 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study of Contextual Data Augmentation for Japanese Zero Anaphora Resolution
Paper and Code
Nov 04, 2020
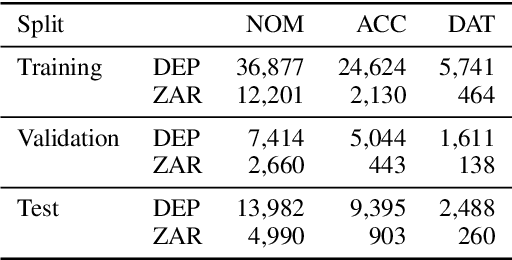
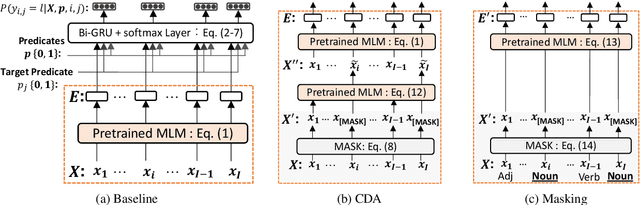
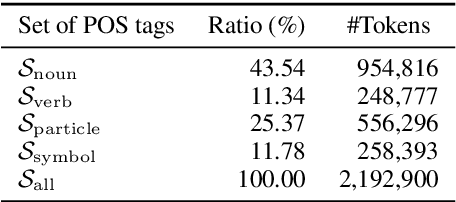
One critical issue of zero anaphora resolution (ZAR) is the scarcity of labeled data. This study explores how effectively this problem can be alleviated by data augmentation. We adopt a state-of-the-art data augmentation method, called the contextual data augmentation (CDA), that generates labeled training instances using a pretrained language model. The CDA has been reported to work well for several other natural language processing tasks, including text classification and machine translation. This study addresses two underexplored issues on CDA, that is, how to reduce the computational cost of data augmentation and how to ensure the quality of the generated data. We also propose two methods to adapt CDA to ZAR: [MASK]-based augmentation and linguistically-controlled masking. Consequently, the experimental results on Japanese ZAR show that our methods contribute to both the accuracy gain and the computation cost reduction. Our closer analysis reveals that the proposed method can improve the quality of the augmented training data when compared to the conventional CDA.