 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Task-specific Representation for Novel Words in Sequence Labeling
Paper and Code
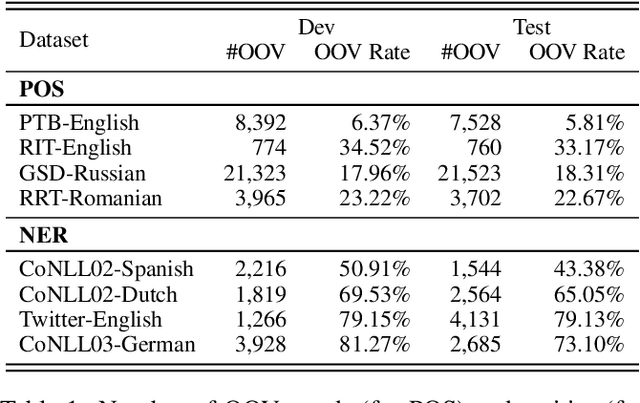
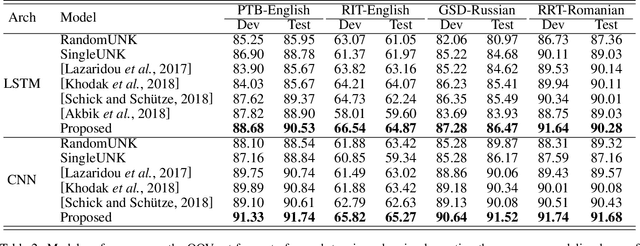
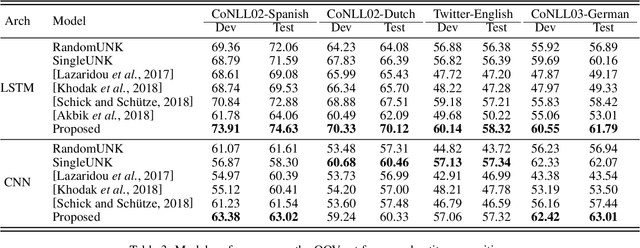
Word representation is a key component in neural-network-based sequence labeling systems. However, representations of unseen or rare words trained on the end task are usually poor for appreciable performance. This is commonly referred to as the out-of-vocabulary (OOV) problem. In this work, we address the OOV problem in sequence labeling using only training data of the task. To this end, we propose a novel method to predict representations for OOV words from their surface-forms (e.g., character sequence) and contexts. The method is specifically designed to avoid the error propagation problem suffered by existing approaches in the same paradigm. To evaluate its effectiveness, we performed extensive empirical studies on four part-of-speech tagging (POS) tasks and four named entity recognition (NER) tasks. Experimental results show that the proposed method can achieve better or competitive performance on the OOV problem compared with existing state-of-the-art methods.