 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne2Set: Generating Diverse Keyphrases as a Set
May 24, 2021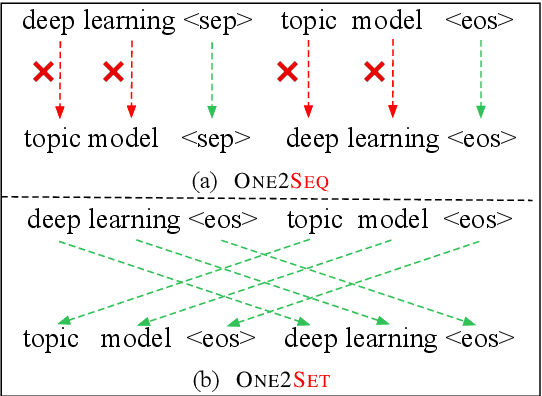
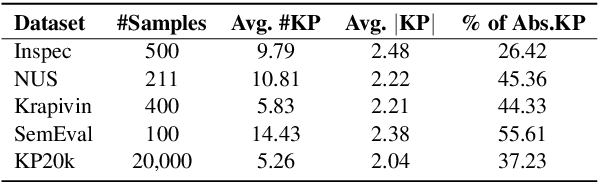
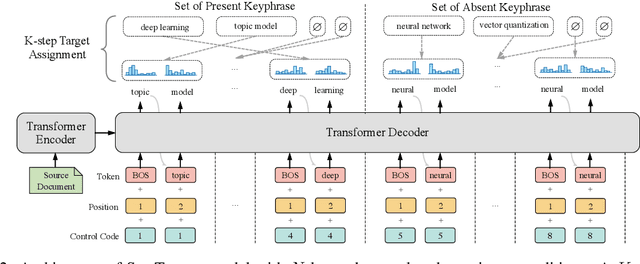
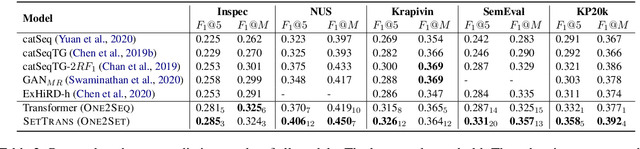
Recently, the sequence-to-sequence models have made remarkable progress on the task of keyphrase generation (KG) by concatenating multiple keyphrases in a predefined order as a target sequence during training. However, the keyphrases are inherently an unordered set rather than an ordered sequence. Imposing a predefined order will introduce wrong bias during training, which can highly penalize shifts in the order between keyphrases. In this work, we propose a new training paradigm One2Set without predefining an order to concatenate the keyphrases. To fit this paradigm, we propose a novel model that utilizes a fixed set of learned control codes as conditions to generate a set of keyphrases in parallel. To solve the problem that there is no correspondence between each prediction and target during training, we propose a $K$-step target assignment mechanism via bipartite matching, which greatly increases the diversity and reduces the duplication ratio of generated keyphrases. The experimental results on multiple benchmarks demonstrate that our approach significantly outperforms the state-of-the-art methods.
Keyphrase Generation with Fine-Grained Evaluation-Guided Reinforcement Learning
Apr 18, 2021
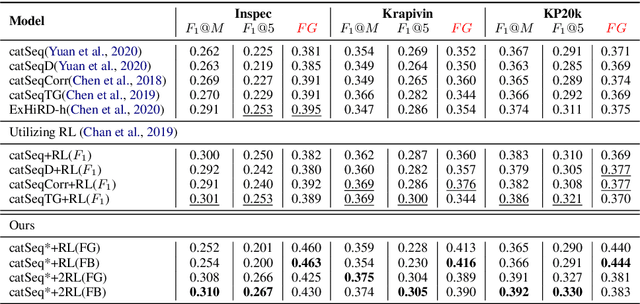
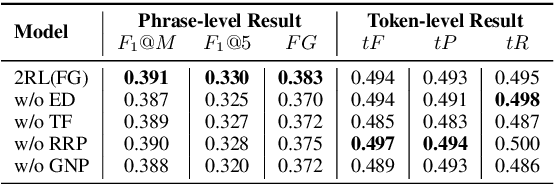

Aiming to generate a set of keyphrases, Keyphrase Generation (KG) is a classical task for capturing the central idea from a given document. Typically, traditional KG evaluation metrics are only aware of the exact correctness of predictions on phrase-level and ignores the semantic similarities between similar predictions and targets, which inhibits the model from learning deep linguistic patterns. In this paper, we propose a new fine-grained evaluation metric that considers different granularity: token-level $F_1$ score, edit distance, duplication, and prediction quantities. For learning more recessive linguistic patterns, we use a pre-trained model (e.g., BERT) to compute the continuous similarity score between predicted keyphrases and target keyphrases. On the whole, we propose a two-stage Reinforcement Learning (RL) training framework with two reward functions: our proposed fine-grained evaluation score and the vanilla $F_1$ score. This framework helps the model identifying some partial match phrases which can be further optimized as the exact match ones. Experiments on four KG benchmarks show that our proposed training framework outperforms the traditional RL training frameworks among all evaluation scores. In addition, our method can effectively ease the synonym problem and generate a higher quality prediction.
SenSeNet: Neural Keyphrase Generation with Document Structure
Dec 12, 2020

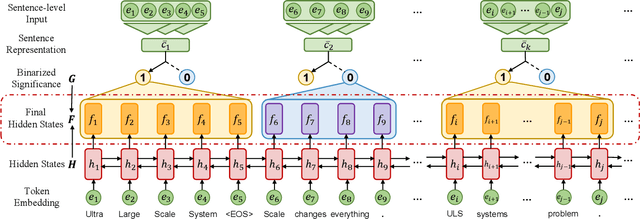
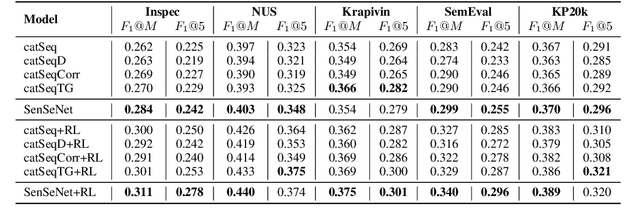
Keyphrase Generation (KG) is the task of generating central topics from a given document or literary work, which captures the crucial information necessary to understand the content. Documents such as scientific literature contain rich meta-sentence information, which represents the logical-semantic structure of the documents. However, previous approaches ignore the constraints of document logical structure, and hence they mistakenly generate keyphrases from unimportant sentences. To address this problem, we propose a new method called Sentence Selective Network (SenSeNet) to incorporate the meta-sentence inductive bias into KG. In SenSeNet, we use a straight-through estimator for end-to-end training and incorporate weak supervision in the training of the sentence selection module. Experimental results show that SenSeNet can consistently improve the performance of major KG models based on seq2seq framework, which demonstrate the effectiveness of capturing structural information and distinguishing the significance of sentences in KG task.