 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveiling Fine-Grained Visual Traces: Evaluating Multimodal Interleaved Reasoning Chains in Multimodal STEM Tasks
Apr 21, 2026Multimodal large language models (MLLMs) have shown promising reasoning abilities, yet evaluating their performance in specialized domains remains challenging. STEM reasoning is a particularly valuable testbed because it provides highly verifiable feedback, but existing benchmarks often permit unimodal shortcuts due to modality redundancy and focus mainly on final-answer accuracy, overlooking the reasoning process itself. To address this challenge, we introduce StepSTEM: a graduate-level benchmark of 283 problems across mathematics, physics, chemistry, biology, and engineering for fine-grained evaluation of cross-modal reasoning in MLLMs. StepSTEM is constructed through a rigorous curation pipeline that enforces strict complementarity between textual and visual inputs. We further propose a general step-level evaluation framework for both text-only chain-of-thought and interleaved image-text reasoning, using dynamic programming to align predicted reasoning steps with multiple reference solutions. Experiments across a wide range of models show that current MLLMs still rely heavily on textual reasoning, with even Gemini 3.1 Pro and Claude Opus 4.6 achieving only 38.29% accuracy. These results highlight substantial headroom for genuine cross-modal STEM reasoning and position StepSTEM as a benchmark for fine-grained evaluation of multimodal reasoning. Source code is available at https://github.com/lll-hhh/STEPSTEM.
SoftCoT++: Test-Time Scaling with Soft Chain-of-Thought Reasoning
May 16, 2025



Test-Time Scaling (TTS) refers to approaches that improve reasoning performance by allocating extra computation during inference, without altering the model's parameters. While existing TTS methods operate in a discrete token space by generating more intermediate steps, recent studies in Coconut and SoftCoT have demonstrated that thinking in the continuous latent space can further enhance the reasoning performance. Such latent thoughts encode informative thinking without the information loss associated with autoregressive token generation, sparking increased interest in continuous-space reasoning. Unlike discrete decoding, where repeated sampling enables exploring diverse reasoning paths, latent representations in continuous space are fixed for a given input, which limits diverse exploration, as all decoded paths originate from the same latent thought. To overcome this limitation, we introduce SoftCoT++ to extend SoftCoT to the Test-Time Scaling paradigm by enabling diverse exploration of thinking paths. Specifically, we perturb latent thoughts via multiple specialized initial tokens and apply contrastive learning to promote diversity among soft thought representations. Experiments across five reasoning benchmarks and two distinct LLM architectures demonstrate that SoftCoT++ significantly boosts SoftCoT and also outperforms SoftCoT with self-consistency scaling. Moreover, it shows strong compatibility with conventional scaling techniques such as self-consistency. Source code is available at https://github.com/xuyige/SoftCoT.
SoftCoT: Soft Chain-of-Thought for Efficient Reasoning with LLMs
Feb 17, 2025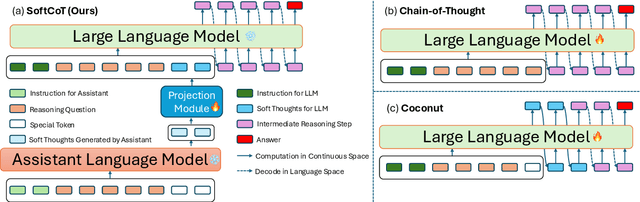


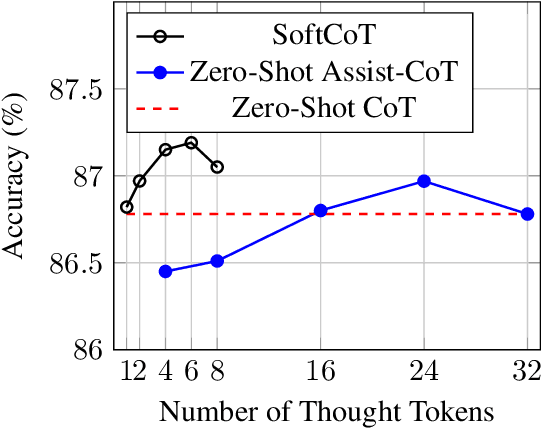
Chain-of-Thought (CoT) reasoning enables Large Language Models (LLMs) to solve complex reasoning tasks by generating intermediate reasoning steps. However, most existing approaches focus on hard token decoding, which constrains reasoning within the discrete vocabulary space and may not always be optimal. While recent efforts explore continuous-space reasoning, they often suffer from catastrophic forgetting, limiting their applicability to state-of-the-art LLMs that already perform well in zero-shot settings with a proper instruction. To address this challenge, we propose a novel approach for continuous-space reasoning that does not require modifying the underlying LLM. Specifically, we employ a lightweight assistant model to generate instance-specific soft thought tokens speculatively as the initial chain of thoughts, which are then mapped into the LLM's representation space via a projection module. Experimental results on five reasoning benchmarks demonstrate that our method enhances LLM reasoning performance through supervised, parameter-efficient fine-tuning.
RevMUX: Data Multiplexing with Reversible Adapters for Efficient LLM Batch Inference
Oct 06, 2024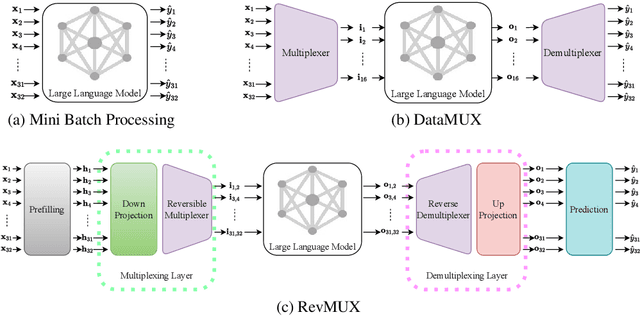
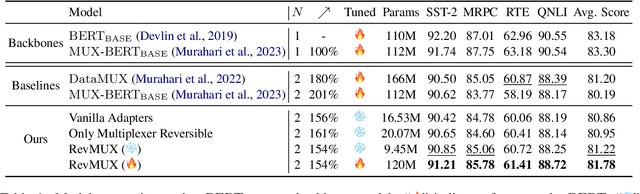
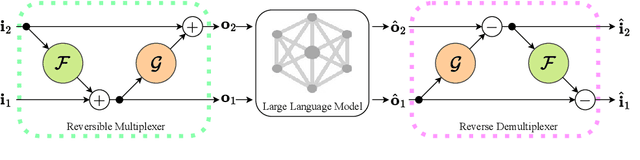
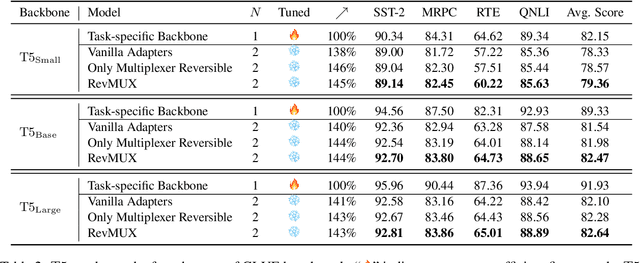
Large language models (LLMs) have brought a great breakthrough to the natural language processing (NLP) community, while leading the challenge of handling concurrent customer queries due to their high throughput demands. Data multiplexing addresses this by merging multiple inputs into a single composite input, allowing more efficient inference through a shared forward pass. However, as distinguishing individuals from a composite input is challenging, conventional methods typically require training the entire backbone, yet still suffer from performance degradation. In this paper, we introduce RevMUX, a parameter-efficient data multiplexing framework that incorporates a reversible design in the multiplexer, which can be reused by the demultiplexer to perform reverse operations and restore individual samples for classification. Extensive experiments on four datasets and three types of LLM backbones demonstrate the effectiveness of RevMUX for enhancing LLM inference efficiency while retaining a satisfactory classification performance.
Efficient Cross-Task Prompt Tuning for Few-Shot Conversational Emotion Recognition
Oct 23, 2023



Emotion Recognition in Conversation (ERC) has been widely studied due to its importance in developing emotion-aware empathetic machines. The rise of pre-trained language models (PLMs) has further pushed the limit of ERC performance. However, most recent works on ERC using PLMs are heavily data-driven, and requires fine-tuning the entire PLMs. To improve both sample and computational efficiency, we propose a derivative-free optimization method called Cross-Task Prompt Tuning (CTPT) for few-shot conversational emotion recognition. Unlike existing methods that learn independent knowledge from individual tasks, CTPT leverages sharable cross-task knowledge by exploiting external knowledge from other source tasks to improve learning performance under the few-shot setting. Moreover, CTPT only needs to optimize a vector under the low intrinsic dimensionality without gradient, which is highly parameter-efficient compared with existing approaches. Experiments on five different contextual conversation datasets demonstrate that our CTPT method has superior results on both few-shot scenarios and zero-shot transfers.
One2Set: Generating Diverse Keyphrases as a Set
May 24, 2021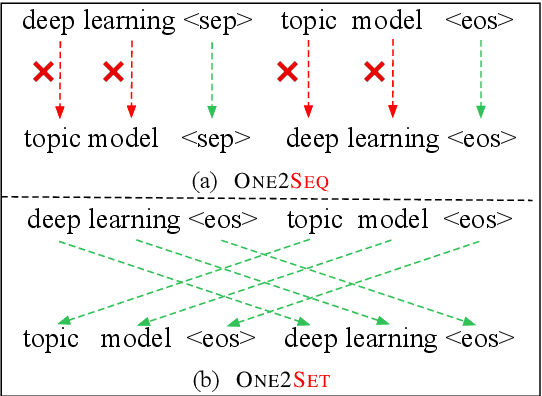
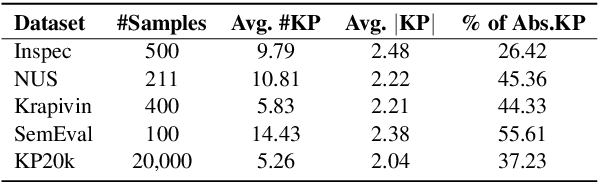
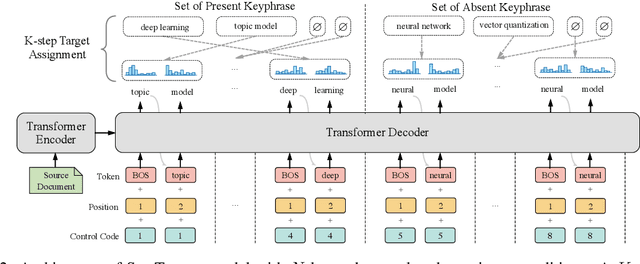
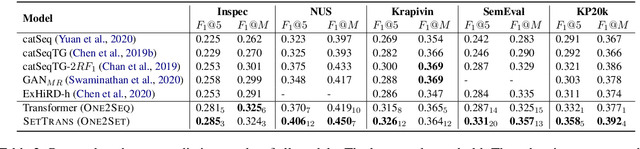
Recently, the sequence-to-sequence models have made remarkable progress on the task of keyphrase generation (KG) by concatenating multiple keyphrases in a predefined order as a target sequence during training. However, the keyphrases are inherently an unordered set rather than an ordered sequence. Imposing a predefined order will introduce wrong bias during training, which can highly penalize shifts in the order between keyphrases. In this work, we propose a new training paradigm One2Set without predefining an order to concatenate the keyphrases. To fit this paradigm, we propose a novel model that utilizes a fixed set of learned control codes as conditions to generate a set of keyphrases in parallel. To solve the problem that there is no correspondence between each prediction and target during training, we propose a $K$-step target assignment mechanism via bipartite matching, which greatly increases the diversity and reduces the duplication ratio of generated keyphrases. The experimental results on multiple benchmarks demonstrate that our approach significantly outperforms the state-of-the-art methods.
Keyphrase Generation with Fine-Grained Evaluation-Guided Reinforcement Learning
Apr 18, 2021
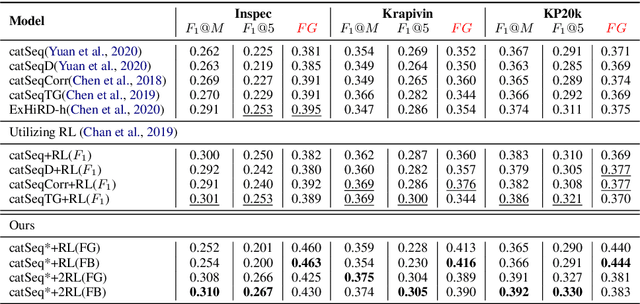
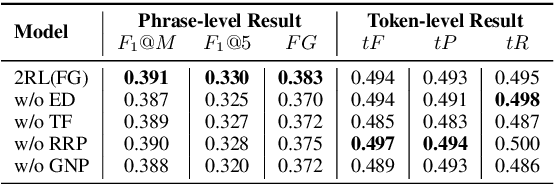

Aiming to generate a set of keyphrases, Keyphrase Generation (KG) is a classical task for capturing the central idea from a given document. Typically, traditional KG evaluation metrics are only aware of the exact correctness of predictions on phrase-level and ignores the semantic similarities between similar predictions and targets, which inhibits the model from learning deep linguistic patterns. In this paper, we propose a new fine-grained evaluation metric that considers different granularity: token-level $F_1$ score, edit distance, duplication, and prediction quantities. For learning more recessive linguistic patterns, we use a pre-trained model (e.g., BERT) to compute the continuous similarity score between predicted keyphrases and target keyphrases. On the whole, we propose a two-stage Reinforcement Learning (RL) training framework with two reward functions: our proposed fine-grained evaluation score and the vanilla $F_1$ score. This framework helps the model identifying some partial match phrases which can be further optimized as the exact match ones. Experiments on four KG benchmarks show that our proposed training framework outperforms the traditional RL training frameworks among all evaluation scores. In addition, our method can effectively ease the synonym problem and generate a higher quality prediction.
Pre-trained Models for Natural Language Processing: A Survey
Apr 24, 2020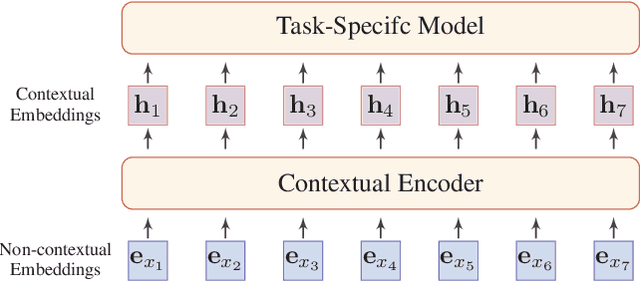
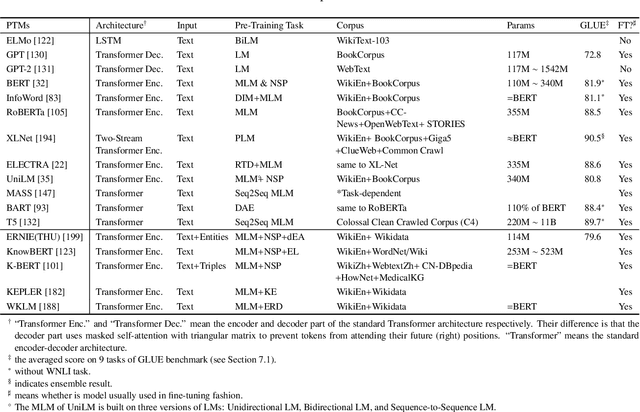

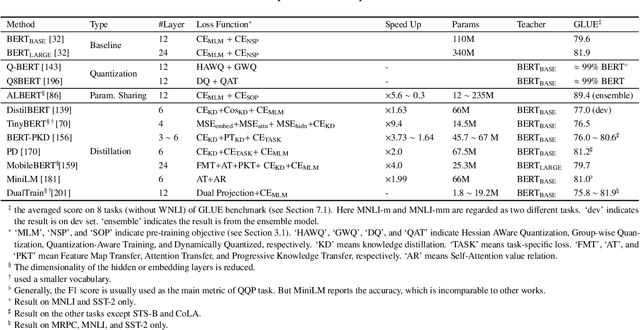
Recently, the emergence of pre-trained models (PTMs) has brought natural language processing (NLP) to a new era. In this survey, we provide a comprehensive review of PTMs for NLP. We first briefly introduce language representation learning and its research progress. Then we systematically categorize existing PTMs based on a taxonomy with four perspectives. Next, we describe how to adapt the knowledge of PTMs to the downstream tasks. Finally, we outline some potential directions of PTMs for future research. This survey is purposed to be a hands-on guide for understanding, using, and developing PTMs for various NLP tasks.
Improving BERT Fine-Tuning via Self-Ensemble and Self-Distillation
Feb 24, 2020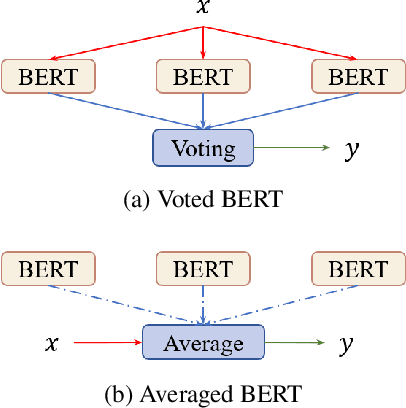

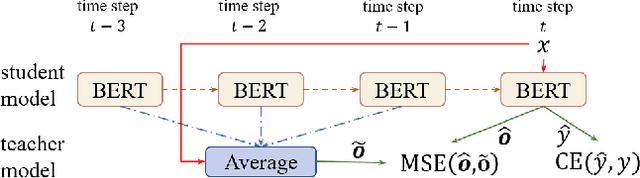

Fine-tuning pre-trained language models like BERT has become an effective way in NLP and yields state-of-the-art results on many downstream tasks. Recent studies on adapting BERT to new tasks mainly focus on modifying the model structure, re-designing the pre-train tasks, and leveraging external data and knowledge. The fine-tuning strategy itself has yet to be fully explored. In this paper, we improve the fine-tuning of BERT with two effective mechanisms: self-ensemble and self-distillation. The experiments on text classification and natural language inference tasks show our proposed methods can significantly improve the adaption of BERT without any external data or knowledge.
How to Fine-Tune BERT for Text Classification?
May 14, 2019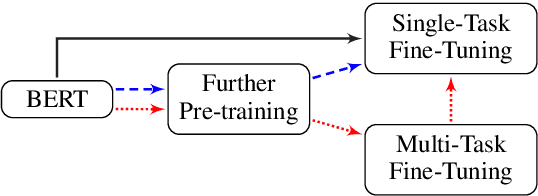
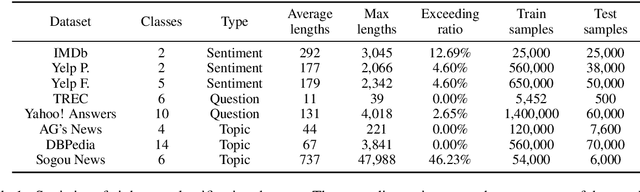
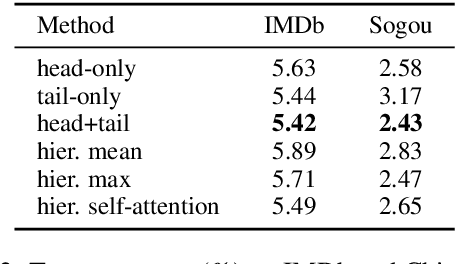
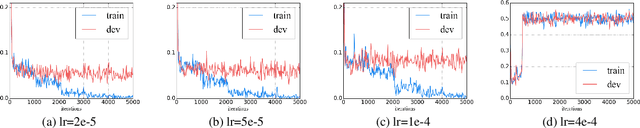
Language model pre-training has proven to be useful in learning universal language representations. As a state-of-the-art language model pre-training model, BERT (Bidirectional Encoder Representations from Transformers) has achieved amazing results in many language understanding tasks. In this paper, we conduct exhaustive experiments to investigate different fine-tuning methods of BERT on text classification task and provide a general solution for BERT fine-tuning. Finally, the proposed solution obtains new state-of-the-art results on eight widely-studied text classification datasets.