 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText Classification based on Multi-granularity Attention Hybrid Neural Network
Aug 12, 2020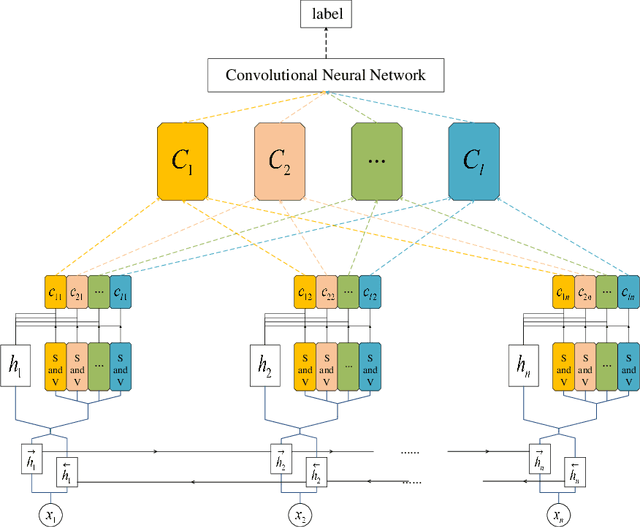

Neural network-based approaches have become the driven forces for Natural Language Processing (NLP) tasks. Conventionally, there are two mainstream neural architectures for NLP tasks: the recurrent neural network (RNN) and the convolution neural network (ConvNet). RNNs are good at modeling long-term dependencies over input texts, but preclude parallel computation. ConvNets do not have memory capability and it has to model sequential data as un-ordered features. Therefore, ConvNets fail to learn sequential dependencies over the input texts, but it is able to carry out high-efficient parallel computation. As each neural architecture, such as RNN and ConvNets, has its own pro and con, integration of different architectures is assumed to be able to enrich the semantic representation of texts, thus enhance the performance of NLP tasks. However, few investigation explores the reconciliation of these seemingly incompatible architectures. To address this issue, we propose a hybrid architecture based on a novel hierarchical multi-granularity attention mechanism, named Multi-granularity Attention-based Hybrid Neural Network (MahNN). The attention mechanism is to assign different weights to different parts of the input sequence to increase the computation efficiency and performance of neural models. In MahNN, two types of attentions are introduced: the syntactical attention and the semantical attention. The syntactical attention computes the importance of the syntactic elements (such as words or sentence) at the lower symbolic level and the semantical attention is used to compute the importance of the embedded space dimension corresponding to the upper latent semantics. We adopt the text classification as an exemplifying way to illustrate the ability of MahNN to understand texts.
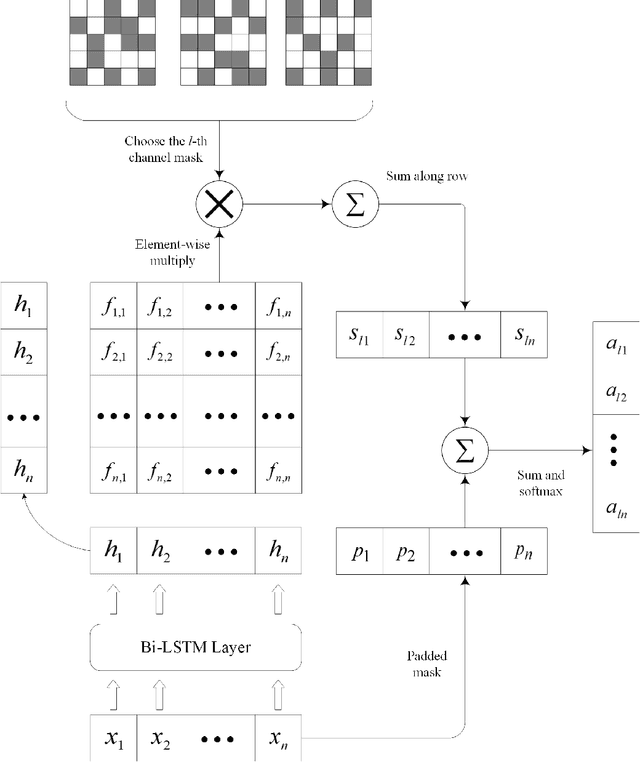
Multichannel CNN with Attention for Text Classification
Jun 29, 2020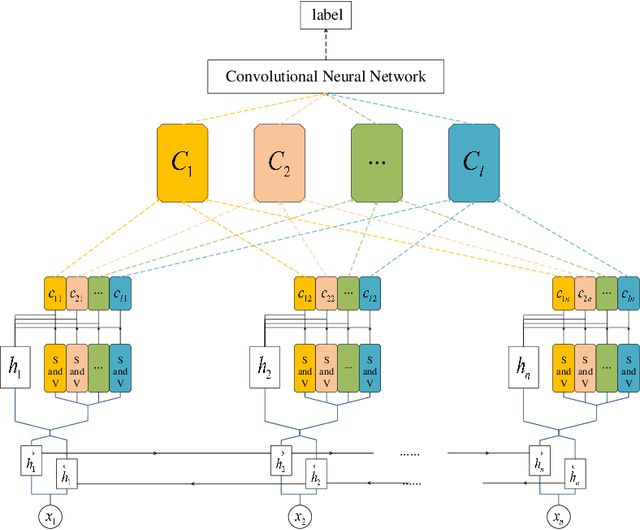
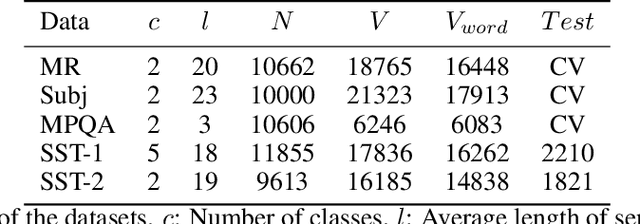
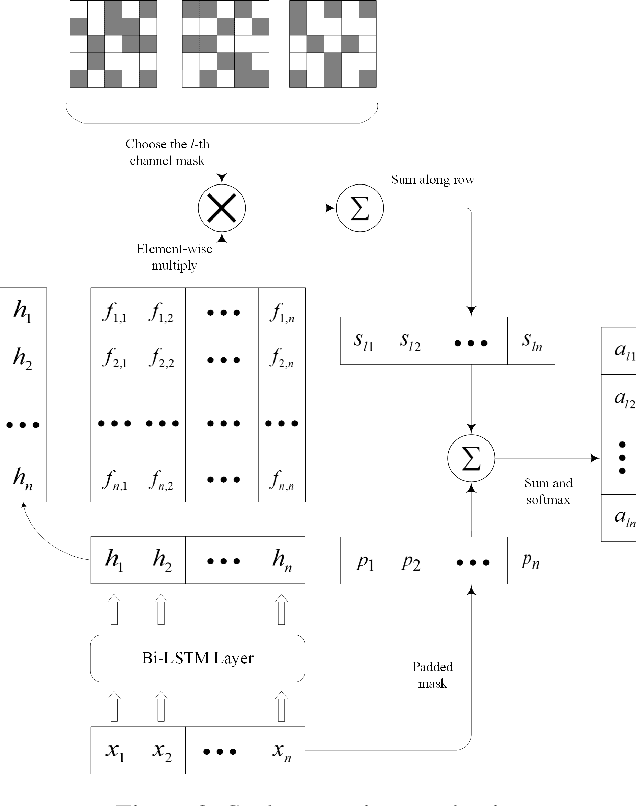
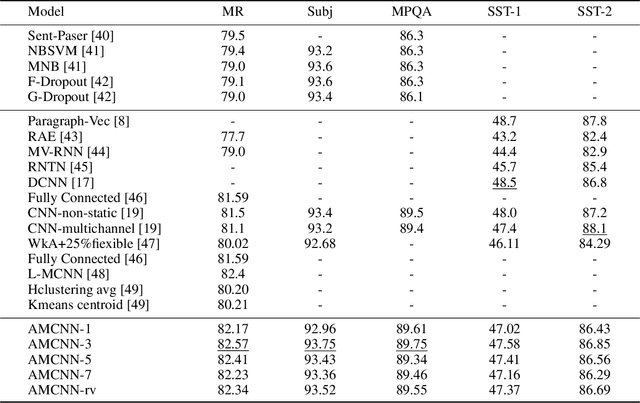
Recent years, the approaches based on neural networks have shown remarkable potential for sentence modeling. There are two main neural network structures: recurrent neural network (RNN) and convolution neural network (CNN). RNN can capture long term dependencies and store the semantics of the previous information in a fixed-sized vector. However, RNN is a biased model and its ability to extract global semantics is restricted by the fixed-sized vector. Alternatively, CNN is able to capture n-gram features of texts by utilizing convolutional filters. But the width of convolutional filters restricts its performance. In order to combine the strengths of the two kinds of networks and alleviate their shortcomings, this paper proposes Attention-based Multichannel Convolutional Neural Network (AMCNN) for text classification. AMCNN utilizes a bi-directional long short-term memory to encode the history and future information of words into high dimensional representations, so that the information of both the front and back of the sentence can be fully expressed. Then the scalar attention and vectorial attention are applied to obtain multichannel representations. The scalar attention can calculate the word-level importance and the vectorial attention can calculate the feature-level importance. In the classification task, AMCNN uses a CNN structure to cpture word relations on the representations generated by the scalar and vectorial attention mechanism instead of calculating the weighted sums. It can effectively extract the n-gram features of the text. The experimental results on the benchmark datasets demonstrate that AMCNN achieves better performance than state-of-the-art methods. In addition, the visualization results verify the semantic richness of multichannel representations.