 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Layer Normalizations and Residual Connections in Transformers
Paper and Code
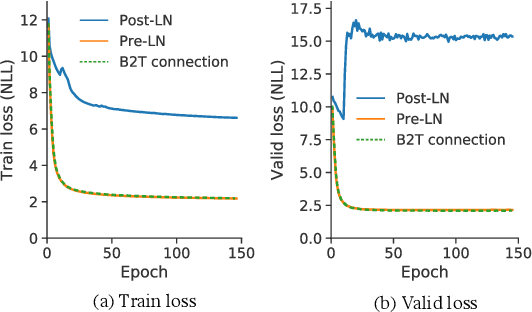
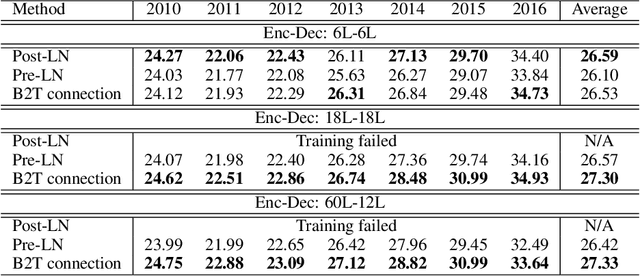
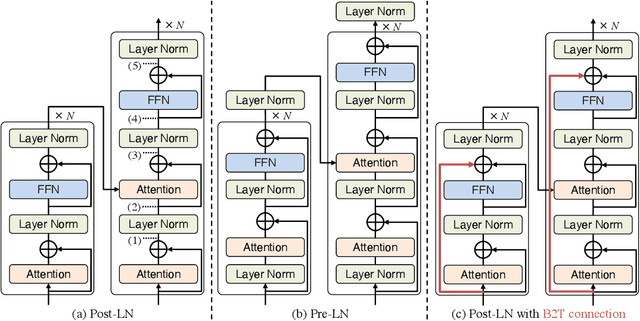
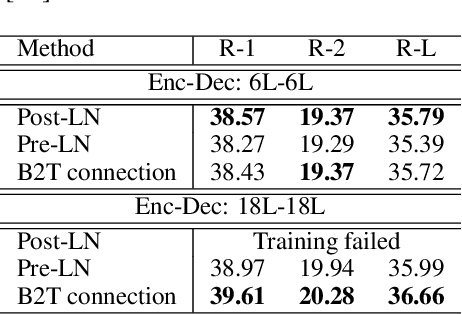
In the perspective of a layer normalization (LN) position, the architecture of Transformers can be categorized into two types: Post-LN and Pre-LN. Recent Transformers prefer to select Pre-LN because the training in Post-LN with deep Transformers, e.g., ten or more layers, often becomes unstable, resulting in useless models. However, in contrast, Post-LN has also consistently achieved better performance than Pre-LN in relatively shallow Transformers, e.g., six or fewer layers. This study first investigates the reason for these discrepant observations empirically and theoretically and discovers 1, the LN in Post-LN is the source of the vanishing gradient problem that mainly leads the unstable training whereas Pre-LN prevents it, and 2, Post-LN tends to preserve larger gradient norms in higher layers during the back-propagation that may lead an effective training. Exploiting the new findings, we propose a method that can equip both higher stability and effective training by a simple modification from Post-LN. We conduct experiments on a wide range of text generation tasks and demonstrate that our method outperforms Pre-LN, and stable training regardless of the shallow or deep layer settings.