 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurface Geometry Processing: An Efficient Normal-based Detail Representation
Jul 16, 2023



With the rapid development of high-resolution 3D vision applications, the traditional way of manipulating surface detail requires considerable memory and computing time. To address these problems, we introduce an efficient surface detail processing framework in 2D normal domain, which extracts new normal feature representations as the carrier of micro geometry structures that are illustrated both theoretically and empirically in this article. Compared with the existing state of the arts, we verify and demonstrate that the proposed normal-based representation has three important properties, including detail separability, detail transferability and detail idempotence. Finally, three new schemes are further designed for geometric surface detail processing applications, including geometric texture synthesis, geometry detail transfer, and 3D surface super-resolution. Theoretical analysis and experimental results on the latest benchmark dataset verify the effectiveness and versatility of our normal-based representation, which accepts 30 times of the input surface vertices but at the same time only takes 6.5% memory cost and 14.0% running time in comparison with existing competing algorithms.
* 16 pages, 22 figures
A Lightweight Recurrent Learning Network for Sustainable Compressed Sensing
Apr 23, 2023



Recently, deep learning-based compressed sensing (CS) has achieved great success in reducing the sampling and computational cost of sensing systems and improving the reconstruction quality. These approaches, however, largely overlook the issue of the computational cost; they rely on complex structures and task-specific operator designs, resulting in extensive storage and high energy consumption in CS imaging systems. In this paper, we propose a lightweight but effective deep neural network based on recurrent learning to achieve a sustainable CS system; it requires a smaller number of parameters but obtains high-quality reconstructions. Specifically, our proposed network consists of an initial reconstruction sub-network and a residual reconstruction sub-network. While the initial reconstruction sub-network has a hierarchical structure to progressively recover the image, reducing the number of parameters, the residual reconstruction sub-network facilitates recurrent residual feature extraction via recurrent learning to perform both feature fusion and deep reconstructions across different scales. In addition, we also demonstrate that, after the initial reconstruction, feature maps with reduced sizes are sufficient to recover the residual information, and thus we achieved a significant reduction in the amount of memory required. Extensive experiments illustrate that our proposed model can achieve a better reconstruction quality than existing state-of-the-art CS algorithms, and it also has a smaller number of network parameters than these algorithms. Our source codes are available at: https://github.com/C66YU/CSRN.
SA-Net: A deep spectral analysis network for image clustering
Sep 11, 2020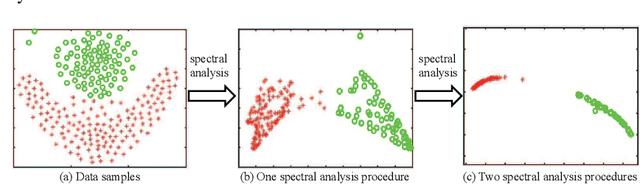
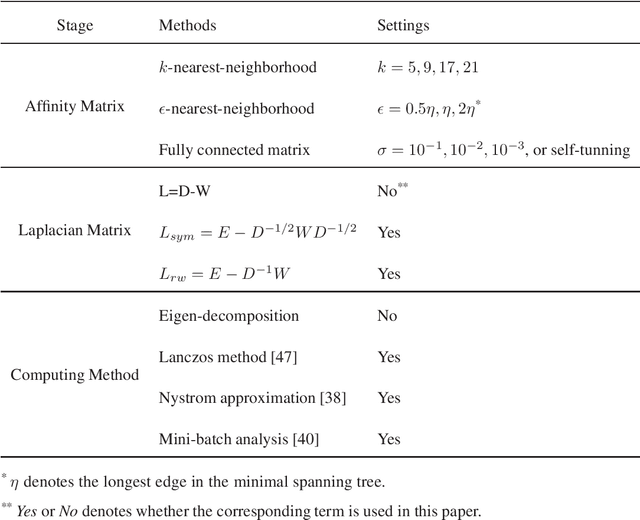
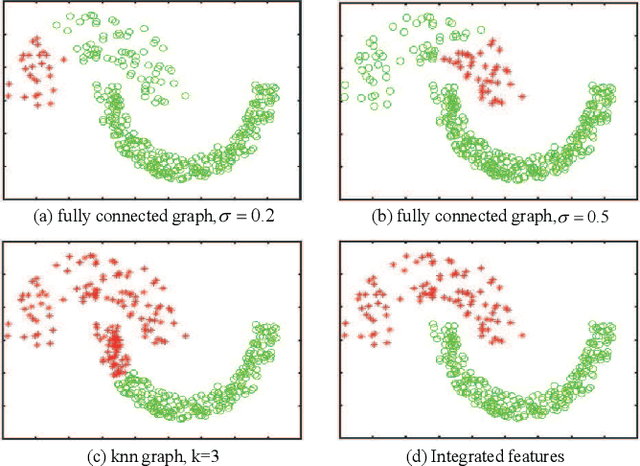
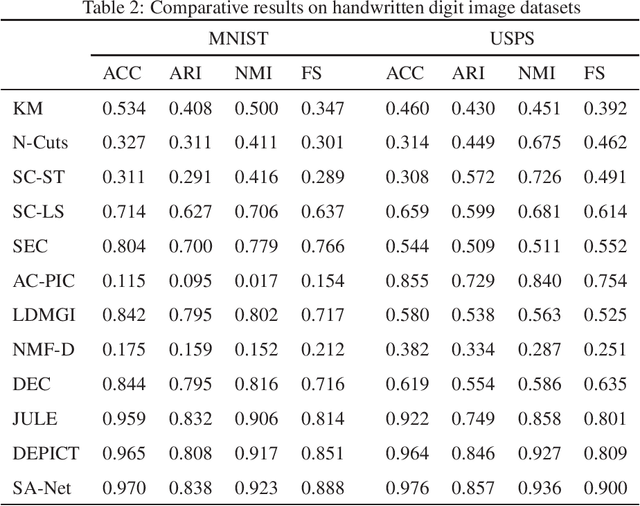
Although supervised deep representation learning has attracted enormous attentions across areas of pattern recognition and computer vision, little progress has been made towards unsupervised deep representation learning for image clustering. In this paper, we propose a deep spectral analysis network for unsupervised representation learning and image clustering. While spectral analysis is established with solid theoretical foundations and has been widely applied to unsupervised data mining, its essential weakness lies in the fact that it is difficult to construct a proper affinity matrix and determine the involving Laplacian matrix for a given dataset. In this paper, we propose a SA-Net to overcome these weaknesses and achieve improved image clustering by extending the spectral analysis procedure into a deep learning framework with multiple layers. The SA-Net has the capability to learn deep representations and reveal deep correlations among data samples. Compared with the existing spectral analysis, the SA-Net achieves two advantages: (i) Given the fact that one spectral analysis procedure can only deal with one subset of the given dataset, our proposed SA-Net elegantly integrates multiple parallel and consecutive spectral analysis procedures together to enable interactive learning across different units towards a coordinated clustering model; (ii) Our SA-Net can identify the local similarities among different images at patch level and hence achieves a higher level of robustness against occlusions. Extensive experiments on a number of popular datasets support that our proposed SA-Net outperforms 11 benchmarks across a number of image clustering applications.
* arXiv admin note: text overlap with arXiv:2009.05235
Spectral Analysis Network for Deep Representation Learning and Image Clustering
Sep 11, 2020


Deep representation learning is a crucial procedure in multimedia analysis and attracts increasing attention. Most of the popular techniques rely on convolutional neural network and require a large amount of labeled data in the training procedure. However, it is time consuming or even impossible to obtain the label information in some tasks due to cost limitation. Thus, it is necessary to develop unsupervised deep representation learning techniques. This paper proposes a new network structure for unsupervised deep representation learning based on spectral analysis, which is a popular technique with solid theory foundations. Compared with the existing spectral analysis methods, the proposed network structure has at least three advantages. Firstly, it can identify the local similarities among images in patch level and thus more robust against occlusion. Secondly, through multiple consecutive spectral analysis procedures, the proposed network can learn more clustering-friendly representations and is capable to reveal the deep correlations among data samples. Thirdly, it can elegantly integrate different spectral analysis procedures, so that each spectral analysis procedure can have their individual strengths in dealing with different data sample distributions. Extensive experimental results show the effectiveness of the proposed methods on various image clustering tasks.
An unsupervised deep learning framework via integrated optimization of representation learning and GMM-based modeling
Sep 11, 2020
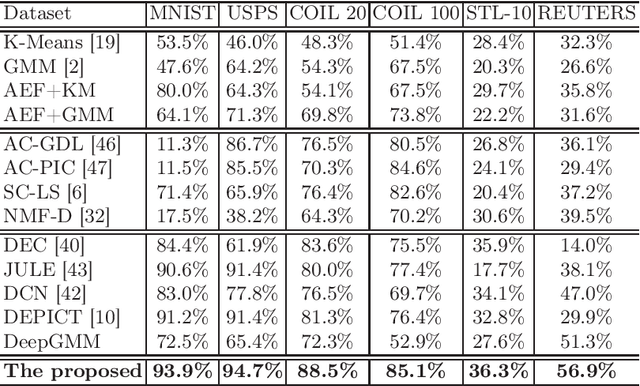


While supervised deep learning has achieved great success in a range of applications, relatively little work has studied the discovery of knowledge from unlabeled data. In this paper, we propose an unsupervised deep learning framework to provide a potential solution for the problem that existing deep learning techniques require large labeled data sets for completing the training process. Our proposed introduces a new principle of joint learning on both deep representations and GMM (Gaussian Mixture Model)-based deep modeling, and thus an integrated objective function is proposed to facilitate the principle. In comparison with the existing work in similar areas, our objective function has two learning targets, which are created to be jointly optimized to achieve the best possible unsupervised learning and knowledge discovery from unlabeled data sets. While maximizing the first target enables the GMM to achieve the best possible modeling of the data representations and each Gaussian component corresponds to a compact cluster, maximizing the second term will enhance the separability of the Gaussian components and hence the inter-cluster distances. As a result, the compactness of clusters is significantly enhanced by reducing the intra-cluster distances, and the separability is improved by increasing the inter-cluster distances. Extensive experimental results show that the propose method can improve the clustering performance compared with benchmark methods.
Conditional Coupled Generative Adversarial Networks for Zero-Shot Domain Adaptation
Sep 11, 2020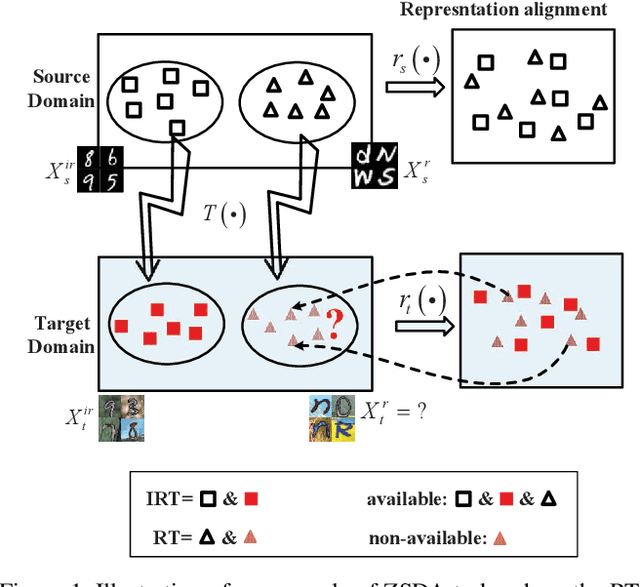

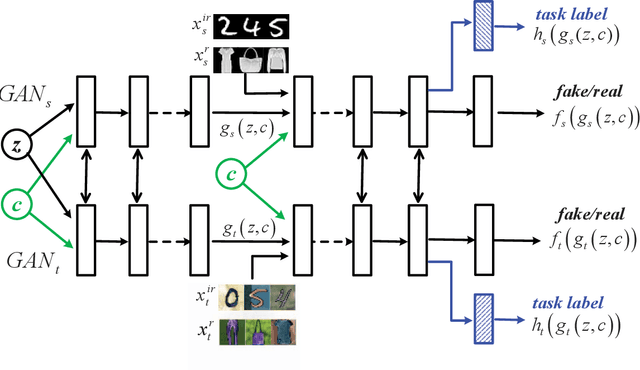

Machine learning models trained in one domain perform poorly in the other domains due to the existence of domain shift. Domain adaptation techniques solve this problem by training transferable models from the label-rich source domain to the label-scarce target domain. Unfortunately, a majority of the existing domain adaptation techniques rely on the availability of target-domain data, and thus limit their applications to a small community across few computer vision problems. In this paper, we tackle the challenging zero-shot domain adaptation (ZSDA) problem, where target-domain data is non-available in the training stage. For this purpose, we propose conditional coupled generative adversarial networks (CoCoGAN) by extending the coupled generative adversarial networks (CoGAN) into a conditioning model. Compared with the existing state of the arts, our proposed CoCoGAN is able to capture the joint distribution of dual-domain samples in two different tasks, i.e. the relevant task (RT) and an irrelevant task (IRT). We train CoCoGAN with both source-domain samples in RT and dual-domain samples in IRT to complete the domain adaptation. While the former provide high-level concepts of the non-available target-domain data, the latter carry the sharing correlation between the two domains in RT and IRT. To train CoCoGAN in the absence of target-domain data for RT, we propose a new supervisory signal, i.e. the alignment between representations across tasks. Extensive experiments carried out demonstrate that our proposed CoCoGAN outperforms existing state of the arts in image classifications.
Adversarial Learning for Zero-shot Domain Adaptation
Sep 11, 2020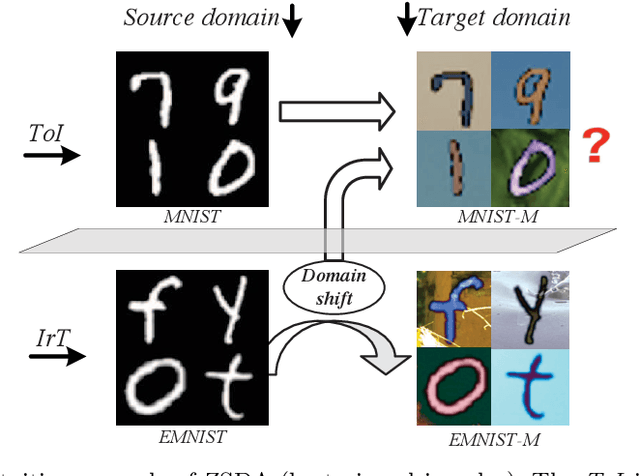
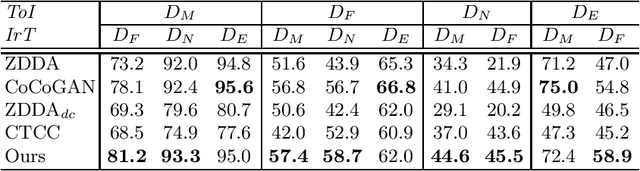
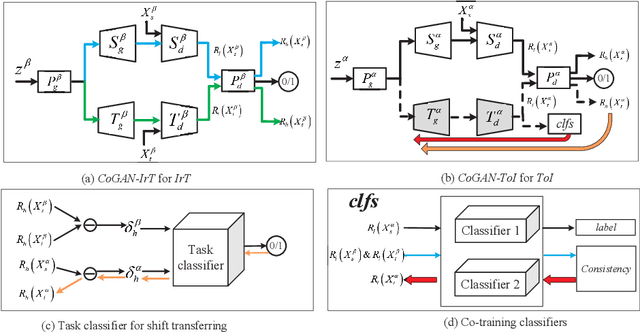

Zero-shot domain adaptation (ZSDA) is a category of domain adaptation problems where neither data sample nor label is available for parameter learning in the target domain. With the hypothesis that the shift between a given pair of domains is shared across tasks, we propose a new method for ZSDA by transferring domain shift from an irrelevant task (IrT) to the task of interest (ToI). Specifically, we first identify an IrT, where dual-domain samples are available, and capture the domain shift with a coupled generative adversarial networks (CoGAN) in this task. Then, we train a CoGAN for the ToI and restrict it to carry the same domain shift as the CoGAN for IrT does. In addition, we introduce a pair of co-training classifiers to regularize the training procedure of CoGAN in the ToI. The proposed method not only derives machine learning models for the non-available target-domain data, but also synthesizes the data themselves. We evaluate the proposed method on benchmark datasets and achieve the state-of-the-art performances.
A Simple Pooling-Based Design for Real-Time Salient Object Detection
Apr 21, 2019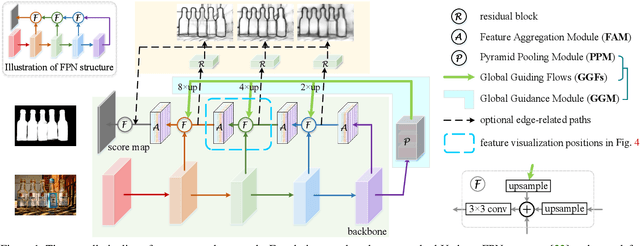
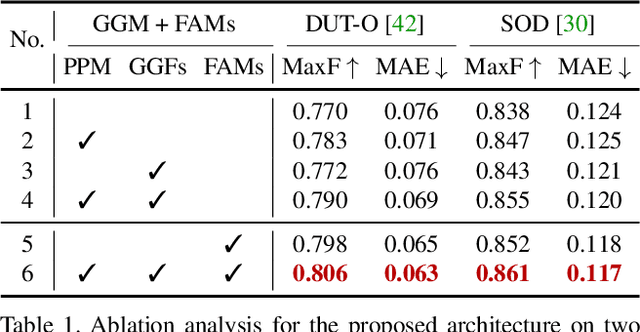

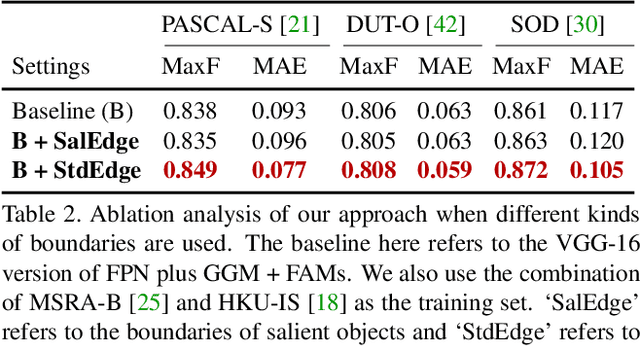
We solve the problem of salient object detection by investigating how to expand the role of pooling in convolutional neural networks. Based on the U-shape architecture, we first build a global guidance module (GGM) upon the bottom-up pathway, aiming at providing layers at different feature levels the location information of potential salient objects. We further design a feature aggregation module (FAM) to make the coarse-level semantic information well fused with the fine-level features from the top-down pathway. By adding FAMs after the fusion operations in the top-down pathway, coarse-level features from the GGM can be seamlessly merged with features at various scales. These two pooling-based modules allow the high-level semantic features to be progressively refined, yielding detail enriched saliency maps. Experiment results show that our proposed approach can more accurately locate the salient objects with sharpened details and hence substantially improve the performance compared to the previous state-of-the-arts. Our approach is fast as well and can run at a speed of more than 30 FPS when processing a $300 \times 400$ image. Code can be found at http://mmcheng.net/poolnet/.
GeoCapsNet: Aerial to Ground view Image Geo-localization using Capsule Network
Apr 12, 2019

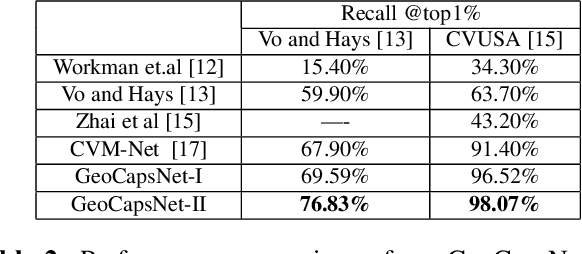
The task of cross-view image geo-localization aims to determine the geo-location (GPS coordinates) of a query ground-view image by matching it with the GPS-tagged aerial (satellite) images in a reference dataset. Due to the dramatic changes of viewpoint, matching the cross-view images is challenging. In this paper, we propose the GeoCapsNet based on the capsule network for ground-to-aerial image geo-localization. The network first extracts features from both ground-view and aerial images via standard convolution layers and the capsule layers further encode the features to model the spatial feature hierarchies and enhance the representation power. Moreover, we introduce a simple and effective weighted soft-margin triplet loss with online batch hard sample mining, which can greatly improve image retrieval accuracy. Experimental results show that our GeoCapsNet significantly outperforms the state-of-the-art approaches on two benchmark datasets.
SG-FCN: A Motion and Memory-Based Deep Learning Model for Video Saliency Detection
Sep 21, 2018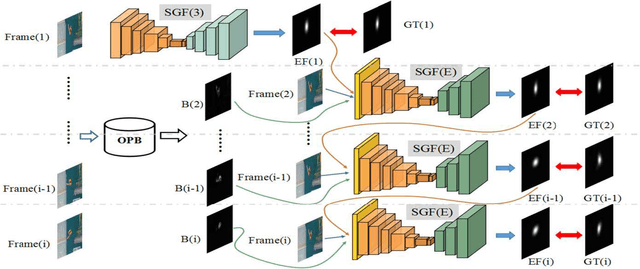
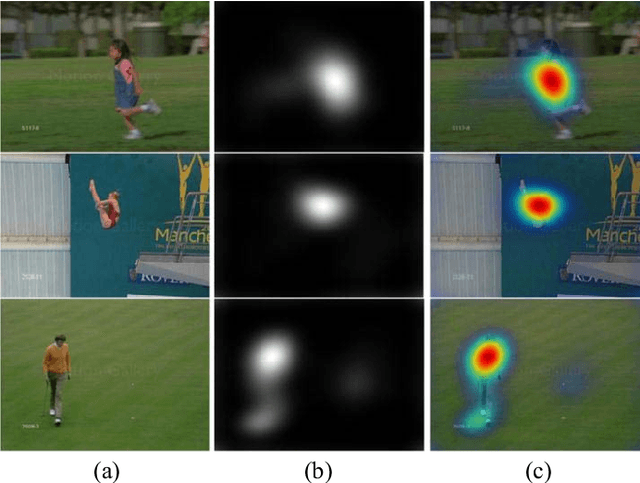
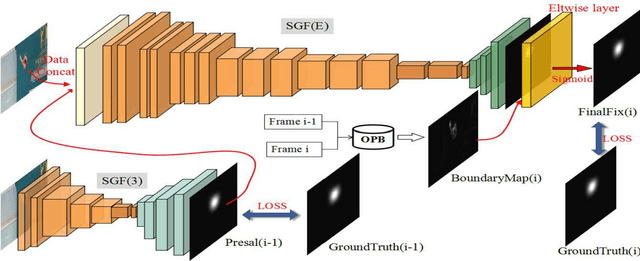
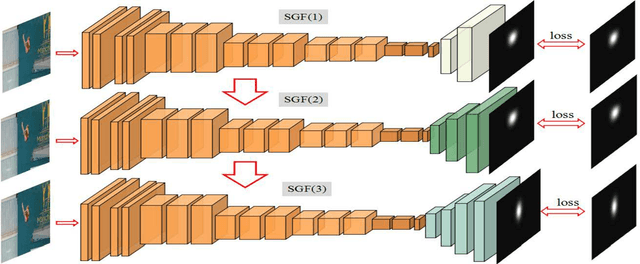
Data-driven saliency detection has attracted strong interest as a result of applying convolutional neural networks to the detection of eye fixations. Although a number of imagebased salient object and fixation detection models have been proposed, video fixation detection still requires more exploration. Different from image analysis, motion and temporal information is a crucial factor affecting human attention when viewing video sequences. Although existing models based on local contrast and low-level features have been extensively researched, they failed to simultaneously consider interframe motion and temporal information across neighboring video frames, leading to unsatisfactory performance when handling complex scenes. To this end, we propose a novel and efficient video eye fixation detection model to improve the saliency detection performance. By simulating the memory mechanism and visual attention mechanism of human beings when watching a video, we propose a step-gained fully convolutional network by combining the memory information on the time axis with the motion information on the space axis while storing the saliency information of the current frame. The model is obtained through hierarchical training, which ensures the accuracy of the detection. Extensive experiments in comparison with 11 state-of-the-art methods are carried out, and the results show that our proposed model outperforms all 11 methods across a number of publicly available datasets.