 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating the Direction and Radius of Pipe from GPR Image by Ellipse Inversion Model
Jan 25, 2022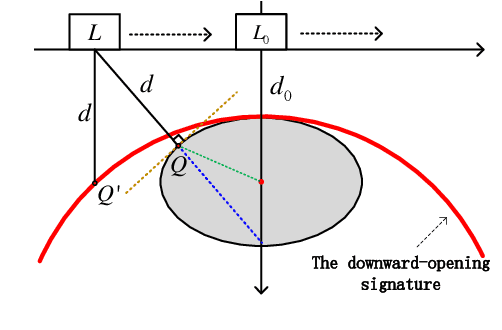
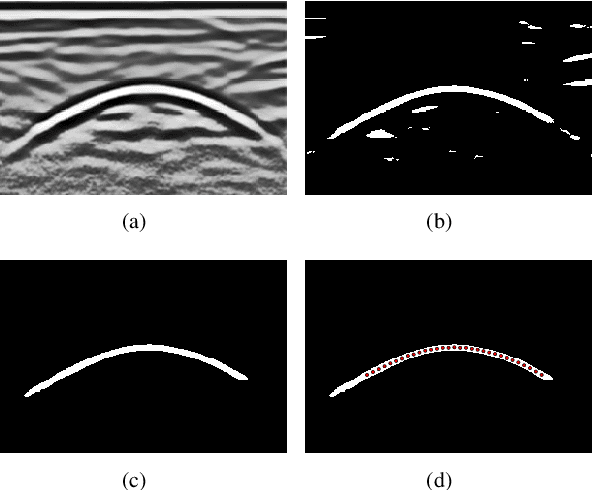
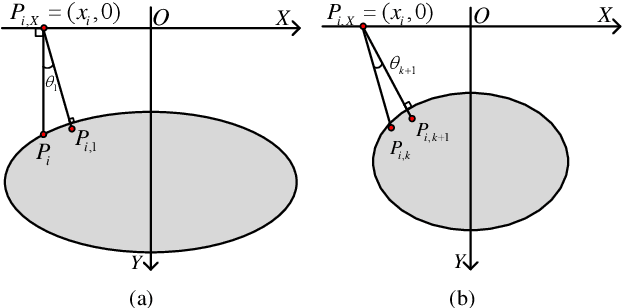
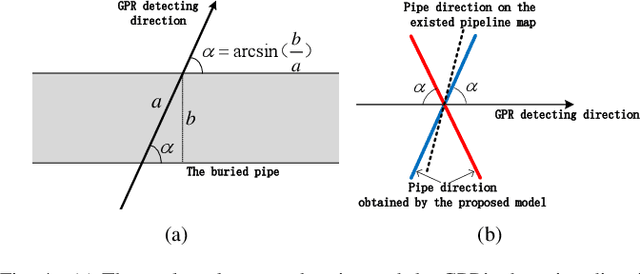
Ground Penetrating Radar (GPR) is widely used as a non-destructive approach to estimate buried utilities. When the GPR's detecting direction is perpendicular to a pipeline, a hyperbolic characteristic would be formed on the GPR B-scan image. However, in real-world applications, the direction of pipelines on the existing pipeline map could be inaccurate, and it is hard to ensure the moving direction of GPR to be actually perpendicular to underground pipelines. In this paper, a novel model is proposed to estimate the direction and radius of pipeline and revise the existing pipeline map from GPR B-scan images. The model consists of two parts: GPR B-scan image processing and Ellipse Iterative Inversion Algorithm (EIIA). Firstly, the GPR B-scan image is processed with downward-opening point set extracted. The obtained point set is then iteratively inverted to the elliptical cross section of the buried pipeline, which is caused by the angle between the GPR's detecting direction and the pipeline's direction. By minimizing the sum of the algebraic distances from the extracted point set to the inverted ellipse, the most likely pipeline's direction and radius are determined. Experiments on real-world datasets are conducted, and the results demonstrate the effectiveness of the method.
Mapping the Buried Cable by Ground Penetrating Radar and Gaussian-Process Regression
Jan 25, 2022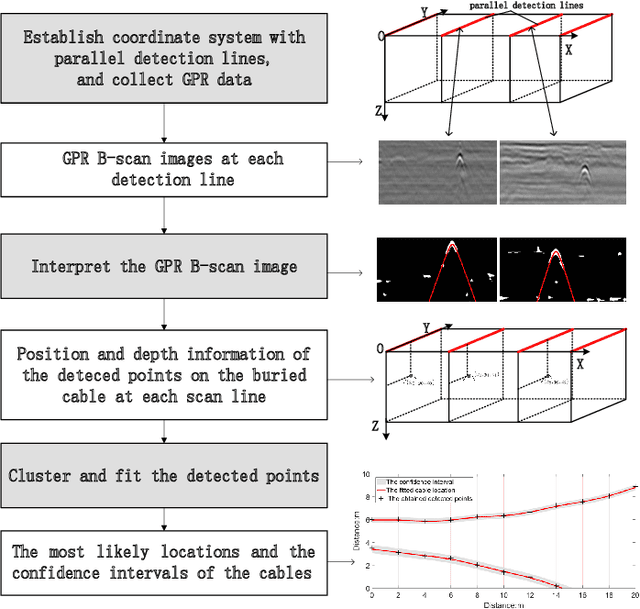
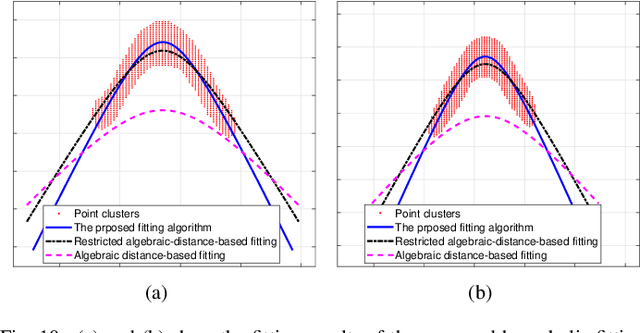
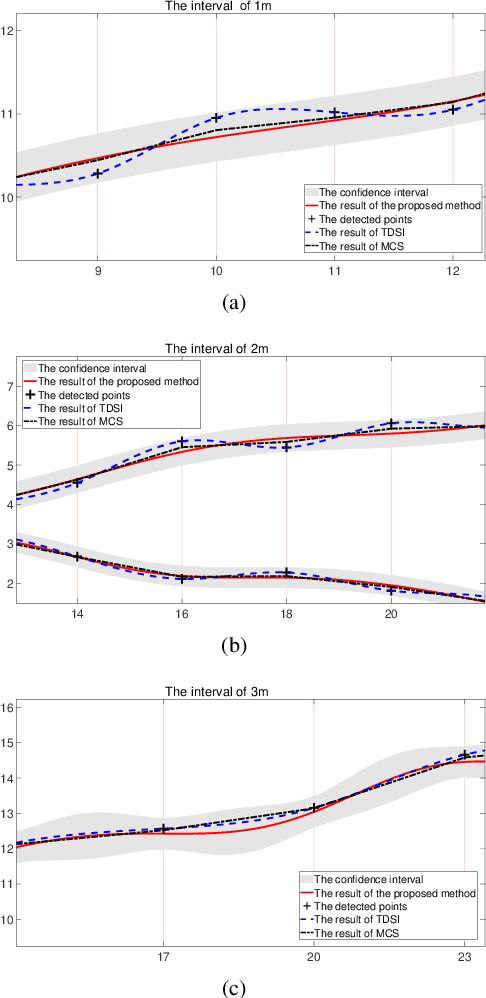
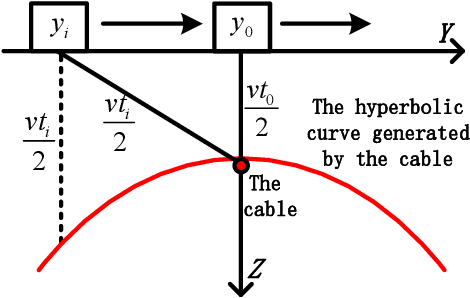
With the rapid expansion of urban areas and the increasingly use of electricity, the need for locating buried cables is becoming urgent. In this paper, a noval method to locate underground cables based on Ground Penetrating Radar (GPR) and Gaussian-process regression is proposed. Firstly, the coordinate system of the detected area is conducted, and the input and output of locating buried cables are determined. The GPR is moved along the established parallel detection lines, and the hyperbolic signatures generated by buried cables are identified and fitted, thus the positions and depths of some points on the cable could be derived. On the basis of the established coordinate system and the derived points on the cable, the clustering method and cable fitting algorithm based on Gaussian-process regression are proposed to find the most likely locations of the underground cables. Furthermore, the confidence intervals of the cable's locations are also obtained. Both the position and depth noises are taken into account in our method, ensuring the robustness and feasibility in different environments and equipments. Experiments on real-world datasets are conducted, and the obtained results demonstrate the effectiveness of the proposed method.
Do Models Learn the Directionality of Relations? A New Evaluation Task: Relation Direction Recognition
May 19, 2021

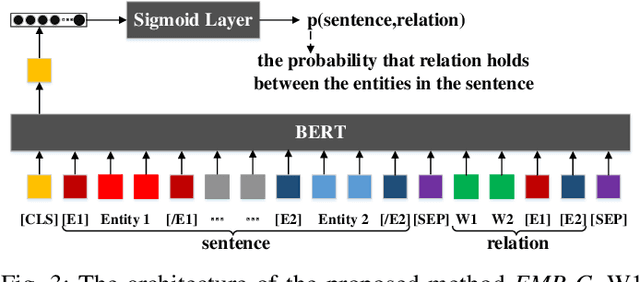
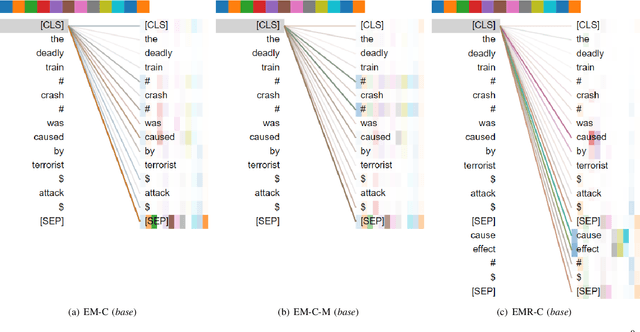
Deep neural networks such as BERT have made great progress in relation classification. Although they can achieve good performance, it is still a question of concern whether these models recognize the directionality of relations, especially when they may lack interpretability. To explore the question, a novel evaluation task, called Relation Direction Recognition (RDR), is proposed to explore whether models learn the directionality of relations. Three metrics for RDR are introduced to measure the degree to which models recognize the directionality of relations. Several state-of-the-art models are evaluated on RDR. Experimental results on a real-world dataset indicate that there are clear gaps among them in recognizing the directionality of relations, even though these models obtain similar performance in the traditional metric (e.g. Macro-F1). Finally, some suggestions are discussed to enhance models to recognize the directionality of relations from the perspective of model design or training.
Relation Classification with Entity Type Restriction
May 18, 2021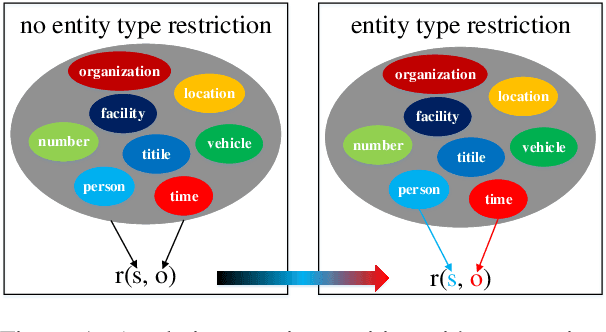
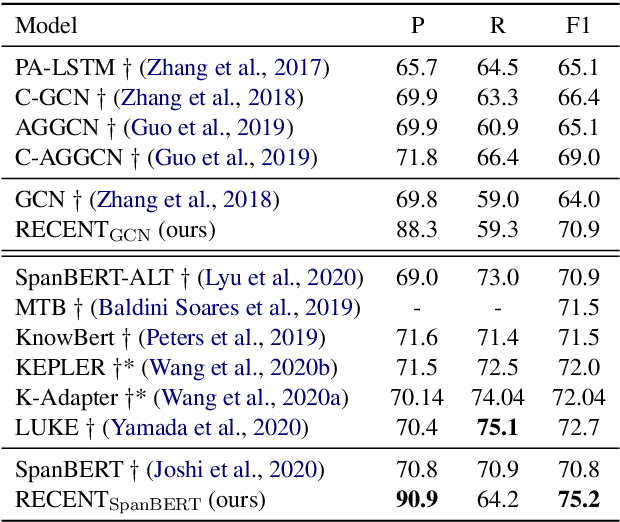
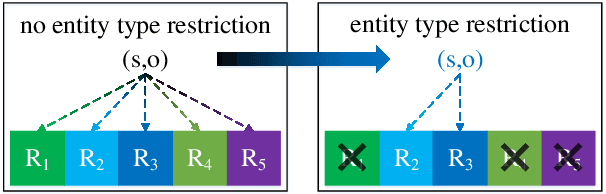

Relation classification aims to predict a relation between two entities in a sentence. The existing methods regard all relations as the candidate relations for the two entities in a sentence. These methods neglect the restrictions on candidate relations by entity types, which leads to some inappropriate relations being candidate relations. In this paper, we propose a novel paradigm, RElation Classification with ENtity Type restriction (RECENT), which exploits entity types to restrict candidate relations. Specially, the mutual restrictions of relations and entity types are formalized and introduced into relation classification. Besides, the proposed paradigm, RECENT, is model-agnostic. Based on two representative models GCN and SpanBERT respectively, RECENT_GCN and RECENT_SpanBERT are trained in RECENT. Experimental results on a standard dataset indicate that RECENT improves the performance of GCN and SpanBERT by 6.9 and 4.4 F1 points, respectively. Especially, RECENT_SpanBERT achieves a new state-of-the-art on TACRED.
Text Classification based on Multi-granularity Attention Hybrid Neural Network
Aug 12, 2020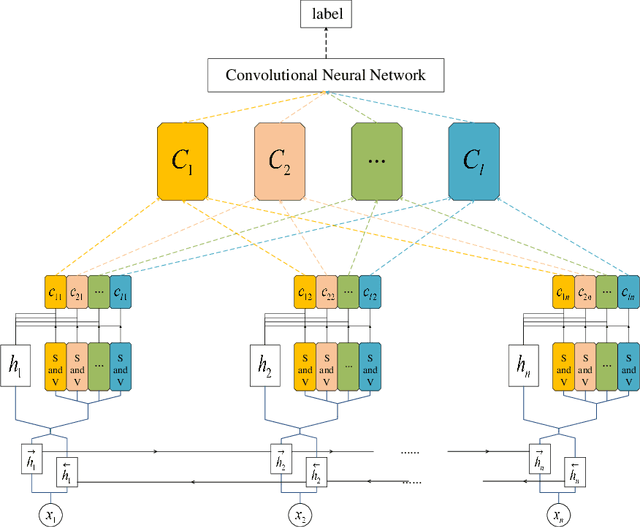
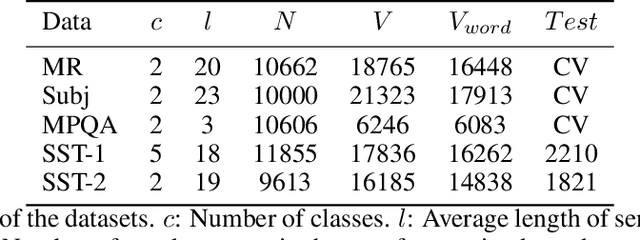

Neural network-based approaches have become the driven forces for Natural Language Processing (NLP) tasks. Conventionally, there are two mainstream neural architectures for NLP tasks: the recurrent neural network (RNN) and the convolution neural network (ConvNet). RNNs are good at modeling long-term dependencies over input texts, but preclude parallel computation. ConvNets do not have memory capability and it has to model sequential data as un-ordered features. Therefore, ConvNets fail to learn sequential dependencies over the input texts, but it is able to carry out high-efficient parallel computation. As each neural architecture, such as RNN and ConvNets, has its own pro and con, integration of different architectures is assumed to be able to enrich the semantic representation of texts, thus enhance the performance of NLP tasks. However, few investigation explores the reconciliation of these seemingly incompatible architectures. To address this issue, we propose a hybrid architecture based on a novel hierarchical multi-granularity attention mechanism, named Multi-granularity Attention-based Hybrid Neural Network (MahNN). The attention mechanism is to assign different weights to different parts of the input sequence to increase the computation efficiency and performance of neural models. In MahNN, two types of attentions are introduced: the syntactical attention and the semantical attention. The syntactical attention computes the importance of the syntactic elements (such as words or sentence) at the lower symbolic level and the semantical attention is used to compute the importance of the embedded space dimension corresponding to the upper latent semantics. We adopt the text classification as an exemplifying way to illustrate the ability of MahNN to understand texts.
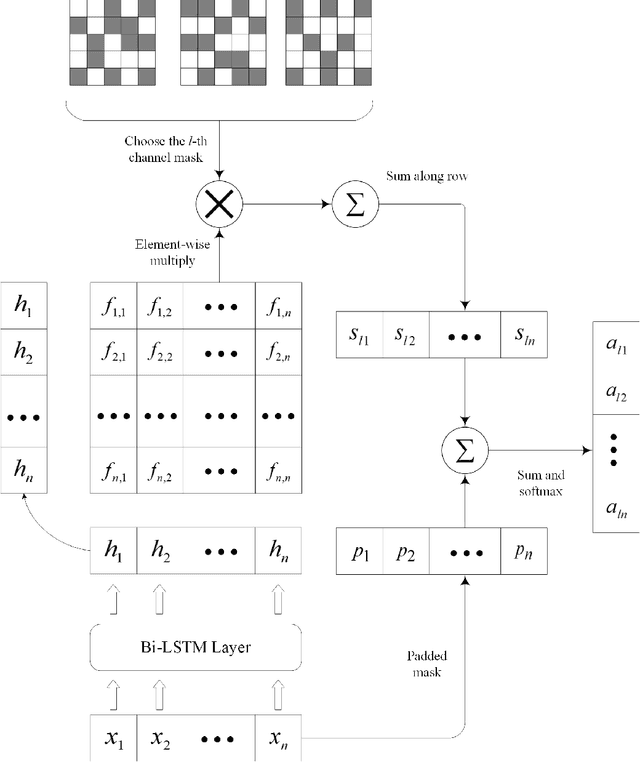
Multichannel CNN with Attention for Text Classification
Jun 29, 2020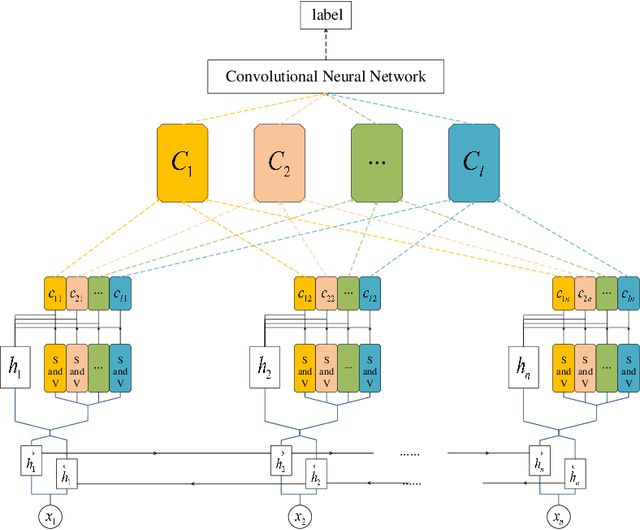
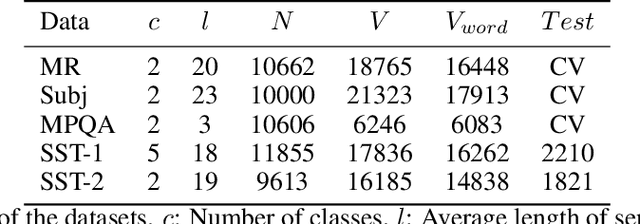
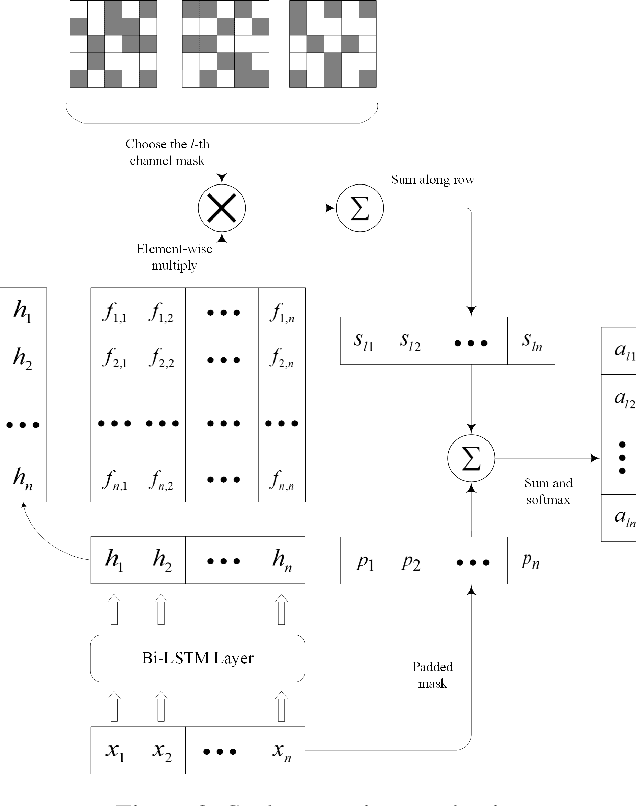
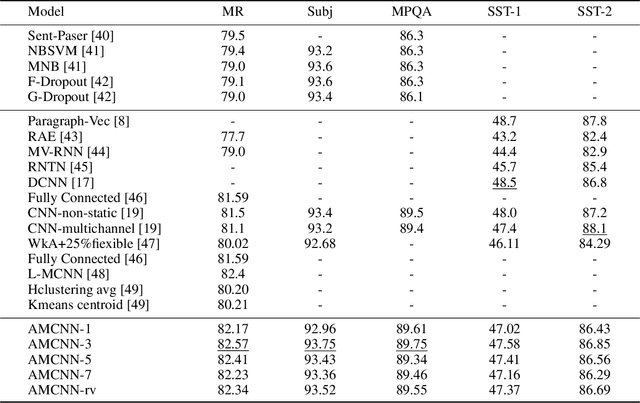
Recent years, the approaches based on neural networks have shown remarkable potential for sentence modeling. There are two main neural network structures: recurrent neural network (RNN) and convolution neural network (CNN). RNN can capture long term dependencies and store the semantics of the previous information in a fixed-sized vector. However, RNN is a biased model and its ability to extract global semantics is restricted by the fixed-sized vector. Alternatively, CNN is able to capture n-gram features of texts by utilizing convolutional filters. But the width of convolutional filters restricts its performance. In order to combine the strengths of the two kinds of networks and alleviate their shortcomings, this paper proposes Attention-based Multichannel Convolutional Neural Network (AMCNN) for text classification. AMCNN utilizes a bi-directional long short-term memory to encode the history and future information of words into high dimensional representations, so that the information of both the front and back of the sentence can be fully expressed. Then the scalar attention and vectorial attention are applied to obtain multichannel representations. The scalar attention can calculate the word-level importance and the vectorial attention can calculate the feature-level importance. In the classification task, AMCNN uses a CNN structure to cpture word relations on the representations generated by the scalar and vectorial attention mechanism instead of calculating the weighted sums. It can effectively extract the n-gram features of the text. The experimental results on the benchmark datasets demonstrate that AMCNN achieves better performance than state-of-the-art methods. In addition, the visualization results verify the semantic richness of multichannel representations.
Combine Convolution with Recurrent Networks for Text Classification
Jun 29, 2020
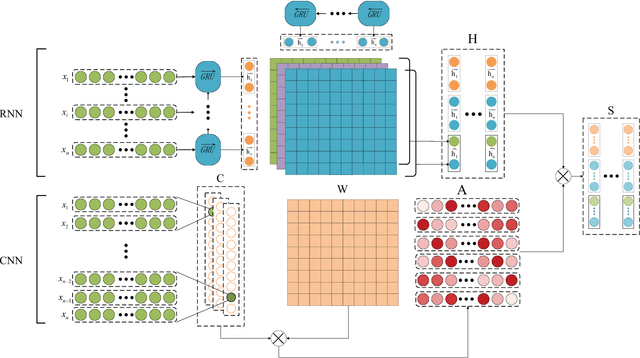

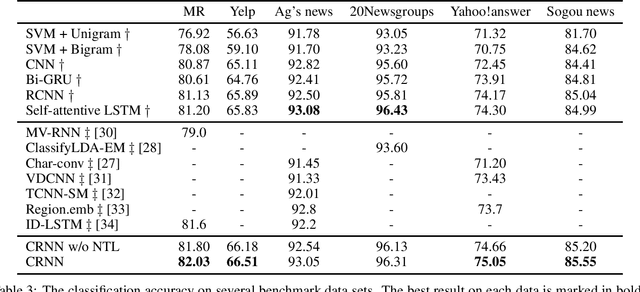
Convolutional neural network (CNN) and recurrent neural network (RNN) are two popular architectures used in text classification. Traditional methods to combine the strengths of the two networks rely on streamlining them or concatenating features extracted from them. In this paper, we propose a novel method to keep the strengths of the two networks to a great extent. In the proposed model, a convolutional neural network is applied to learn a 2D weight matrix where each row reflects the importance of each word from different aspects. Meanwhile, we use a bi-directional RNN to process each word and employ a neural tensor layer that fuses forward and backward hidden states to get word representations. In the end, the weight matrix and word representations are combined to obtain the representation in a 2D matrix form for the text. We carry out experiments on a number of datasets for text classification. The experimental results confirm the effectiveness of the proposed method.
Probabilistic Classification Vector Machine for Multi-Class Classification
Jun 29, 2020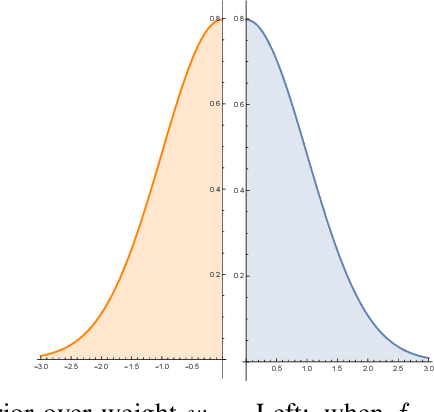



The probabilistic classification vector machine (PCVM) synthesizes the advantages of both the support vector machine and the relevant vector machine, delivering a sparse Bayesian solution to classification problems. However, the PCVM is currently only applicable to binary cases. Extending the PCVM to multi-class cases via heuristic voting strategies such as one-vs-rest or one-vs-one often results in a dilemma where classifiers make contradictory predictions, and those strategies might lose the benefits of probabilistic outputs. To overcome this problem, we extend the PCVM and propose a multi-class probabilistic classification vector machine (mPCVM). Two learning algorithms, i.e., one top-down algorithm and one bottom-up algorithm, have been implemented in the mPCVM. The top-down algorithm obtains the maximum a posteriori (MAP) point estimates of the parameters based on an expectation-maximization algorithm, and the bottom-up algorithm is an incremental paradigm by maximizing the marginal likelihood. The superior performance of the mPCVMs, especially when the investigated problem has a large number of classes, is extensively evaluated on synthetic and benchmark data sets.