 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAST: Video Polyp Segmentation with a Mixture-Attention Siamese Transformer
Jan 23, 2024Accurate segmentation of polyps from colonoscopy videos is of great significance to polyp treatment and early prevention of colorectal cancer. However, it is challenging due to the difficulties associated with modelling long-range spatio-temporal relationships within a colonoscopy video. In this paper, we address this challenging task with a novel Mixture-Attention Siamese Transformer (MAST), which explicitly models the long-range spatio-temporal relationships with a mixture-attention mechanism for accurate polyp segmentation. Specifically, we first construct a Siamese transformer architecture to jointly encode paired video frames for their feature representations. We then design a mixture-attention module to exploit the intra-frame and inter-frame correlations, enhancing the features with rich spatio-temporal relationships. Finally, the enhanced features are fed to two parallel decoders for predicting the segmentation maps. To the best of our knowledge, our MAST is the first transformer model dedicated to video polyp segmentation. Extensive experiments on the large-scale SUN-SEG benchmark demonstrate the superior performance of MAST in comparison with the cutting-edge competitors. Our code is publicly available at https://github.com/Junqing-Yang/MAST.
DisControlFace: Disentangled Control for Personalized Facial Image Editing
Dec 11, 2023



In this work, we focus on exploring explicit fine-grained control of generative facial image editing, all while generating faithful and consistent personalized facial appearances. We identify the key challenge of this task as the exploration of disentangled conditional control in the generation process, and accordingly propose a novel diffusion-based framework, named DisControlFace, comprising two decoupled components. Specifically, we leverage an off-the-shelf diffusion reconstruction model as the backbone and freeze its pre-trained weights, which helps to reduce identity shift and recover editing-unrelated details of the input image. Furthermore, we construct a parallel control network that is compatible with the reconstruction backbone to generate spatial control conditions based on estimated explicit face parameters. Finally, we further reformulate the training pipeline into a masked-autoencoding form to effectively achieve disentangled training of our DisControlFace. Our DisControlNet can perform robust editing on any facial image through training on large-scale 2D in-the-wild portraits and also supports low-cost fine-tuning with few additional images to further learn diverse personalized priors of a specific person. Extensive experiments demonstrate that DisControlFace can generate realistic facial images corresponding to various face control conditions, while significantly improving the preservation of the personalized facial details.
Think Twice Before Selection: Federated Evidential Active Learning for Medical Image Analysis with Domain Shifts
Dec 05, 2023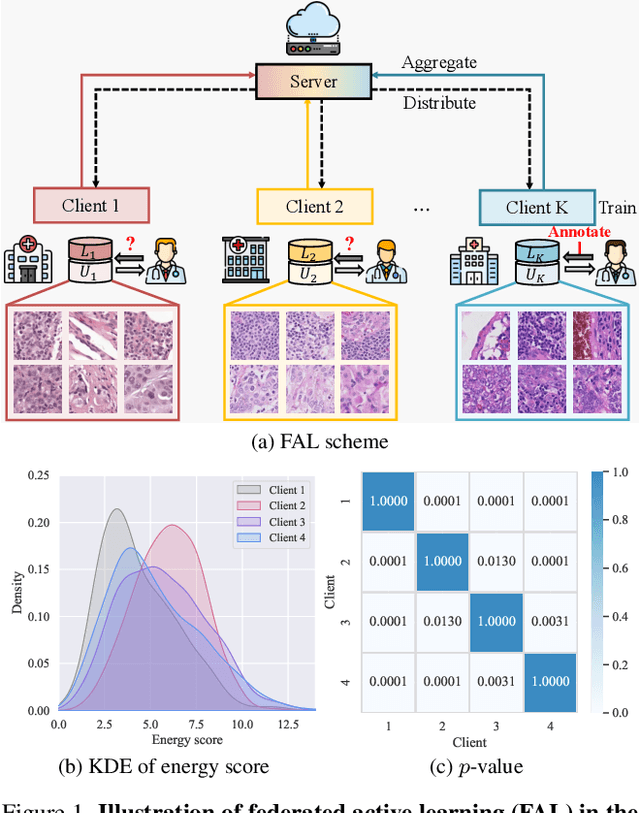
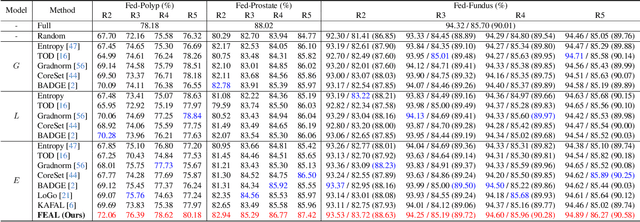
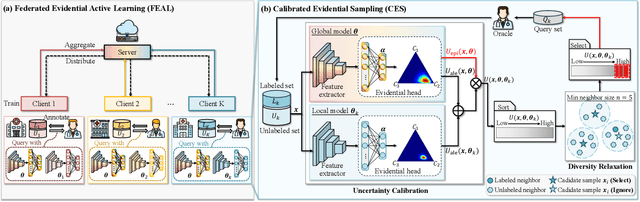
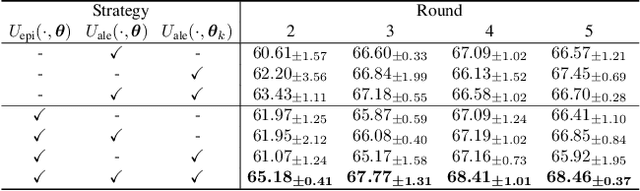
Federated learning facilitates the collaborative learning of a global model across multiple distributed medical institutions without centralizing data. Nevertheless, the expensive cost of annotation on local clients remains an obstacle to effectively utilizing local data. To mitigate this issue, federated active learning methods suggest leveraging local and global model predictions to select a relatively small amount of informative local data for annotation. However, existing methods mainly focus on all local data sampled from the same domain, making them unreliable in realistic medical scenarios with domain shifts among different clients. In this paper, we make the first attempt to assess the informativeness of local data derived from diverse domains and propose a novel methodology termed Federated Evidential Active Learning (FEAL) to calibrate the data evaluation under domain shift. Specifically, we introduce a Dirichlet prior distribution in both local and global models to treat the prediction as a distribution over the probability simplex and capture both aleatoric and epistemic uncertainties by using the Dirichlet-based evidential model. Then we employ the epistemic uncertainty to calibrate the aleatoric uncertainty. Afterward, we design a diversity relaxation strategy to reduce data redundancy and maintain data diversity. Extensive experiments and analyses are conducted to show the superiority of FEAL over the state-of-the-art active learning methods and the efficiency of FEAL under the federated active learning framework.
Treasure in Distribution: A Domain Randomization based Multi-Source Domain Generalization for 2D Medical Image Segmentation
May 31, 2023Although recent years have witnessed the great success of convolutional neural networks (CNNs) in medical image segmentation, the domain shift issue caused by the highly variable image quality of medical images hinders the deployment of CNNs in real-world clinical applications. Domain generalization (DG) methods aim to address this issue by training a robust model on the source domain, which has a strong generalization ability. Previously, many DG methods based on feature-space domain randomization have been proposed, which, however, suffer from the limited and unordered search space of feature styles. In this paper, we propose a multi-source DG method called Treasure in Distribution (TriD), which constructs an unprecedented search space to obtain the model with strong robustness by randomly sampling from a uniform distribution. To learn the domain-invariant representations explicitly, we further devise a style-mixing strategy in our TriD, which mixes the feature styles by randomly mixing the augmented and original statistics along the channel wise and can be extended to other DG methods. Extensive experiments on two medical segmentation tasks with different modalities demonstrate that our TriD achieves superior generalization performance on unseen target-domain data. Code is available at https://github.com/Chen-Ziyang/TriD.