 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealBehavior: A Framework for Faithfully Characterizing Foundation Models' Human-like Behavior Mechanisms
Oct 17, 2023



Reports of human-like behaviors in foundation models are growing, with psychological theories providing enduring tools to investigate these behaviors. However, current research tends to directly apply these human-oriented tools without verifying the faithfulness of their outcomes. In this paper, we introduce a framework, RealBehavior, which is designed to characterize the humanoid behaviors of models faithfully. Beyond simply measuring behaviors, our framework assesses the faithfulness of results based on reproducibility, internal and external consistency, and generalizability. Our findings suggest that a simple application of psychological tools cannot faithfully characterize all human-like behaviors. Moreover, we discuss the impacts of aligning models with human and social values, arguing for the necessity of diversifying alignment objectives to prevent the creation of models with restricted characteristics.
Knowledge Solver: Teaching LLMs to Search for Domain Knowledge from Knowledge Graphs
Sep 06, 2023Large language models (LLMs), such as ChatGPT and GPT-4, are versatile and can solve different tasks due to their emergent ability and generalizability. However, LLMs sometimes lack domain-specific knowledge to perform tasks, which would also cause hallucination during inference. In some previous works, additional modules like graph neural networks (GNNs) are trained on retrieved knowledge from external knowledge bases, aiming to mitigate the problem of lacking domain-specific knowledge. However, incorporating additional modules: 1) would need retraining additional modules when encountering novel domains; 2) would become a bottleneck since LLMs' strong abilities are not fully utilized for retrieval. In this paper, we propose a paradigm, termed Knowledge Solver (KSL), to teach LLMs to search for essential knowledge from external knowledge bases by harnessing their own strong generalizability. Specifically, we design a simple yet effective prompt to transform retrieval into a multi-hop decision sequence, which empowers LLMs with searching knowledge ability in zero-shot manner. Additionally, KSL is able to provide complete retrieval paths and therefore increase explainability of LLMs' reasoning processes. We conduct experiments on three datasets: CommonsenseQA, OpenbookQA, and MedQA-USMLE, and found that our approach improves LLM baseline performance by a relatively large margin.
TextFlint: Unified Multilingual Robustness Evaluation Toolkit for Natural Language Processing
Apr 06, 2021



Various robustness evaluation methodologies from different perspectives have been proposed for different natural language processing (NLP) tasks. These methods have often focused on either universal or task-specific generalization capabilities. In this work, we propose a multilingual robustness evaluation platform for NLP tasks (TextFlint) that incorporates universal text transformation, task-specific transformation, adversarial attack, subpopulation, and their combinations to provide comprehensive robustness analysis. TextFlint enables practitioners to automatically evaluate their models from all aspects or to customize their evaluations as desired with just a few lines of code. To guarantee user acceptability, all the text transformations are linguistically based, and we provide a human evaluation for each one. TextFlint generates complete analytical reports as well as targeted augmented data to address the shortcomings of the model's robustness. To validate TextFlint's utility, we performed large-scale empirical evaluations (over 67,000 evaluations) on state-of-the-art deep learning models, classic supervised methods, and real-world systems. Almost all models showed significant performance degradation, including a decline of more than 50% of BERT's prediction accuracy on tasks such as aspect-level sentiment classification, named entity recognition, and natural language inference. Therefore, we call for the robustness to be included in the model evaluation, so as to promote the healthy development of NLP technology.
Uncertainty-Aware Label Refinement for Sequence Labeling
Dec 19, 2020


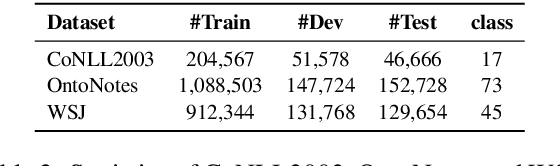
Conditional random fields (CRF) for label decoding has become ubiquitous in sequence labeling tasks. However, the local label dependencies and inefficient Viterbi decoding have always been a problem to be solved. In this work, we introduce a novel two-stage label decoding framework to model long-term label dependencies, while being much more computationally efficient. A base model first predicts draft labels, and then a novel two-stream self-attention model makes refinements on these draft predictions based on long-range label dependencies, which can achieve parallel decoding for a faster prediction. In addition, in order to mitigate the side effects of incorrect draft labels, Bayesian neural networks are used to indicate the labels with a high probability of being wrong, which can greatly assist in preventing error propagation. The experimental results on three sequence labeling benchmarks demonstrated that the proposed method not only outperformed the CRF-based methods but also greatly accelerated the inference process.
Constructing Multiple Tasks for Augmentation: Improving Neural Image Classification With K-means Features
Nov 18, 2019

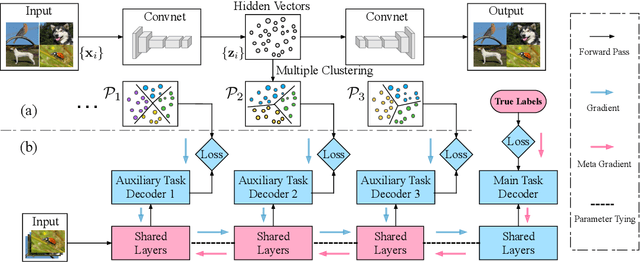

Multi-task learning (MTL) has received considerable attention, and numerous deep learning applications benefit from MTL with multiple objectives. However, constructing multiple related tasks is difficult, and sometimes only a single task is available for training in a dataset. To tackle this problem, we explored the idea of using unsupervised clustering to construct a variety of auxiliary tasks from unlabeled data or existing labeled data. We found that some of these newly constructed tasks could exhibit semantic meanings corresponding to certain human-specific attributes, but some were non-ideal. In order to effectively reduce the impact of non-ideal auxiliary tasks on the main task, we further proposed a novel meta-learning-based multi-task learning approach, which trained the shared hidden layers on auxiliary tasks, while the meta-optimization objective was to minimize the loss on the main task, ensuring that the optimizing direction led to an improvement on the main task. Experimental results across five image datasets demonstrated that the proposed method significantly outperformed existing single task learning, semi-supervised learning, and some data augmentation methods, including an improvement of more than 9% on the Omniglot dataset.