 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Implicit Sentiment in Aspect-based Sentiment Analysis with Supervised Contrastive Pre-Training
Nov 03, 2021
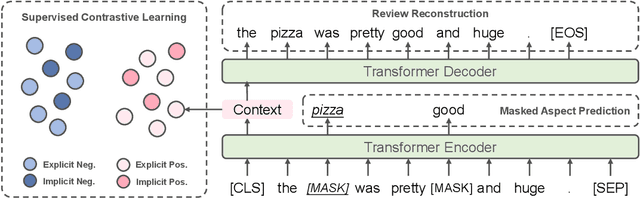
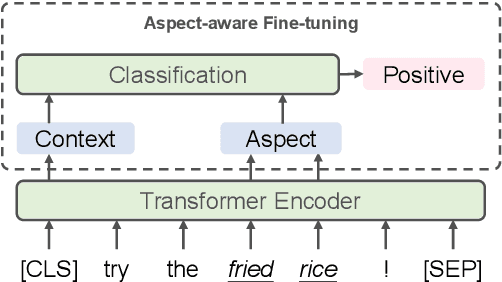

Aspect-based sentiment analysis aims to identify the sentiment polarity of a specific aspect in product reviews. We notice that about 30% of reviews do not contain obvious opinion words, but still convey clear human-aware sentiment orientation, which is known as implicit sentiment. However, recent neural network-based approaches paid little attention to implicit sentiment entailed in the reviews. To overcome this issue, we adopt Supervised Contrastive Pre-training on large-scale sentiment-annotated corpora retrieved from in-domain language resources. By aligning the representation of implicit sentiment expressions to those with the same sentiment label, the pre-training process leads to better capture of both implicit and explicit sentiment orientation towards aspects in reviews. Experimental results show that our method achieves state-of-the-art performance on SemEval2014 benchmarks, and comprehensive analysis validates its effectiveness on learning implicit sentiment.
TextFlint: Unified Multilingual Robustness Evaluation Toolkit for Natural Language Processing
Apr 06, 2021



Various robustness evaluation methodologies from different perspectives have been proposed for different natural language processing (NLP) tasks. These methods have often focused on either universal or task-specific generalization capabilities. In this work, we propose a multilingual robustness evaluation platform for NLP tasks (TextFlint) that incorporates universal text transformation, task-specific transformation, adversarial attack, subpopulation, and their combinations to provide comprehensive robustness analysis. TextFlint enables practitioners to automatically evaluate their models from all aspects or to customize their evaluations as desired with just a few lines of code. To guarantee user acceptability, all the text transformations are linguistically based, and we provide a human evaluation for each one. TextFlint generates complete analytical reports as well as targeted augmented data to address the shortcomings of the model's robustness. To validate TextFlint's utility, we performed large-scale empirical evaluations (over 67,000 evaluations) on state-of-the-art deep learning models, classic supervised methods, and real-world systems. Almost all models showed significant performance degradation, including a decline of more than 50% of BERT's prediction accuracy on tasks such as aspect-level sentiment classification, named entity recognition, and natural language inference. Therefore, we call for the robustness to be included in the model evaluation, so as to promote the healthy development of NLP technology.
Uncertainty-Aware Label Refinement for Sequence Labeling
Dec 19, 2020


Conditional random fields (CRF) for label decoding has become ubiquitous in sequence labeling tasks. However, the local label dependencies and inefficient Viterbi decoding have always been a problem to be solved. In this work, we introduce a novel two-stage label decoding framework to model long-term label dependencies, while being much more computationally efficient. A base model first predicts draft labels, and then a novel two-stream self-attention model makes refinements on these draft predictions based on long-range label dependencies, which can achieve parallel decoding for a faster prediction. In addition, in order to mitigate the side effects of incorrect draft labels, Bayesian neural networks are used to indicate the labels with a high probability of being wrong, which can greatly assist in preventing error propagation. The experimental results on three sequence labeling benchmarks demonstrated that the proposed method not only outperformed the CRF-based methods but also greatly accelerated the inference process.
SenSeNet: Neural Keyphrase Generation with Document Structure
Dec 12, 2020

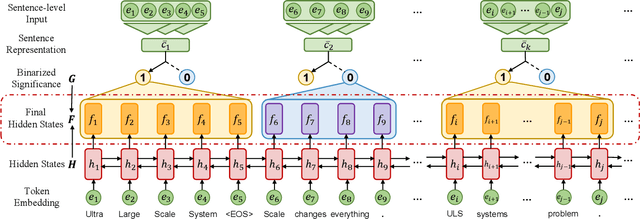
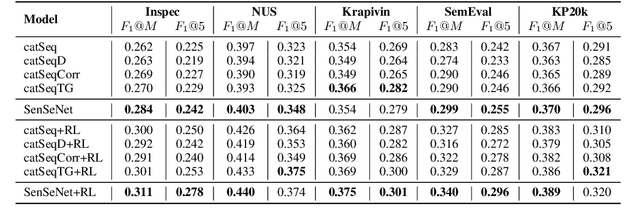
Keyphrase Generation (KG) is the task of generating central topics from a given document or literary work, which captures the crucial information necessary to understand the content. Documents such as scientific literature contain rich meta-sentence information, which represents the logical-semantic structure of the documents. However, previous approaches ignore the constraints of document logical structure, and hence they mistakenly generate keyphrases from unimportant sentences. To address this problem, we propose a new method called Sentence Selective Network (SenSeNet) to incorporate the meta-sentence inductive bias into KG. In SenSeNet, we use a straight-through estimator for end-to-end training and incorporate weak supervision in the training of the sentence selection module. Experimental results show that SenSeNet can consistently improve the performance of major KG models based on seq2seq framework, which demonstrate the effectiveness of capturing structural information and distinguishing the significance of sentences in KG task.