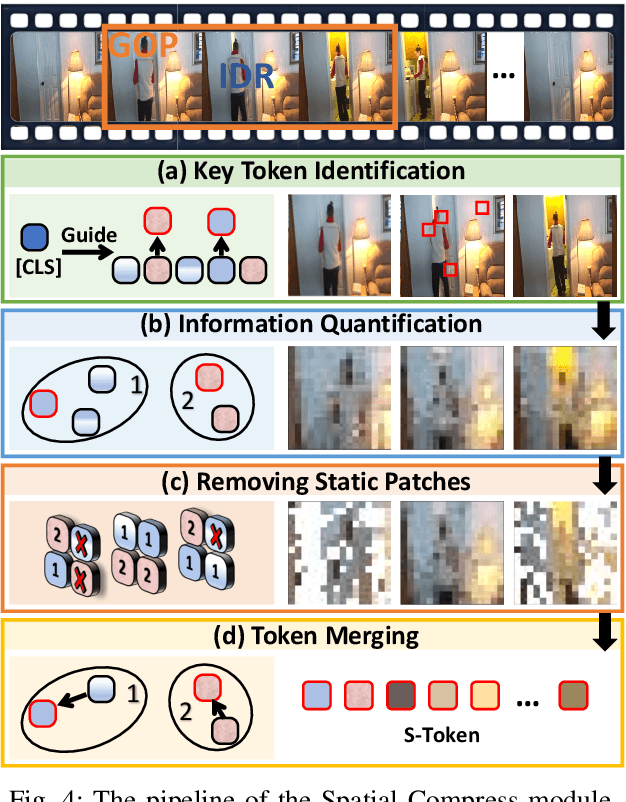
The core challenge in video understanding lies in perceiving dynamic content changes over time. However, multimodal large language models struggle with temporal-sensitive video tasks, which requires generating timestamps to mark the occurrence of specific events. Existing strategies require MLLMs to generate absolute or relative timestamps directly. We have observed that those MLLMs tend to rely more on language patterns than visual cues when generating timestamps, affecting their performance. To address this problem, we propose VideoExpert, a general-purpose MLLM suitable for several temporal-sensitive video tasks. Inspired by the expert concept, VideoExpert integrates two parallel modules: the Temporal Expert and the Spatial Expert. The Temporal Expert is responsible for modeling time sequences and performing temporal grounding. It processes high-frame-rate yet compressed tokens to capture dynamic variations in videos and includes a lightweight prediction head for precise event localization. The Spatial Expert focuses on content detail analysis and instruction following. It handles specially designed spatial tokens and language input, aiming to generate content-related responses. These two experts collaborate seamlessly via a special token, ensuring coordinated temporal grounding and content generation. Notably, the Temporal and Spatial Experts maintain independent parameter sets. By offloading temporal grounding from content generation, VideoExpert prevents text pattern biases in timestamp predictions. Moreover, we introduce a Spatial Compress module to obtain spatial tokens. This module filters and compresses patch tokens while preserving key information, delivering compact yet detail-rich input for the Spatial Expert. Extensive experiments demonstrate the effectiveness and versatility of the VideoExpert.
Frontiers in Intelligent Colonoscopy
Oct 22, 2024Colonoscopy is currently one of the most sensitive screening methods for colorectal cancer. This study investigates the frontiers of intelligent colonoscopy techniques and their prospective implications for multimodal medical applications. With this goal, we begin by assessing the current data-centric and model-centric landscapes through four tasks for colonoscopic scene perception, including classification, detection, segmentation, and vision-language understanding. This assessment enables us to identify domain-specific challenges and reveals that multimodal research in colonoscopy remains open for further exploration. To embrace the coming multimodal era, we establish three foundational initiatives: a large-scale multimodal instruction tuning dataset ColonINST, a colonoscopy-designed multimodal language model ColonGPT, and a multimodal benchmark. To facilitate ongoing monitoring of this rapidly evolving field, we provide a public website for the latest updates: https://github.com/ai4colonoscopy/IntelliScope.
Effectiveness Assessment of Recent Large Vision-Language Models
Mar 07, 2024The advent of large vision-language models (LVLMs) represents a noteworthy advancement towards the pursuit of artificial general intelligence. However, the extent of their efficacy across both specialized and general tasks warrants further investigation. This article endeavors to evaluate the competency of popular LVLMs in specialized and general tasks, respectively, aiming to offer a comprehensive comprehension of these innovative methodologies. To gauge their efficacy in specialized tasks, we tailor a comprehensive testbed comprising three distinct scenarios: natural, healthcare, and industrial, encompassing six challenging tasks. These tasks include salient, camouflaged, and transparent object detection, as well as polyp and skin lesion detection, alongside industrial anomaly detection. We examine the performance of three recent open-source LVLMs -- MiniGPT-v2, LLaVA-1.5, and Shikra -- in the realm of visual recognition and localization. Moreover, we conduct empirical investigations utilizing the aforementioned models alongside GPT-4V, assessing their multi-modal understanding capacities in general tasks such as object counting, absurd question answering, affordance reasoning, attribute recognition, and spatial relation reasoning. Our investigations reveal that these models demonstrate limited proficiency not only in specialized tasks but also in general tasks. We delve deeper into this inadequacy and suggest several potential factors, including limited cognition in specialized tasks, object hallucination, text-to-image interference, and decreased robustness in complex problems. We hope this study would provide valuable insights for the future development of LVLMs, augmenting their power in coping with both general and specialized applications.
MAST: Video Polyp Segmentation with a Mixture-Attention Siamese Transformer
Jan 23, 2024Accurate segmentation of polyps from colonoscopy videos is of great significance to polyp treatment and early prevention of colorectal cancer. However, it is challenging due to the difficulties associated with modelling long-range spatio-temporal relationships within a colonoscopy video. In this paper, we address this challenging task with a novel Mixture-Attention Siamese Transformer (MAST), which explicitly models the long-range spatio-temporal relationships with a mixture-attention mechanism for accurate polyp segmentation. Specifically, we first construct a Siamese transformer architecture to jointly encode paired video frames for their feature representations. We then design a mixture-attention module to exploit the intra-frame and inter-frame correlations, enhancing the features with rich spatio-temporal relationships. Finally, the enhanced features are fed to two parallel decoders for predicting the segmentation maps. To the best of our knowledge, our MAST is the first transformer model dedicated to video polyp segmentation. Extensive experiments on the large-scale SUN-SEG benchmark demonstrate the superior performance of MAST in comparison with the cutting-edge competitors. Our code is publicly available at https://github.com/Junqing-Yang/MAST.
Large Model Based Referring Camouflaged Object Detection
Nov 28, 2023



Referring camouflaged object detection (Ref-COD) is a recently-proposed problem aiming to segment out specified camouflaged objects matched with a textual or visual reference. This task involves two major challenges: the COD domain-specific perception and multimodal reference-image alignment. Our motivation is to make full use of the semantic intelligence and intrinsic knowledge of recent Multimodal Large Language Models (MLLMs) to decompose this complex task in a human-like way. As language is highly condensed and inductive, linguistic expression is the main media of human knowledge learning, and the transmission of knowledge information follows a multi-level progression from simplicity to complexity. In this paper, we propose a large-model-based Multi-Level Knowledge-Guided multimodal method for Ref-COD termed MLKG, where multi-level knowledge descriptions from MLLM are organized to guide the large vision model of segmentation to perceive the camouflage-targets and camouflage-scene progressively and meanwhile deeply align the textual references with camouflaged photos. To our knowledge, our contributions mainly include: (1) This is the first time that the MLLM knowledge is studied for Ref-COD and COD. (2) We, for the first time, propose decomposing Ref-COD into two main perspectives of perceiving the target and scene by integrating MLLM knowledge, and contribute a multi-level knowledge-guided method. (3) Our method achieves the state-of-the-art on the Ref-COD benchmark outperforming numerous strong competitors. Moreover, thanks to the injected rich knowledge, it demonstrates zero-shot generalization ability on uni-modal COD datasets. We will release our code soon.
An objective validation of polyp and instrument segmentation methods in colonoscopy through Medico 2020 polyp segmentation and MedAI 2021 transparency challenges
Jul 30, 2023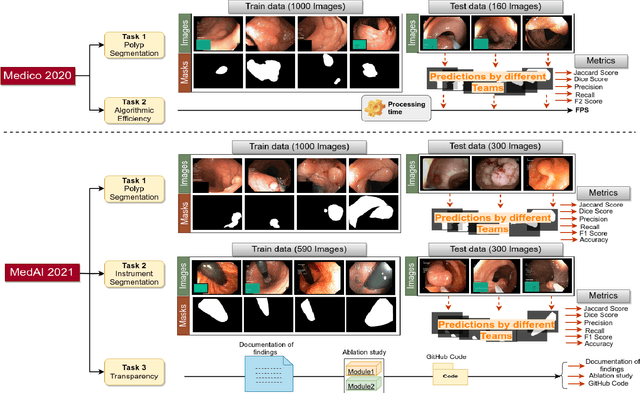
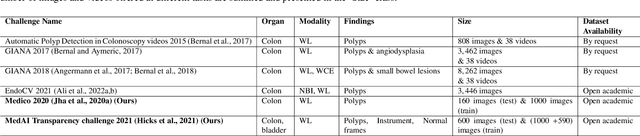
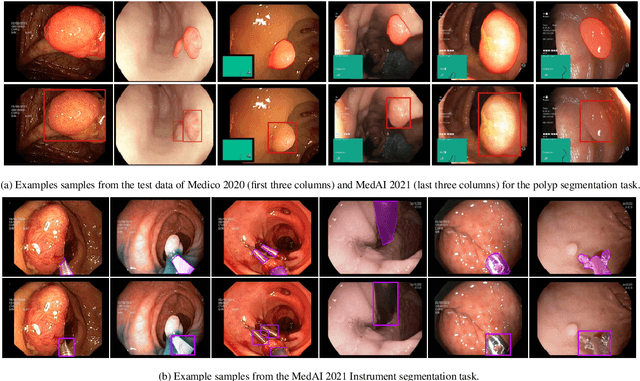
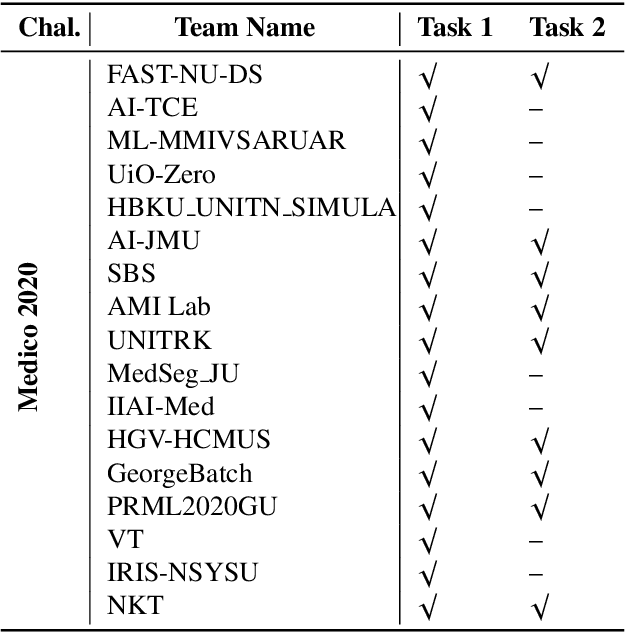
Automatic analysis of colonoscopy images has been an active field of research motivated by the importance of early detection of precancerous polyps. However, detecting polyps during the live examination can be challenging due to various factors such as variation of skills and experience among the endoscopists, lack of attentiveness, and fatigue leading to a high polyp miss-rate. Deep learning has emerged as a promising solution to this challenge as it can assist endoscopists in detecting and classifying overlooked polyps and abnormalities in real time. In addition to the algorithm's accuracy, transparency and interpretability are crucial to explaining the whys and hows of the algorithm's prediction. Further, most algorithms are developed in private data, closed source, or proprietary software, and methods lack reproducibility. Therefore, to promote the development of efficient and transparent methods, we have organized the "Medico automatic polyp segmentation (Medico 2020)" and "MedAI: Transparency in Medical Image Segmentation (MedAI 2021)" competitions. We present a comprehensive summary and analyze each contribution, highlight the strength of the best-performing methods, and discuss the possibility of clinical translations of such methods into the clinic. For the transparency task, a multi-disciplinary team, including expert gastroenterologists, accessed each submission and evaluated the team based on open-source practices, failure case analysis, ablation studies, usability and understandability of evaluations to gain a deeper understanding of the models' credibility for clinical deployment. Through the comprehensive analysis of the challenge, we not only highlight the advancements in polyp and surgical instrument segmentation but also encourage qualitative evaluation for building more transparent and understandable AI-based colonoscopy systems.
How Good is Google Bard's Visual Understanding? An Empirical Study on Open Challenges
Jul 27, 2023Google's Bard has emerged as a formidable competitor to OpenAI's ChatGPT in the field of conversational AI. Notably, Bard has recently been updated to handle visual inputs alongside text prompts during conversations. Given Bard's impressive track record in handling textual inputs, we explore its capabilities in understanding and interpreting visual data (images) conditioned by text questions. This exploration holds the potential to unveil new insights and challenges for Bard and other forthcoming multi-modal Generative models, especially in addressing complex computer vision problems that demand accurate visual and language understanding. Specifically, in this study, we focus on 15 diverse task scenarios encompassing regular, camouflaged, medical, under-water and remote sensing data to comprehensively evaluate Bard's performance. Our primary finding indicates that Bard still struggles in these vision scenarios, highlighting the significant gap in vision-based understanding that needs to be bridged in future developments. We expect that this empirical study will prove valuable in advancing future models, leading to enhanced capabilities in comprehending and interpreting fine-grained visual data. Our project is released on https://github.com/htqin/GoogleBard-VisUnderstand
Rethinking Polyp Segmentation from an Out-of-Distribution Perspective
Jun 13, 2023Unlike existing fully-supervised approaches, we rethink colorectal polyp segmentation from an out-of-distribution perspective with a simple but effective self-supervised learning approach. We leverage the ability of masked autoencoders -- self-supervised vision transformers trained on a reconstruction task -- to learn in-distribution representations; here, the distribution of healthy colon images. We then perform out-of-distribution reconstruction and inference, with feature space standardisation to align the latent distribution of the diverse abnormal samples with the statistics of the healthy samples. We generate per-pixel anomaly scores for each image by calculating the difference between the input and reconstructed images and use this signal for out-of-distribution (ie, polyp) segmentation. Experimental results on six benchmarks show that our model has excellent segmentation performance and generalises across datasets. Our code is publicly available at https://github.com/GewelsJI/Polyp-OOD.