 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMAE: A Massive Multitask Audio Editing Benchmark
Jun 05, 2026We introduce MMAE, a Massive Multitask Audio Editing benchmark, serving as the first comprehensive evaluation testbed designed for general-purpose instruction-based audio editing. Spurred by the shift toward intelligent creation, interactive editing has rapidly expanded from visual domains, pioneered by models like Nano-banana 2 for images and Gemini-Omni for video, into audio. However, the current evaluation infrastructure lags severely, remaining highly fragmented and restricted to specific subdomains or basic operations. Unlike existing benchmarks that are limited in scope, MMAE extends to a broad spectrum of real-world scenarios, encompassing 7 distinct audio modalities, including sound, speech, music, and their mixtures. Furthermore, we establish a comprehensive taxonomy spanning 6 levels of task complexity, from basic modifications to multi-hop reasoning and multi-round editing, 2 levels of granularity, and 8 distinct operation types. Meticulously curated through human-agent collaboration, MMAE comprises 2,000 high-fidelity samples paired with a pioneering rubric-based evaluation framework. By decomposing free-form tasks into 17,741 verifiable criteria, this robust rubric-based paradigm enables a precise, multi-dimensional assessment of both instruction following and context consistency. Our extensive evaluation of leading models reveals that current systems remain far from achieving reliable edits. Strikingly, the Exact Match Rate (EMR) consistently falls below 5% and plummets to an absolute 0% in complex, mixed-modality tasks, exposing critical bottlenecks in precise execution and structural robustness. We hope MMAE will serve as a catalyst for future advances in the intelligent creation community, providing a clear diagnostic roadmap and establishing a standardized, long-lasting evaluation paradigm for next-generation audio editing systems.
TextFlint: Unified Multilingual Robustness Evaluation Toolkit for Natural Language Processing
Apr 06, 2021



Various robustness evaluation methodologies from different perspectives have been proposed for different natural language processing (NLP) tasks. These methods have often focused on either universal or task-specific generalization capabilities. In this work, we propose a multilingual robustness evaluation platform for NLP tasks (TextFlint) that incorporates universal text transformation, task-specific transformation, adversarial attack, subpopulation, and their combinations to provide comprehensive robustness analysis. TextFlint enables practitioners to automatically evaluate their models from all aspects or to customize their evaluations as desired with just a few lines of code. To guarantee user acceptability, all the text transformations are linguistically based, and we provide a human evaluation for each one. TextFlint generates complete analytical reports as well as targeted augmented data to address the shortcomings of the model's robustness. To validate TextFlint's utility, we performed large-scale empirical evaluations (over 67,000 evaluations) on state-of-the-art deep learning models, classic supervised methods, and real-world systems. Almost all models showed significant performance degradation, including a decline of more than 50% of BERT's prediction accuracy on tasks such as aspect-level sentiment classification, named entity recognition, and natural language inference. Therefore, we call for the robustness to be included in the model evaluation, so as to promote the healthy development of NLP technology.
SenSeNet: Neural Keyphrase Generation with Document Structure
Dec 12, 2020

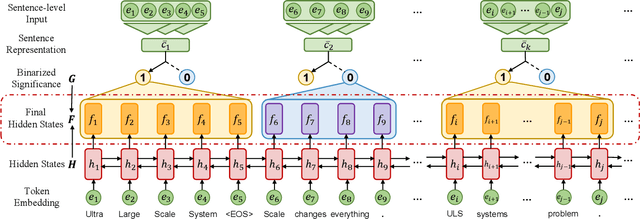
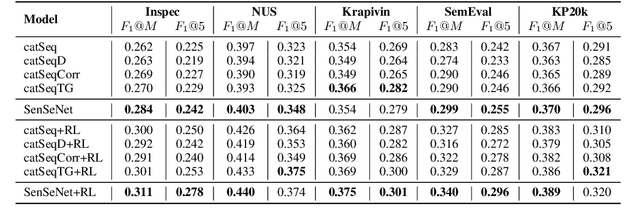
Keyphrase Generation (KG) is the task of generating central topics from a given document or literary work, which captures the crucial information necessary to understand the content. Documents such as scientific literature contain rich meta-sentence information, which represents the logical-semantic structure of the documents. However, previous approaches ignore the constraints of document logical structure, and hence they mistakenly generate keyphrases from unimportant sentences. To address this problem, we propose a new method called Sentence Selective Network (SenSeNet) to incorporate the meta-sentence inductive bias into KG. In SenSeNet, we use a straight-through estimator for end-to-end training and incorporate weak supervision in the training of the sentence selection module. Experimental results show that SenSeNet can consistently improve the performance of major KG models based on seq2seq framework, which demonstrate the effectiveness of capturing structural information and distinguishing the significance of sentences in KG task.
Tasty Burgers, Soggy Fries: Probing Aspect Robustness in Aspect-Based Sentiment Analysis
Oct 04, 2020
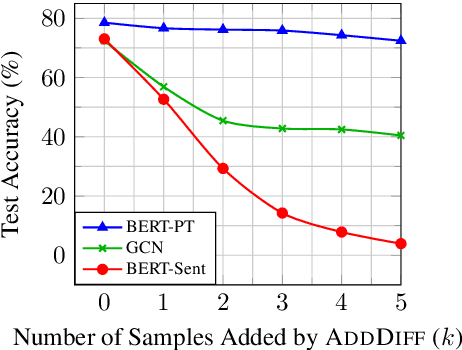


Aspect-based sentiment analysis (ABSA) aims to predict the sentiment towards a specific aspect in the text. However, existing ABSA test sets cannot be used to probe whether a model can distinguish the sentiment of the target aspect from the non-target aspects. To solve this problem, we develop a simple but effective approach to enrich ABSA test sets. Specifically, we generate new examples to disentangle the confounding sentiments of the non-target aspects from the target aspect's sentiment. Based on the SemEval 2014 dataset, we construct the Aspect Robustness Test Set (ARTS) as a comprehensive probe of the aspect robustness of ABSA models. Over 92% data of ARTS show high fluency and desired sentiment on all aspects by human evaluation. Using ARTS, we analyze the robustness of nine ABSA models, and observe, surprisingly, that their accuracy drops by up to 69.73%. We explore several ways to improve aspect robustness, and find that adversarial training can improve models' performance on ARTS by up to 32.85%. Our code and new test set are available at https://github.com/zhijing-jin/ARTS_TestSet
Distributed Evolution of Deep Autoencoders
Apr 16, 2020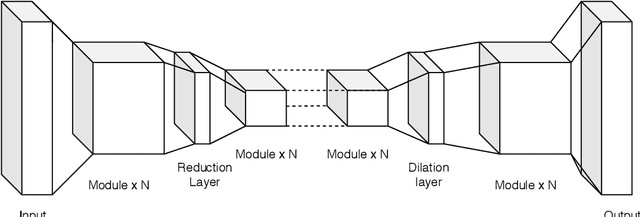
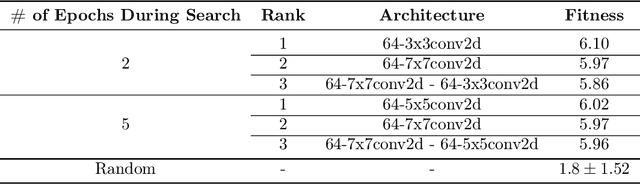

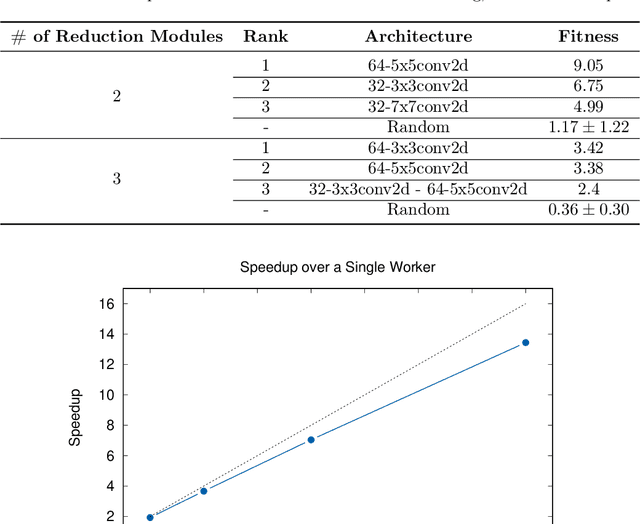
Autoencoders have seen wide success in domains ranging from feature selection to information retrieval. Despite this success, designing an autoencoder for a given task remains a challenging undertaking due to the lack of firm intuition on how the backing neural network architectures of the encoder and decoder impact the overall performance of the autoencoder. In this work we present a distributed system that uses an efficient evolutionary algorithm to design a modular autoencoder. We demonstrate the effectiveness of this system on the tasks of manifold learning and image denoising. The system beats random search by nearly an order of magnitude on both tasks while achieving near linear horizontal scaling as additional worker nodes are added to the system.
Distantly Supervised Named Entity Recognition using Positive-Unlabeled Learning
Jun 11, 2019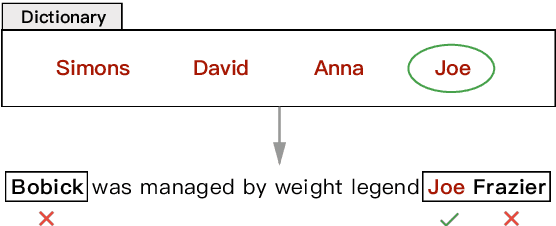
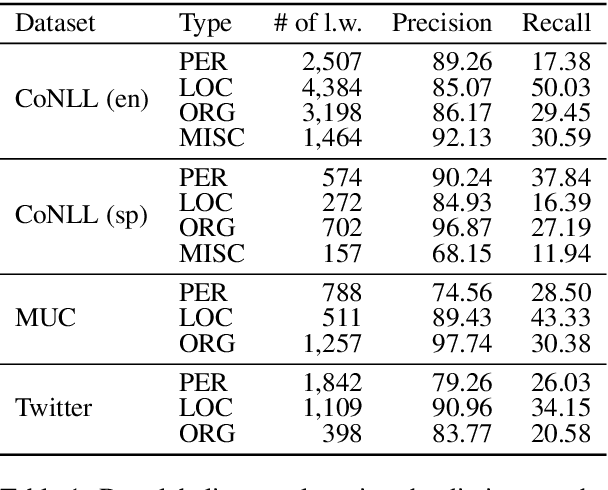
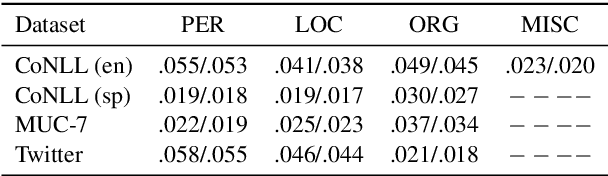
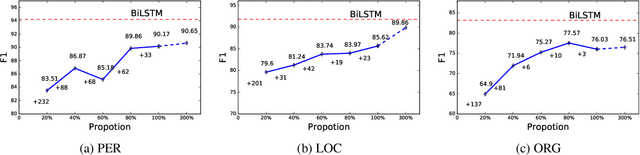
In this work, we explore the way to perform named entity recognition (NER) using only unlabeled data and named entity dictionaries. To this end, we formulate the task as a positive-unlabeled (PU) learning problem and accordingly propose a novel PU learning algorithm to perform the task. We prove that the proposed algorithm can unbiasedly and consistently estimate the task loss as if there is fully labeled data. A key feature of the proposed method is that it does not require the dictionaries to label every entity within a sentence, and it even does not require the dictionaries to label all of the words constituting an entity. This greatly reduces the requirement on the quality of the dictionaries and makes our method generalize well with quite simple dictionaries. Empirical studies on four public NER datasets demonstrate the effectiveness of our proposed method. We have published the source code at \url{https://github.com/v-mipeng/LexiconNER}.
Learning Task-specific Representation for Novel Words in Sequence Labeling
May 29, 2019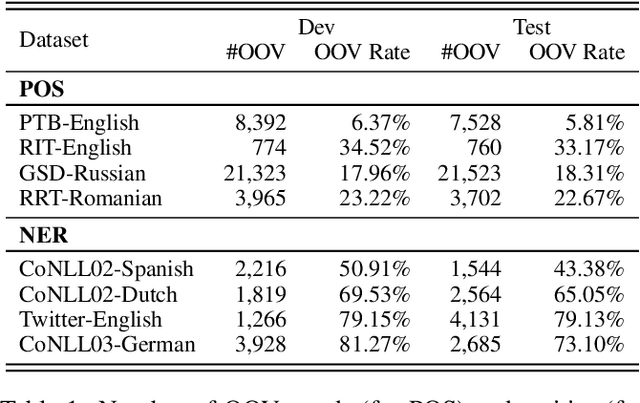
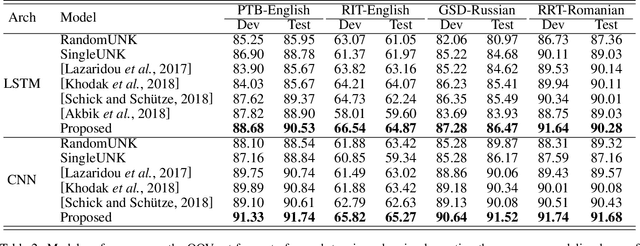
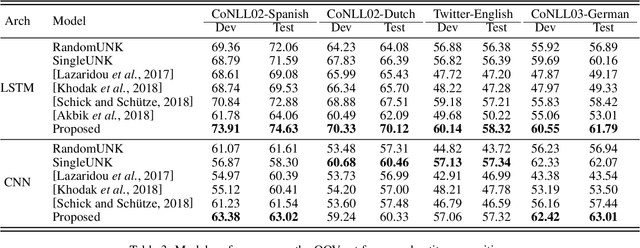
Word representation is a key component in neural-network-based sequence labeling systems. However, representations of unseen or rare words trained on the end task are usually poor for appreciable performance. This is commonly referred to as the out-of-vocabulary (OOV) problem. In this work, we address the OOV problem in sequence labeling using only training data of the task. To this end, we propose a novel method to predict representations for OOV words from their surface-forms (e.g., character sequence) and contexts. The method is specifically designed to avoid the error propagation problem suffered by existing approaches in the same paradigm. To evaluate its effectiveness, we performed extensive empirical studies on four part-of-speech tagging (POS) tasks and four named entity recognition (NER) tasks. Experimental results show that the proposed method can achieve better or competitive performance on the OOV problem compared with existing state-of-the-art methods.