 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Item Graph Enhancement for Multimodal Recommendation
Aug 08, 2025Multimodal recommendation systems have attracted increasing attention for their improved performance by leveraging items' multimodal information. Prior methods often build modality-specific item-item semantic graphs from raw modality features and use them as supplementary structures alongside the user-item interaction graph to enhance user preference learning. However, these semantic graphs suffer from semantic deficiencies, including (1) insufficient modeling of collaborative signals among items and (2) structural distortions introduced by noise in raw modality features, ultimately compromising performance. To address these issues, we first extract collaborative signals from the interaction graph and infuse them into each modality-specific item semantic graph to enhance semantic modeling. Then, we design a modulus-based personalized embedding perturbation mechanism that injects perturbations with modulus-guided personalized intensity into embeddings to generate contrastive views. This enables the model to learn noise-robust representations through contrastive learning, thereby reducing the effect of structural noise in semantic graphs. Besides, we propose a dual representation alignment mechanism that first aligns multiple semantic representations via a designed Anchor-based InfoNCE loss using behavior representations as anchors, and then aligns behavior representations with the fused semantics by standard InfoNCE, to ensure representation consistency. Extensive experiments on four benchmark datasets validate the effectiveness of our framework.
Learning Item Representations Directly from Multimodal Features for Effective Recommendation
May 08, 2025Conventional multimodal recommender systems predominantly leverage Bayesian Personalized Ranking (BPR) optimization to learn item representations by amalgamating item identity (ID) embeddings with multimodal features. Nevertheless, our empirical and theoretical findings unequivocally demonstrate a pronounced optimization gradient bias in favor of acquiring representations from multimodal features over item ID embeddings. As a consequence, item ID embeddings frequently exhibit suboptimal characteristics despite the convergence of multimodal feature parameters. Given the rich informational content inherent in multimodal features, in this paper, we propose a novel model (i.e., LIRDRec) that learns item representations directly from these features to augment recommendation performance. Recognizing that features derived from each modality may capture disparate yet correlated aspects of items, we propose a multimodal transformation mechanism, integrated with modality-specific encoders, to effectively fuse features from all modalities. Moreover, to differentiate the influence of diverse modality types, we devise a progressive weight copying fusion module within LIRDRec. This module incrementally learns the weight assigned to each modality in synthesizing the final user or item representations. Finally, we utilize the powerful visual understanding of Multimodal Large Language Models (MLLMs) to convert the item images into texts and extract semantics embeddings upon the texts via LLMs. Empirical evaluations conducted on five real-world datasets validate the superiority of our approach relative to competing baselines. It is worth noting the proposed model, equipped with embeddings extracted from MLLMs and LLMs, can further improve the recommendation accuracy of NDCG@20 by an average of 4.21% compared to the original embeddings.
Advancing Sustainability via Recommender Systems: A Survey
Nov 12, 2024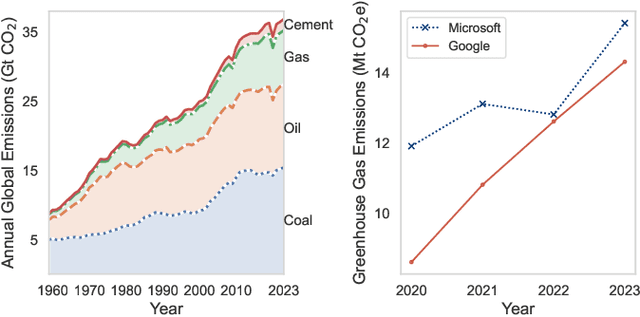
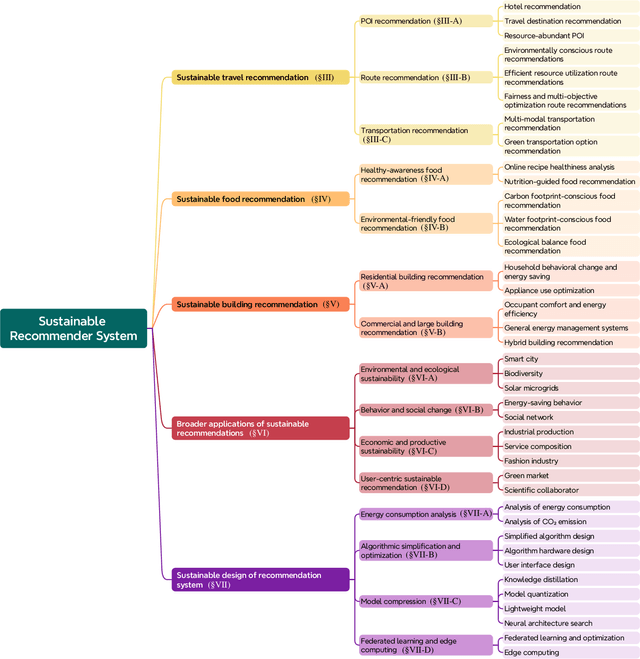
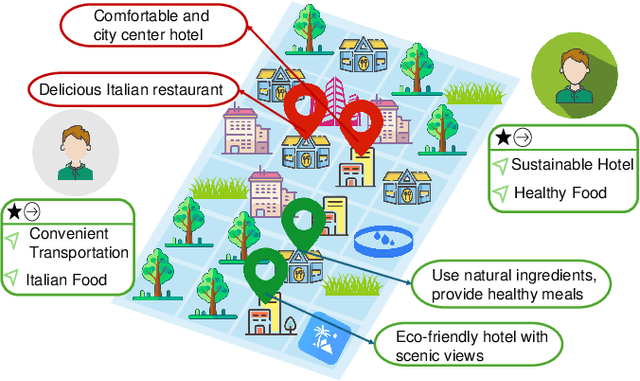
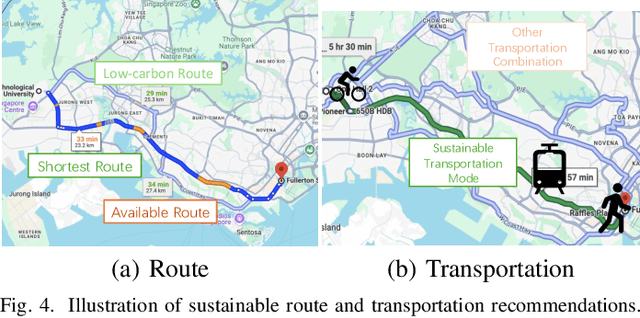
Human behavioral patterns and consumption paradigms have emerged as pivotal determinants in environmental degradation and climate change, with quotidian decisions pertaining to transportation, energy utilization, and resource consumption collectively precipitating substantial ecological impacts. Recommender systems, which generate personalized suggestions based on user preferences and historical interaction data, exert considerable influence on individual behavioral trajectories. However, conventional recommender systems predominantly optimize for user engagement and economic metrics, inadvertently neglecting the environmental and societal ramifications of their recommendations, potentially catalyzing over-consumption and reinforcing unsustainable behavioral patterns. Given their instrumental role in shaping user decisions, there exists an imperative need for sustainable recommender systems that incorporate sustainability principles to foster eco-conscious and socially responsible choices. This comprehensive survey addresses this critical research gap by presenting a systematic analysis of sustainable recommender systems. As these systems can simultaneously advance multiple sustainability objectives--including resource conservation, sustainable consumer behavior, and social impact enhancement--examining their implementations across distinct application domains provides a more rigorous analytical framework. Through a methodological analysis of domain-specific implementations encompassing transportation, food, buildings, and auxiliary sectors, we can better elucidate how these systems holistically advance sustainability objectives while addressing sector-specific constraints and opportunities. Moreover, we delineate future research directions for evolving recommender systems beyond sustainability advocacy toward fostering environmental resilience and social consciousness in society.
Low-Dimensional Federated Knowledge Graph Embedding via Knowledge Distillation
Aug 11, 2024

Federated Knowledge Graph Embedding (FKGE) aims to facilitate collaborative learning of entity and relation embeddings from distributed Knowledge Graphs (KGs) across multiple clients, while preserving data privacy. Training FKGE models with higher dimensions is typically favored due to their potential for achieving superior performance. However, high-dimensional embeddings present significant challenges in terms of storage resource and inference speed. Unlike traditional KG embedding methods, FKGE involves multiple client-server communication rounds, where communication efficiency is critical. Existing embedding compression methods for traditional KGs may not be directly applicable to FKGE as they often require multiple model trainings which potentially incur substantial communication costs. In this paper, we propose a light-weight component based on Knowledge Distillation (KD) which is titled FedKD and tailored specifically for FKGE methods. During client-side local training, FedKD facilitates the low-dimensional student model to mimic the score distribution of triples from the high-dimensional teacher model using KL divergence loss. Unlike traditional KD way, FedKD adaptively learns a temperature to scale the score of positive triples and separately adjusts the scores of corresponding negative triples using a predefined temperature, thereby mitigating teacher over-confidence issue. Furthermore, we dynamically adjust the weight of KD loss to optimize the training process. Extensive experiments on three datasets support the effectiveness of FedKD.
Communication-Efficient Federated Knowledge Graph Embedding with Entity-Wise Top-K Sparsification
Jun 19, 2024



Federated Knowledge Graphs Embedding learning (FKGE) encounters challenges in communication efficiency stemming from the considerable size of parameters and extensive communication rounds. However, existing FKGE methods only focus on reducing communication rounds by conducting multiple rounds of local training in each communication round, and ignore reducing the size of parameters transmitted within each communication round. To tackle the problem, we first find that universal reduction in embedding precision across all entities during compression can significantly impede convergence speed, underscoring the importance of maintaining embedding precision. We then propose bidirectional communication-efficient FedS based on Entity-Wise Top-K Sparsification strategy. During upload, clients dynamically identify and upload only the Top-K entity embeddings with the greater changes to the server. During download, the server first performs personalized embedding aggregation for each client. It then identifies and transmits the Top-K aggregated embeddings to each client. Besides, an Intermittent Synchronization Mechanism is used by FedS to mitigate negative effect of embedding inconsistency among shared entities of clients caused by heterogeneity of Federated Knowledge Graph. Extensive experiments across three datasets showcase that FedS significantly enhances communication efficiency with negligible (even no) performance degradation.
Personalized Federated Knowledge Graph Embedding with Client-Wise Relation Graph
Jun 17, 2024



Federated Knowledge Graph Embedding (FKGE) has recently garnered considerable interest due to its capacity to extract expressive representations from distributed knowledge graphs, while concurrently safeguarding the privacy of individual clients. Existing FKGE methods typically harness the arithmetic mean of entity embeddings from all clients as the global supplementary knowledge, and learn a replica of global consensus entities embeddings for each client. However, these methods usually neglect the inherent semantic disparities among distinct clients. This oversight not only results in the globally shared complementary knowledge being inundated with too much noise when tailored to a specific client, but also instigates a discrepancy between local and global optimization objectives. Consequently, the quality of the learned embeddings is compromised. To address this, we propose Personalized Federated knowledge graph Embedding with client-wise relation Graph (PFedEG), a novel approach that employs a client-wise relation graph to learn personalized embeddings by discerning the semantic relevance of embeddings from other clients. Specifically, PFedEG learns personalized supplementary knowledge for each client by amalgamating entity embedding from its neighboring clients based on their "affinity" on the client-wise relation graph. Each client then conducts personalized embedding learning based on its local triples and personalized supplementary knowledge. We conduct extensive experiments on four benchmark datasets to evaluate our method against state-of-the-art models and results demonstrate the superiority of our method.
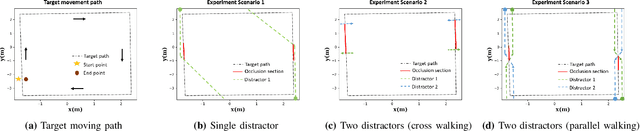
Person Monitoring by Full Body Tracking in Uniform Crowd Environment
Sep 02, 2022


Full body trackers are utilized for surveillance and security purposes, such as person-tracking robots. In the Middle East, uniform crowd environments are the norm which challenges state-of-the-art trackers. Despite tremendous improvements in tracker technology documented in the past literature, these trackers have not been trained using a dataset that captures these environments. In this work, we develop an annotated dataset with one specific target per video in a uniform crowd environment. The dataset was generated in four different scenarios where mainly the target was moving alongside the crowd, sometimes occluding with them, and other times the camera's view of the target is blocked by the crowd for a short period. After the annotations, it was used in evaluating and fine-tuning a state-of-the-art tracker. Our results have shown that the fine-tuned tracker performed better on the evaluation dataset based on two quantitative evaluation metrics, compared to the initial pre-trained tracker.
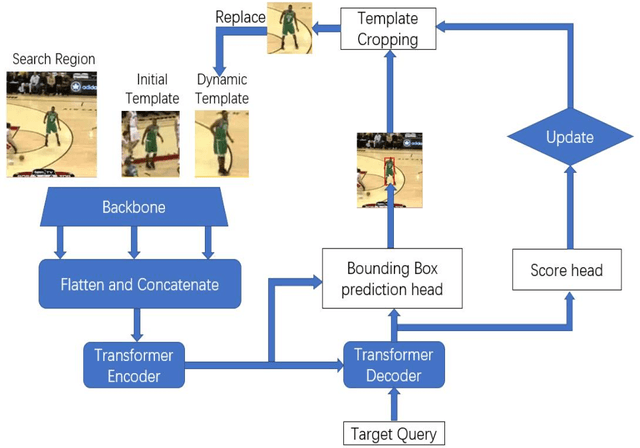
Robot Person Following in Uniform Crowd Environment
May 21, 2022
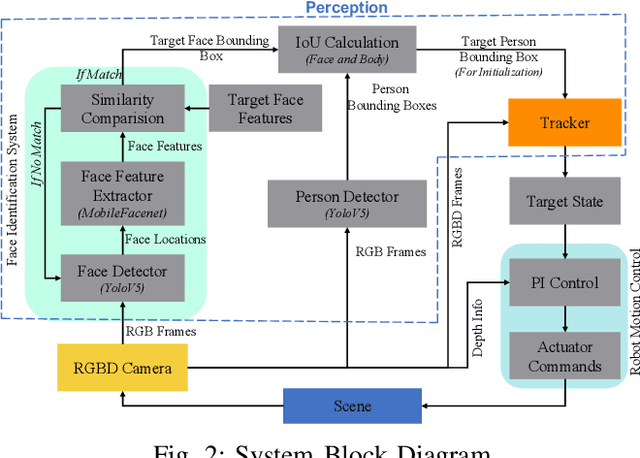
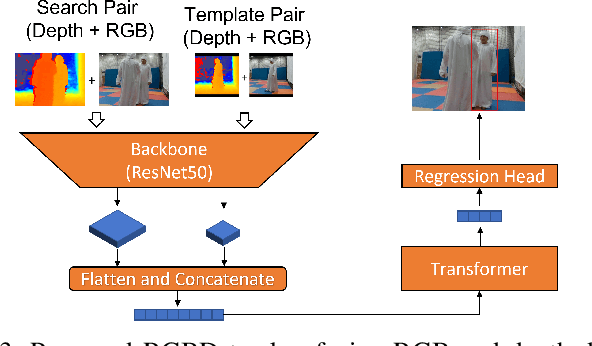
Person-tracking robots have many applications, such as in security, elderly care, and socializing robots. Such a task is particularly challenging when the person is moving in a Uniform crowd. Also, despite significant progress of trackers reported in the literature, state-of-the-art trackers have hardly addressed person following in such scenarios. In this work, we focus on improving the perceptivity of a robot for a person following task by developing a robust and real-time applicable object tracker. We present a new robot person tracking system with a new RGB-D tracker, Deep Tracking with RGB-D (DTRD) that is resilient to tricky challenges introduced by the uniform crowd environment. Our tracker utilizes transformer encoder-decoder architecture with RGB and depth information to discriminate the target person from similar distractors. A substantial amount of comprehensive experiments and results demonstrate that our tracker has higher performance in two quantitative evaluation metrics and confirms its superiority over other SOTA trackers.