 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Pin-Array Structure for Gripping and Shape Recognition of Convex and Concave Terrain Profiles
Jan 13, 2026This paper presents a gripper capable of grasping and recognizing terrain shapes for mobile robots in extreme environments. Multi-limbed climbing robots with grippers are effective on rough terrains, such as cliffs and cave walls. However, such robots may fall over by misgrasping the surface or getting stuck owing to the loss of graspable points in unknown natural environments. To overcome these issues, we need a gripper capable of adaptive grasping to irregular terrains, not only for grasping but also for measuring the shape of the terrain surface accurately. We developed a gripper that can grasp both convex and concave terrains and simultaneously measure the terrain shape by introducing a pin-array structure. We demonstrated the mechanism of the gripper and evaluated its grasping and terrain recognition performance using a prototype. Moreover, the proposed pin-array design works well for 3D terrain mapping as well as adaptive grasping for irregular terrains.
Scaling Laws for Upcycling Mixture-of-Experts Language Models
Feb 05, 2025



Pretraining large language models (LLMs) is resource-intensive, often requiring months of training time even with high-end GPU clusters. There are two approaches of mitigating such computational demands: reusing smaller models to train larger ones (upcycling), and training computationally efficient models like mixture-of-experts (MoE). In this paper, we study the upcycling of LLMs to MoE models, of which the scaling behavior remains underexplored. Through extensive experiments, we identify empirical scaling laws that describe how performance depends on dataset size and model configuration. Particularly, we show that, while scaling these factors improves performance, there is a novel interaction term between the dense and upcycled training dataset that limits the efficiency of upcycling at large computational budgets. Based on these findings, we provide guidance to scale upcycling, and establish conditions under which upcycling outperforms from-scratch trainings within budget constraints.
Large Vocabulary Size Improves Large Language Models
Jun 24, 2024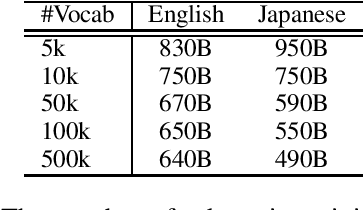
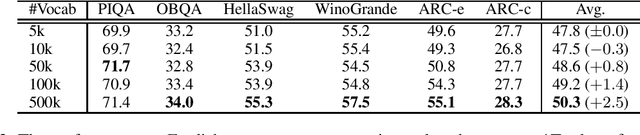
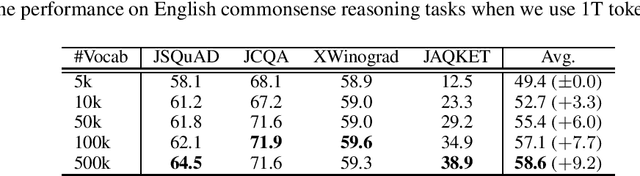

This paper empirically investigates the relationship between subword vocabulary size and the performance of large language models (LLMs) to provide insights on how to define the vocabulary size. Experimental results show that larger vocabulary sizes lead to better performance in LLMs. Moreover, we consider a continual training scenario where a pre-trained language model is trained on a different target language. We introduce a simple method to use a new vocabulary instead of the pre-defined one. We show that using the new vocabulary outperforms the model with the vocabulary used in pre-training.
Lower Gravity Demonstratable Testbed for Space Robot Experiments
Sep 19, 2023


In developing mobile robots for exploration on the planetary surface, it is crucial to evaluate the robot's performance, demonstrating the harsh environment in which the robot will actually be deployed. Repeatable experiments in a controlled testing environment that can reproduce various terrain and gravitational conditions are essential. This paper presents the development of a minimal and space-saving indoor testbed, which can simulate steep slopes, uneven terrain, and lower gravity, employing a three-dimensional target tracking mechanism (active xy and passive z) with a counterweight.
Decreasing the size of the Restricted Boltzmann machine
Jul 09, 2018We propose a method to decrease the number of hidden units of the restricted Boltzmann machine while avoiding decrease of the performance measured by the Kullback-Leibler divergence. Then, we demonstrate our algorithm by using numerical simulations.