 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevMUX: Data Multiplexing with Reversible Adapters for Efficient LLM Batch Inference
Paper and Code
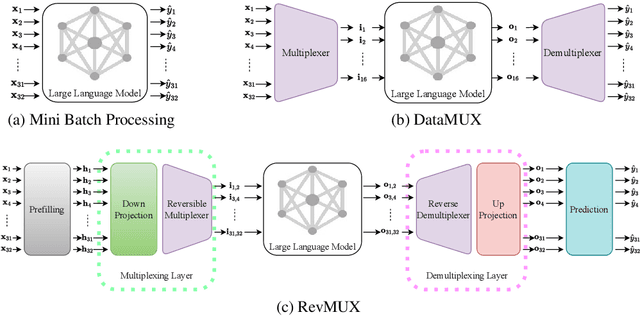
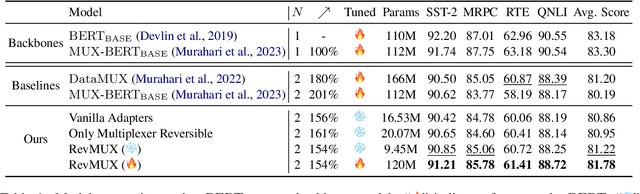
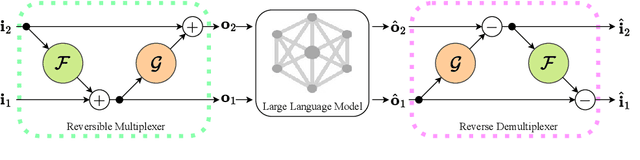
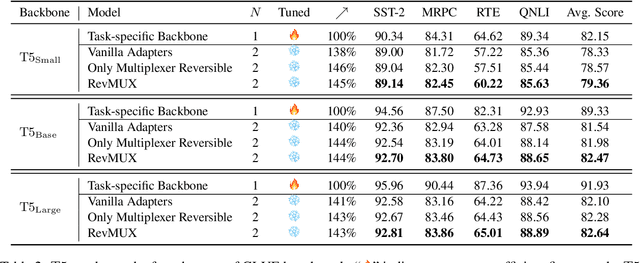
Large language models (LLMs) have brought a great breakthrough to the natural language processing (NLP) community, while leading the challenge of handling concurrent customer queries due to their high throughput demands. Data multiplexing addresses this by merging multiple inputs into a single composite input, allowing more efficient inference through a shared forward pass. However, as distinguishing individuals from a composite input is challenging, conventional methods typically require training the entire backbone, yet still suffer from performance degradation. In this paper, we introduce RevMUX, a parameter-efficient data multiplexing framework that incorporates a reversible design in the multiplexer, which can be reused by the demultiplexer to perform reverse operations and restore individual samples for classification. Extensive experiments on four datasets and three types of LLM backbones demonstrate the effectiveness of RevMUX for enhancing LLM inference efficiency while retaining a satisfactory classification performance.