 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoExpert: Augmented LLM for Temporal-Sensitive Video Understanding
Paper and Code
Apr 10, 2025
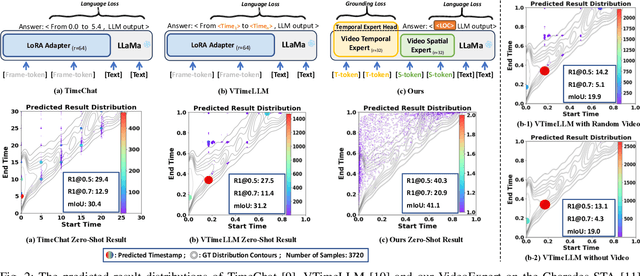
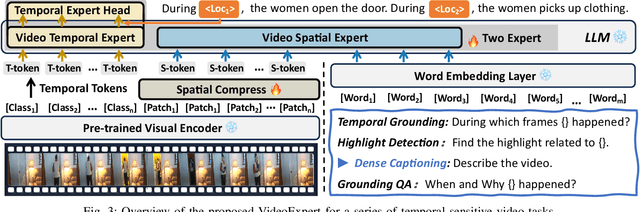
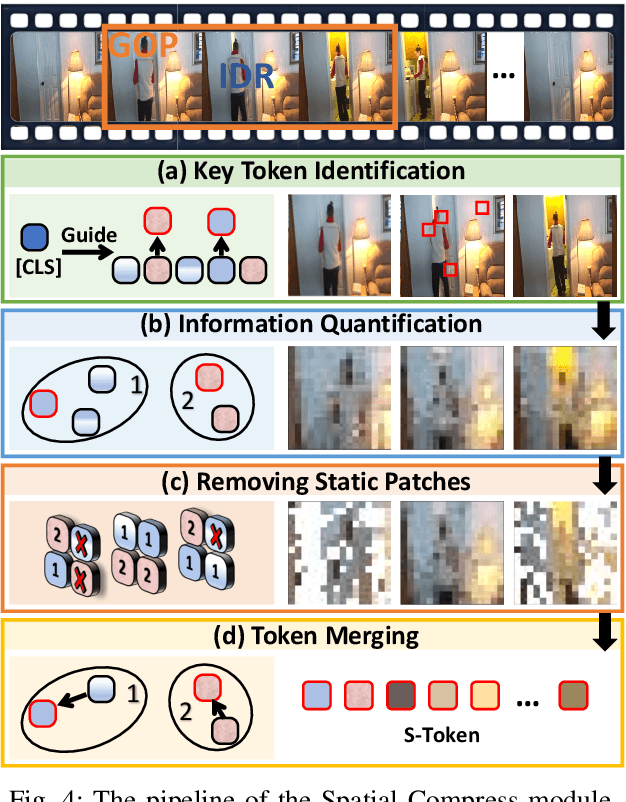
The core challenge in video understanding lies in perceiving dynamic content changes over time. However, multimodal large language models struggle with temporal-sensitive video tasks, which requires generating timestamps to mark the occurrence of specific events. Existing strategies require MLLMs to generate absolute or relative timestamps directly. We have observed that those MLLMs tend to rely more on language patterns than visual cues when generating timestamps, affecting their performance. To address this problem, we propose VideoExpert, a general-purpose MLLM suitable for several temporal-sensitive video tasks. Inspired by the expert concept, VideoExpert integrates two parallel modules: the Temporal Expert and the Spatial Expert. The Temporal Expert is responsible for modeling time sequences and performing temporal grounding. It processes high-frame-rate yet compressed tokens to capture dynamic variations in videos and includes a lightweight prediction head for precise event localization. The Spatial Expert focuses on content detail analysis and instruction following. It handles specially designed spatial tokens and language input, aiming to generate content-related responses. These two experts collaborate seamlessly via a special token, ensuring coordinated temporal grounding and content generation. Notably, the Temporal and Spatial Experts maintain independent parameter sets. By offloading temporal grounding from content generation, VideoExpert prevents text pattern biases in timestamp predictions. Moreover, we introduce a Spatial Compress module to obtain spatial tokens. This module filters and compresses patch tokens while preserving key information, delivering compact yet detail-rich input for the Spatial Expert. Extensive experiments demonstrate the effectiveness and versatility of the VideoExpert.