 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan AI Models Appreciate Document Aesthetics? An Exploration of Legibility and Layout Quality in Relation to Prediction Confidence
Mar 27, 2024



A well-designed document communicates not only through its words but also through its visual eloquence. Authors utilize aesthetic elements such as colors, fonts, graphics, and layouts to shape the perception of information. Thoughtful document design, informed by psychological insights, enhances both the visual appeal and the comprehension of the content. While state-of-the-art document AI models demonstrate the benefits of incorporating layout and image data, it remains unclear whether the nuances of document aesthetics are effectively captured. To bridge the gap between human cognition and AI interpretation of aesthetic elements, we formulated hypotheses concerning AI behavior in document understanding tasks, specifically anchored in document design principles. With a focus on legibility and layout quality, we tested four aspects of aesthetic effects: noise, font-size contrast, alignment, and complexity, on model confidence using correlational analysis. The results and observations highlight the value of model analysis rooted in document design theories. Our work serves as a trailhead for further studies and we advocate for continued research in this topic to deepen our understanding of how AI interprets document aesthetics.
Extracting Complex Named Entities in Legal Documents via Weakly Supervised Object Detection
May 10, 2023


Accurate Named Entity Recognition (NER) is crucial for various information retrieval tasks in industry. However, despite significant progress in traditional NER methods, the extraction of Complex Named Entities remains a relatively unexplored area. In this paper, we propose a novel system that combines object detection for Document Layout Analysis (DLA) with weakly supervised learning to address the challenge of extracting discontinuous complex named entities in legal documents. Notably, to the best of our knowledge, this is the first work to apply weak supervision to DLA. Our experimental results show that the model trained solely on pseudo labels outperforms the supervised baseline when gold-standard data is limited, highlighting the effectiveness of our proposed approach in reducing the dependency on annotated data.
Aligning Cross-Lingual Entities with Multi-Aspect Information
Oct 15, 2019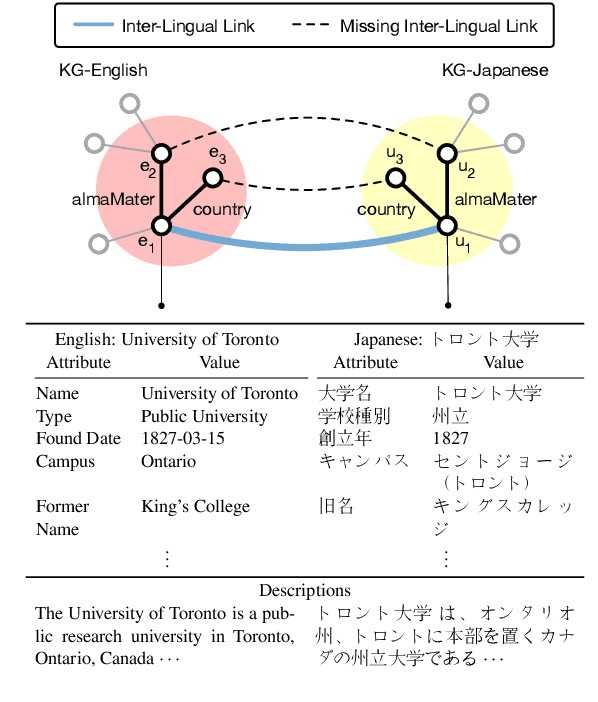

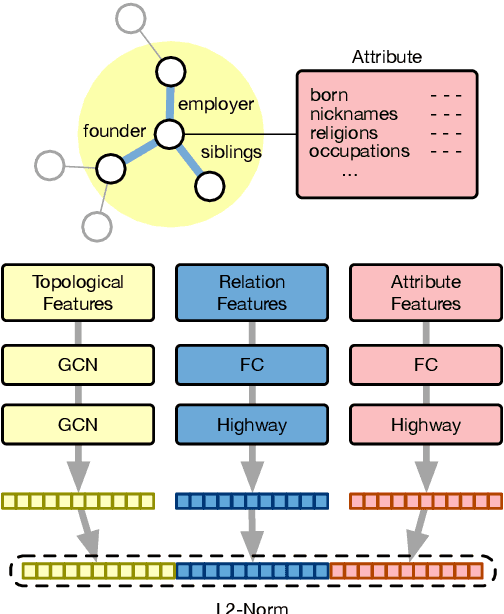

Multilingual knowledge graphs (KGs), such as YAGO and DBpedia, represent entities in different languages. The task of cross-lingual entity alignment is to match entities in a source language with their counterparts in target languages. In this work, we investigate embedding-based approaches to encode entities from multilingual KGs into the same vector space, where equivalent entities are close to each other. Specifically, we apply graph convolutional networks (GCNs) to combine multi-aspect information of entities, including topological connections, relations, and attributes of entities, to learn entity embeddings. To exploit the literal descriptions of entities expressed in different languages, we propose two uses of a pretrained multilingual BERT model to bridge cross-lingual gaps. We further propose two strategies to integrate GCN-based and BERT-based modules to boost performance. Extensive experiments on two benchmark datasets demonstrate that our method significantly outperforms existing systems.