 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Dyadic Relations with Homogeneous Graphs for Multimodal Recommendation
Paper and Code
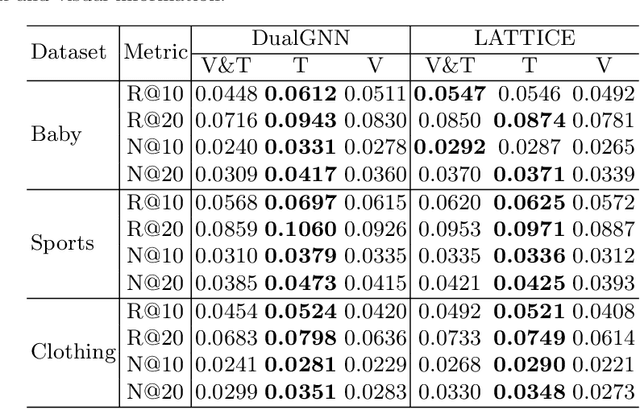
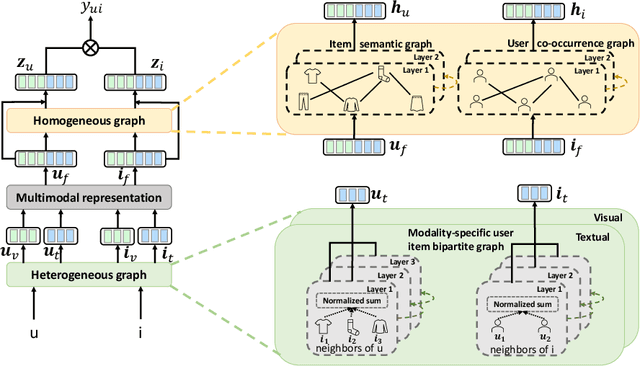
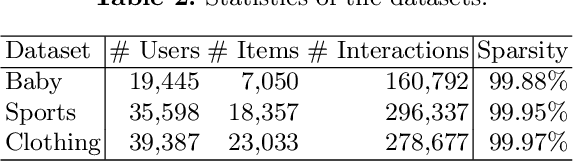
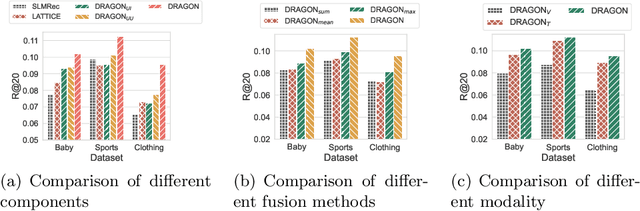
User interaction data in recommender systems is a form of dyadic relation that reflects the preferences of users with items. Learning the representations of these two discrete sets of objects, users and items, is critical for recommendation. Recent multimodal recommendation models leveraging multimodal features (e.g., images and text descriptions) have been demonstrated to be effective in improving recommendation accuracy. However, state-of-the-art models enhance the dyadic relations between users and items by considering either user-user or item-item relations, leaving the high-order relations of the other side (i.e., users or items) unexplored. Furthermore, we experimentally reveal that the current multimodality fusion methods in the state-of-the-art models may degrade their recommendation performance. That is, without tainting the model architectures, these models can achieve even better recommendation accuracy with uni-modal information. On top of the finding, we propose a model that enhances the dyadic relations by learning Dual RepresentAtions of both users and items via constructing homogeneous Graphs for multimOdal recommeNdation. We name our model as DRAGON. Specifically, DRAGON constructs the user-user graph based on the commonly interacted items and the item-item graph from item multimodal features. It then utilizes graph learning on both the user-item heterogeneous graph and the homogeneous graphs (user-user and item-item) to obtain the dual representations of users and items. To capture information from each modality, DRAGON employs a simple yet effective fusion method, attentive concatenation, to derive the representations of users and items. Extensive experiments on three public datasets and seven baselines show that DRAGON can outperform the strongest baseline by 22.03% on average. Various ablation studies are conducted on DRAGON to validate its effectiveness.