 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre ID Embeddings Necessary? Whitening Pre-trained Text Embeddings for Effective Sequential Recommendation
Feb 16, 2024
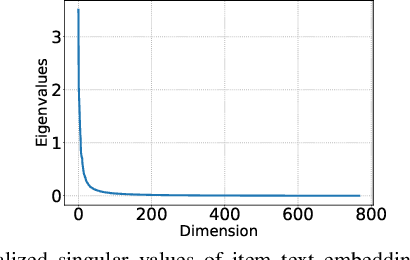


Recent sequential recommendation models have combined pre-trained text embeddings of items with item ID embeddings to achieve superior recommendation performance. Despite their effectiveness, the expressive power of text features in these models remains largely unexplored. While most existing models emphasize the importance of ID embeddings in recommendations, our study takes a step further by studying sequential recommendation models that only rely on text features and do not necessitate ID embeddings. Upon examining pretrained text embeddings experimentally, we discover that they reside in an anisotropic semantic space, with an average cosine similarity of over 0.8 between items. We also demonstrate that this anisotropic nature hinders recommendation models from effectively differentiating between item representations and leads to degenerated performance. To address this issue, we propose to employ a pre-processing step known as whitening transformation, which transforms the anisotropic text feature distribution into an isotropic Gaussian distribution. Our experiments show that whitening pre-trained text embeddings in the sequential model can significantly improve recommendation performance. However, the full whitening operation might break the potential manifold of items with similar text semantics. To preserve the original semantics while benefiting from the isotropy of the whitened text features, we introduce WhitenRec+, an ensemble approach that leverages both fully whitened and relaxed whitened item representations for effective recommendations. We further discuss and analyze the benefits of our design through experiments and proofs. Experimental results on three public benchmark datasets demonstrate that WhitenRec+ outperforms state-of-the-art methods for sequential recommendation.
Multimodal Pre-training Framework for Sequential Recommendation via Contrastive Learning
Mar 21, 2023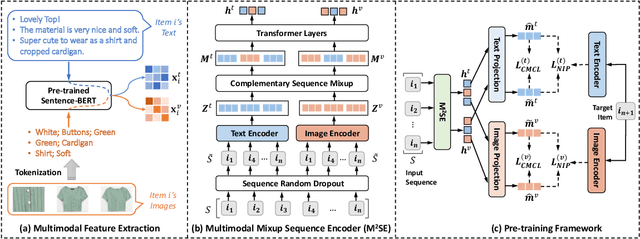
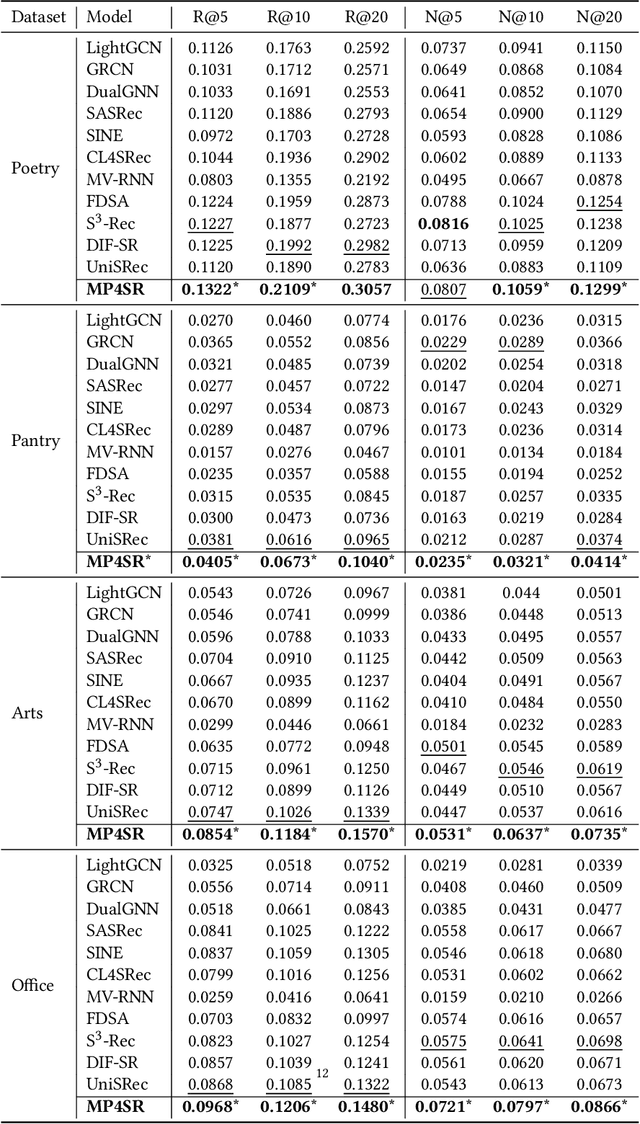
Sequential recommendation systems utilize the sequential interactions of users with items as their main supervision signals in learning users' preferences. However, existing methods usually generate unsatisfactory results due to the sparsity of user behavior data. To address this issue, we propose a novel pre-training framework, named Multimodal Sequence Mixup for Sequential Recommendation (MSM4SR), which leverages both users' sequential behaviors and items' multimodal content (\ie text and images) for effectively recommendation. Specifically, MSM4SR tokenizes each item image into multiple textual keywords and uses the pre-trained BERT model to obtain initial textual and visual features of items, for eliminating the discrepancy between the text and image modalities. A novel backbone network, \ie Multimodal Mixup Sequence Encoder (M$^2$SE), is proposed to bridge the gap between the item multimodal content and the user behavior, using a complementary sequence mixup strategy. In addition, two contrastive learning tasks are developed to assist M$^2$SE in learning generalized multimodal representations of the user behavior sequence. Extensive experiments on real-world datasets demonstrate that MSM4SR outperforms state-of-the-art recommendation methods. Moreover, we further verify the effectiveness of MSM4SR on other challenging tasks including cold-start and cross-domain recommendation.
A Comprehensive Survey on Multimodal Recommender Systems: Taxonomy, Evaluation, and Future Directions
Feb 09, 2023Recommendation systems have become popular and effective tools to help users discover their interesting items by modeling the user preference and item property based on implicit interactions (e.g., purchasing and clicking). Humans perceive the world by processing the modality signals (e.g., audio, text and image), which inspired researchers to build a recommender system that can understand and interpret data from different modalities. Those models could capture the hidden relations between different modalities and possibly recover the complementary information which can not be captured by a uni-modal approach and implicit interactions. The goal of this survey is to provide a comprehensive review of the recent research efforts on the multimodal recommendation. Specifically, it shows a clear pipeline with commonly used techniques in each step and classifies the models by the methods used. Additionally, a code framework has been designed that helps researchers new in this area to understand the principles and techniques, and easily runs the SOTA models. Our framework is located at: https://github.com/enoche/MMRec
Enhancing Dyadic Relations with Homogeneous Graphs for Multimodal Recommendation
Feb 09, 2023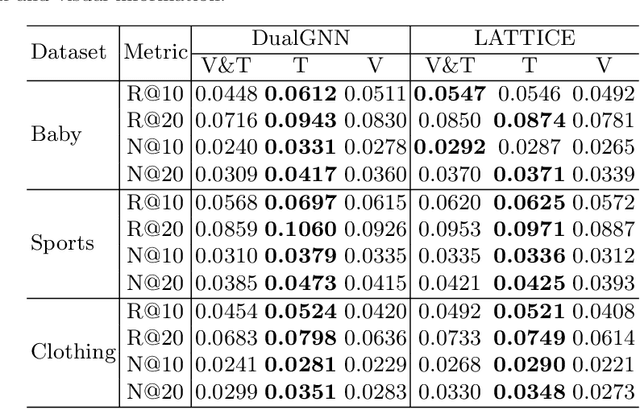
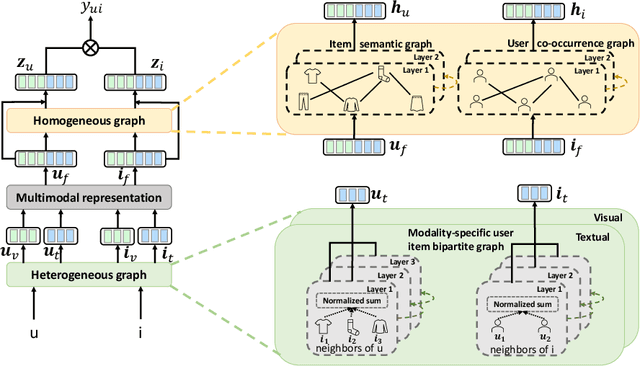
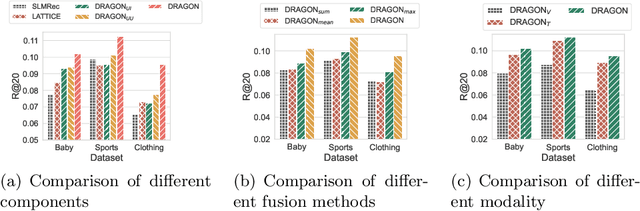
User interaction data in recommender systems is a form of dyadic relation that reflects the preferences of users with items. Learning the representations of these two discrete sets of objects, users and items, is critical for recommendation. Recent multimodal recommendation models leveraging multimodal features (e.g., images and text descriptions) have been demonstrated to be effective in improving recommendation accuracy. However, state-of-the-art models enhance the dyadic relations between users and items by considering either user-user or item-item relations, leaving the high-order relations of the other side (i.e., users or items) unexplored. Furthermore, we experimentally reveal that the current multimodality fusion methods in the state-of-the-art models may degrade their recommendation performance. That is, without tainting the model architectures, these models can achieve even better recommendation accuracy with uni-modal information. On top of the finding, we propose a model that enhances the dyadic relations by learning Dual RepresentAtions of both users and items via constructing homogeneous Graphs for multimOdal recommeNdation. We name our model as DRAGON. Specifically, DRAGON constructs the user-user graph based on the commonly interacted items and the item-item graph from item multimodal features. It then utilizes graph learning on both the user-item heterogeneous graph and the homogeneous graphs (user-user and item-item) to obtain the dual representations of users and items. To capture information from each modality, DRAGON employs a simple yet effective fusion method, attentive concatenation, to derive the representations of users and items. Extensive experiments on three public datasets and seven baselines show that DRAGON can outperform the strongest baseline by 22.03% on average. Various ablation studies are conducted on DRAGON to validate its effectiveness.