 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAC/DC: LLM-based Audio Comprehension via Dialogue Continuation
Jun 12, 2025We propose an instruction-following audio comprehension model that leverages the dialogue continuation ability of large language models (LLMs). Instead of directly generating target captions in training data, the proposed method trains a model to produce responses as if the input caption triggered a dialogue. This dialogue continuation training mitigates the caption variation problem. Learning to continue a dialogue effectively captures the caption's meaning beyond its surface-level words. As a result, our model enables zero-shot instruction-following capability without multitask instruction tuning, even trained solely on audio captioning datasets. Experiments on AudioCaps, WavCaps, and Clotho datasets with AudioBench audio-scene question-answering tests demonstrate our model's ability to follow various unseen instructions.
OWSM-Biasing: Contextualizing Open Whisper-Style Speech Models for Automatic Speech Recognition with Dynamic Vocabulary
Jun 11, 2025



Speech foundation models (SFMs), such as Open Whisper-Style Speech Models (OWSM), are trained on massive datasets to achieve accurate automatic speech recognition. However, even SFMs struggle to accurately recognize rare and unseen words. While contextual biasing (CB) is a promising approach to improve recognition of such words, most CB methods are trained from scratch, resulting in lower performance than SFMs due to the lack of pre-trained knowledge. This paper integrates an existing CB method with OWSM v3.1 while freezing its pre-trained parameters. By leveraging the knowledge embedded in SFMs, the proposed method enables effective CB while preserving the advantages of SFMs, even with a small dataset. Experimental results show that the proposed method improves the biasing word error rate (B-WER) by 11.6 points, resulting in a 0.9 point improvement in the overall WER while reducing the real-time factor by 7.5% compared to the non-biasing baseline on the LibriSpeech 100 test-clean set.
Contextualized End-to-end Automatic Speech Recognition with Intermediate Biasing Loss
Jun 23, 2024



Contextualized end-to-end automatic speech recognition has been an active research area, with recent efforts focusing on the implicit learning of contextual phrases based on the final loss objective. However, these approaches ignore the useful contextual knowledge encoded in the intermediate layers. We hypothesize that employing explicit biasing loss as an auxiliary task in the encoder intermediate layers may better align text tokens or audio frames with the desired objectives. Our proposed intermediate biasing loss brings more regularization and contextualization to the network. Our method outperforms a conventional contextual biasing baseline on the LibriSpeech corpus, achieving a relative improvement of 22.5% in biased word error rate (B-WER) and up to 44% compared to the non-contextual baseline with a biasing list size of 100. Moreover, employing RNN-transducer-driven joint decoding further reduces the unbiased word error rate (U-WER), resulting in a more robust network.
4D ASR: Joint Beam Search Integrating CTC, Attention, Transducer, and Mask Predict Decoders
Jun 05, 2024



End-to-end automatic speech recognition (E2E-ASR) can be classified into several network architectures, such as connectionist temporal classification (CTC), recurrent neural network transducer (RNN-T), attention-based encoder-decoder, and mask-predict models. Each network architecture has advantages and disadvantages, leading practitioners to switch between these different models depending on application requirements. Instead of building separate models, we propose a joint modeling scheme where four decoders (CTC, RNN-T, attention, and mask-predict) share the same encoder -- we refer to this as 4D modeling. The 4D model is trained using multitask learning, which will bring model regularization and maximize the model robustness thanks to their complementary properties. To efficiently train the 4D model, we introduce a two-stage training strategy that stabilizes multitask learning. In addition, we propose three novel one-pass beam search algorithms by combining three decoders (CTC, RNN-T, and attention) to further improve performance. These three beam search algorithms differ in which decoder is used as the primary decoder. We carefully evaluate the performance and computational tradeoffs associated with each algorithm. Experimental results demonstrate that the jointly trained 4D model outperforms the E2E-ASR models trained with only one individual decoder. Furthermore, we demonstrate that the proposed one-pass beam search algorithm outperforms the previously proposed CTC/attention decoding.
Joint Optimization of Streaming and Non-Streaming Automatic Speech Recognition with Multi-Decoder and Knowledge Distillation
May 22, 2024



End-to-end (E2E) automatic speech recognition (ASR) can operate in two modes: streaming and non-streaming, each with its pros and cons. Streaming ASR processes the speech frames in real-time as it is being received, while non-streaming ASR waits for the entire speech utterance; thus, professionals may have to operate in either mode to satisfy their application. In this work, we present joint optimization of streaming and non-streaming ASR based on multi-decoder and knowledge distillation. Primarily, we study 1) the encoder integration of these ASR modules, followed by 2) separate decoders to make the switching mode flexible, and enhancing performance by 3) incorporating similarity-preserving knowledge distillation between the two modular encoders and decoders. Evaluation results show 2.6%-5.3% relative character error rate reductions (CERR) on CSJ for streaming ASR, and 8.3%-9.7% relative CERRs for non-streaming ASR within a single model compared to multiple standalone modules.
OWSM-CTC: An Open Encoder-Only Speech Foundation Model for Speech Recognition, Translation, and Language Identification
Feb 20, 2024



There has been an increasing interest in large speech models that can perform multiple speech processing tasks in a single model. Such models usually adopt the encoder-decoder or decoder-only architecture due to their popularity and good performance in many domains. However, autoregressive models can be slower during inference compared to non-autoregressive models and also have potential risks of hallucination. Though prior studies observed promising results of non-autoregressive models for certain tasks at small scales, it remains unclear if they can be scaled to speech-to-text generation in diverse languages and tasks. Inspired by the Open Whisper-style Speech Model (OWSM) project, we propose OWSM-CTC, a novel encoder-only speech foundation model based on Connectionist Temporal Classification (CTC). It is trained on 180k hours of public audio data for multilingual automatic speech recognition (ASR), speech translation (ST), and language identification (LID). Compared to encoder-decoder OWSM, our OWSM-CTC achieves competitive results on ASR and up to 25% relative improvement on ST, while it is more robust and 3 to 4 times faster for inference. OWSM-CTC also improves the long-form ASR result with 20x speed-up. We will publicly release our codebase, pre-trained model, and training logs to promote open science in speech foundation models.
OWSM v3.1: Better and Faster Open Whisper-Style Speech Models based on E-Branchformer
Jan 30, 2024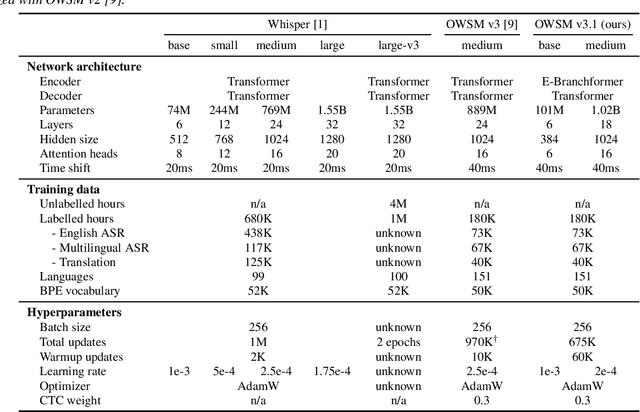
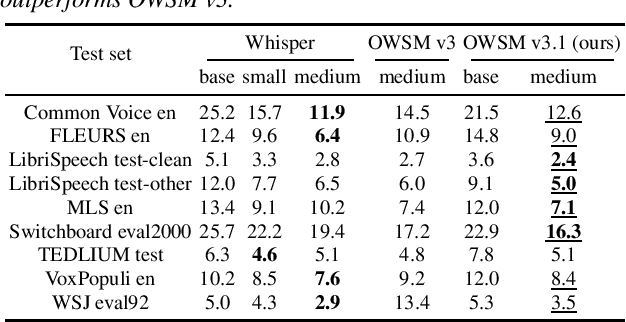
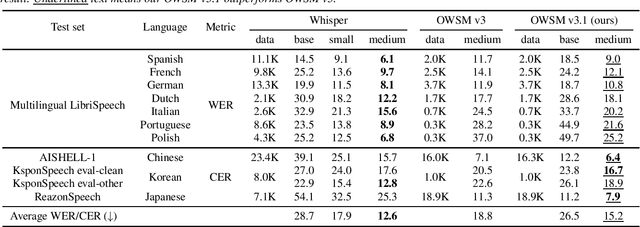
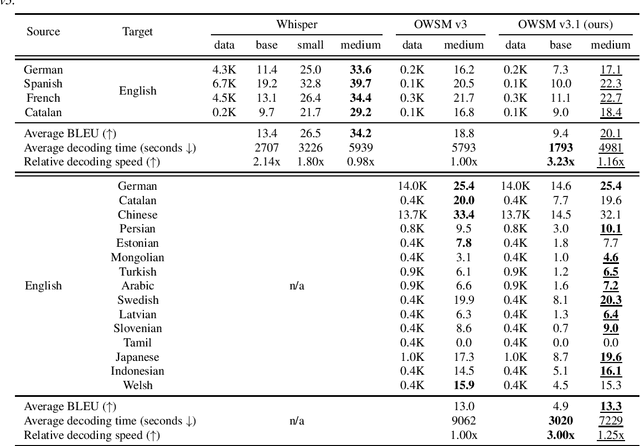
Recent studies have advocated for fully open foundation models to promote transparency and open science. As an initial step, the Open Whisper-style Speech Model (OWSM) reproduced OpenAI's Whisper using publicly available data and open-source toolkits. With the aim of reproducing Whisper, the previous OWSM v1 through v3 models were still based on Transformer, which might lead to inferior performance compared to other state-of-the-art speech encoders. In this work, we aim to improve the performance and efficiency of OWSM without extra training data. We present E-Branchformer based OWSM v3.1 models at two scales, i.e., 100M and 1B. The 1B model is the largest E-Branchformer based speech model that has been made publicly available. It outperforms the previous OWSM v3 in a vast majority of evaluation benchmarks, while demonstrating up to 25% faster inference speed. We publicly release the data preparation scripts, pre-trained models and training logs.
Contextualized Automatic Speech Recognition with Attention-Based Bias Phrase Boosted Beam Search
Jan 19, 2024



End-to-end (E2E) automatic speech recognition (ASR) methods exhibit remarkable performance. However, since the performance of such methods is intrinsically linked to the context present in the training data, E2E-ASR methods do not perform as desired for unseen user contexts (e.g., technical terms, personal names, and playlists). Thus, E2E-ASR methods must be easily contextualized by the user or developer. This paper proposes an attention-based contextual biasing method that can be customized using an editable phrase list (referred to as a bias list). The proposed method can be trained effectively by combining a bias phrase index loss and special tokens to detect the bias phrases in the input speech data. In addition, to improve the contextualization performance during inference further, we propose a bias phrase boosted (BPB) beam search algorithm based on the bias phrase index probability. Experimental results demonstrate that the proposed method consistently improves the word error rate and the character error rate of the target phrases in the bias list on both the Librispeech-960 (English) and our in-house (Japanese) dataset, respectively.
Reproducing Whisper-Style Training Using an Open-Source Toolkit and Publicly Available Data
Oct 02, 2023Pre-training speech models on large volumes of data has achieved remarkable success. OpenAI Whisper is a multilingual multitask model trained on 680k hours of supervised speech data. It generalizes well to various speech recognition and translation benchmarks even in a zero-shot setup. However, the full pipeline for developing such models (from data collection to training) is not publicly accessible, which makes it difficult for researchers to further improve its performance and address training-related issues such as efficiency, robustness, fairness, and bias. This work presents an Open Whisper-style Speech Model (OWSM), which reproduces Whisper-style training using an open-source toolkit and publicly available data. OWSM even supports more translation directions and can be more efficient to train. We will publicly release all scripts used for data preparation, training, inference, and scoring as well as pre-trained models and training logs to promote open science.
Retraining-free Customized ASR for Enharmonic Words Based on a Named-Entity-Aware Model and Phoneme Similarity Estimation
May 29, 2023



End-to-end automatic speech recognition (E2E-ASR) has the potential to improve performance, but a specific issue that needs to be addressed is the difficulty it has in handling enharmonic words: named entities (NEs) with the same pronunciation and part of speech that are spelled differently. This often occurs with Japanese personal names that have the same pronunciation but different Kanji characters. Since such NE words tend to be important keywords, ASR easily loses user trust if it misrecognizes them. To solve these problems, this paper proposes a novel retraining-free customized method for E2E-ASRs based on a named-entity-aware E2E-ASR model and phoneme similarity estimation. Experimental results show that the proposed method improves the target NE character error rate by 35.7% on average relative to the conventional E2E-ASR model when selecting personal names as a target NE.