 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDivLogicEval: A Framework for Benchmarking Logical Reasoning Evaluation in Large Language Models
Sep 19, 2025Logic reasoning in natural language has been recognized as an important measure of human intelligence for Large Language Models (LLMs). Popular benchmarks may entangle multiple reasoning skills and thus provide unfaithful evaluations on the logic reasoning skill. Meanwhile, existing logic reasoning benchmarks are limited in language diversity and their distributions are deviated from the distribution of an ideal logic reasoning benchmark, which may lead to biased evaluation results. This paper thereby proposes a new classical logic benchmark DivLogicEval, consisting of natural sentences composed of diverse statements in a counterintuitive way. To ensure a more reliable evaluation, we also introduce a new evaluation metric that mitigates the influence of bias and randomness inherent in LLMs. Through experiments, we demonstrate the extent to which logical reasoning is required to answer the questions in DivLogicEval and compare the performance of different popular LLMs in conducting logical reasoning.
The Stochastic Parrot on LLM's Shoulder: A Summative Assessment of Physical Concept Understanding
Feb 13, 2025



In a systematic way, we investigate a widely asked question: Do LLMs really understand what they say?, which relates to the more familiar term Stochastic Parrot. To this end, we propose a summative assessment over a carefully designed physical concept understanding task, PhysiCo. Our task alleviates the memorization issue via the usage of grid-format inputs that abstractly describe physical phenomena. The grids represents varying levels of understanding, from the core phenomenon, application examples to analogies to other abstract patterns in the grid world. A comprehensive study on our task demonstrates: (1) state-of-the-art LLMs, including GPT-4o, o1 and Gemini 2.0 flash thinking, lag behind humans by ~40%; (2) the stochastic parrot phenomenon is present in LLMs, as they fail on our grid task but can describe and recognize the same concepts well in natural language; (3) our task challenges the LLMs due to intrinsic difficulties rather than the unfamiliar grid format, as in-context learning and fine-tuning on same formatted data added little to their performance.
Unified Triplet-Level Hallucination Evaluation for Large Vision-Language Models
Oct 30, 2024Despite the outstanding performance in vision-language reasoning, Large Vision-Language Models (LVLMs) might generate hallucinated contents that do not exist in the given image. Most existing LVLM hallucination benchmarks are constrained to evaluate the object-related hallucinations. However, the potential hallucination on the relations between two objects, i.e., relation hallucination, still lacks investigation. To remedy that, in this paper we design a unified framework to measure object and relation hallucination in LVLMs simultaneously. The core idea of our framework is to conduct hallucination evaluation on (object, relation, object) triplets extracted from LVLMs' responses, and thus, could be easily generalized to different vision-language tasks. Based on our framework, we further introduce Tri-HE, a novel Triplet-level Hallucination Evaluation benchmark which can be used to study both object and relation hallucination at the same time. We conduct comprehensive evaluations on Tri-HE and observe that the relation hallucination issue is even more serious than object hallucination among existing LVLMs, highlighting a previously neglected problem towards reliable LVLMs. Moreover, based on our findings, we design a simple yet effective training-free approach to mitigate hallucinations for LVLMs, with which, we exceed all open-sourced counterparts on Tri-HE, achieving comparable performance with the powerful GPT-4V. Our dataset and code for the reproduction of our experiments are available publicly at https://github.com/wujunjie1998/Tri-HE.
Selection-p: Self-Supervised Task-Agnostic Prompt Compression for Faithfulness and Transferability
Oct 15, 2024
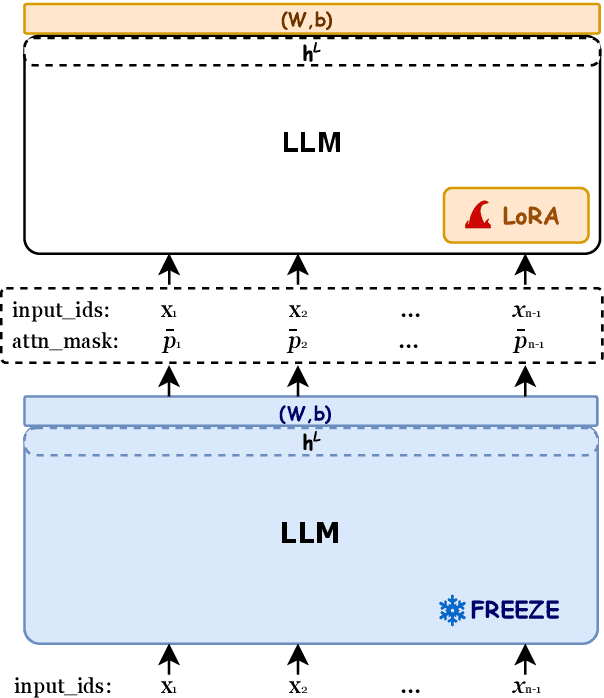


Large Language Models (LLMs) have demonstrated impressive capabilities in a wide range of natural language processing tasks when leveraging in-context learning. To mitigate the additional computational and financial costs associated with in-context learning, several prompt compression methods have been proposed to compress the in-context learning prompts. Despite their success, these methods face challenges with transferability due to model-specific compression, or rely on external training data, such as GPT-4. In this paper, we investigate the ability of LLMs to develop a unified compression method that discretizes uninformative tokens, utilizing a self-supervised pre-training technique. By introducing a small number of parameters during the continual pre-training, the proposed Selection-p produces a probability for each input token, indicating whether to preserve or discard it. Experiments show Selection-p achieves state-of-the-art performance across numerous classification tasks, achieving compression rates of up to 10 times while experiencing only a marginal 0.8% decrease in performance. Moreover, it exhibits superior transferability to different models compared to prior work. Additionally, we further analyze how Selection-p helps maintain performance on in-context learning with long contexts.